 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixPE: Quantization and Hardware Co-design for Efficient LLM Inference
Nov 25, 2024Transformer-based large language models (LLMs) have achieved remarkable success as model sizes continue to grow, yet their deployment remains challenging due to significant computational and memory demands. Quantization has emerged as a promising solution, and state-of-the-art quantization algorithms for LLMs introduce the need for mixed-precision matrix multiplication (mpGEMM), where lower-precision weights are multiplied with higher-precision activations. Despite its benefits, current hardware accelerators such as GPUs and TPUs lack native support for efficient mpGEMM, leading to inefficient dequantization operations in the main sequential loop. To address this limitation, we introduce MixPE, a specialized mixed-precision processing element designed for efficient low-bit quantization in LLM inference. MixPE leverages two key innovations to minimize dequantization overhead and unlock the full potential of low-bit quantization. First, recognizing that scale and zero point are shared within each quantization group, we propose performing dequantization after per-group mpGEMM, significantly reducing dequantization overhead. Second, instead of relying on conventional multipliers, MixPE utilizes efficient shift\&add operations for multiplication, optimizing both computation and energy efficiency. Our experimental results demonstrate that MixPE surpasses the state-of-the-art quantization accelerators by $2.6\times$ speedup and $1.4\times$ energy reduction.
FlatQuant: Flatness Matters for LLM Quantization
Oct 12, 2024



Recently, quantization has been widely used for the compression and acceleration of large language models~(LLMs). Due to the outliers in LLMs, it is crucial to flatten weights and activations to minimize quantization error with the equally spaced quantization points. Prior research explores various pre-quantization transformations to suppress outliers, such as per-channel scaling and Hadamard transformation. However, we observe that these transformed weights and activations can still remain steep and outspread. In this paper, we propose FlatQuant (Fast and Learnable Affine Transformation), a new post-training quantization approach to enhance flatness of weights and activations. Our approach identifies optimal affine transformations tailored to each linear layer, calibrated in hours via a lightweight objective. To reduce runtime overhead, we apply Kronecker decomposition to the transformation matrices, and fuse all operations in FlatQuant into a single kernel. Extensive experiments show that FlatQuant sets up a new state-of-the-art quantization benchmark. For instance, it achieves less than $\textbf{1}\%$ accuracy drop for W4A4 quantization on the LLaMA-3-70B model, surpassing SpinQuant by $\textbf{7.5}\%$. For inference latency, FlatQuant reduces the slowdown induced by pre-quantization transformation from 0.26x of QuaRot to merely $\textbf{0.07x}$, bringing up to $\textbf{2.3x}$ speedup for prefill and $\textbf{1.7x}$ speedup for decoding, respectively. Code is available at: \url{https://github.com/ruikangliu/FlatQuant}.
Mathematical Challenges in Deep Learning
Mar 24, 2023



Deep models are dominating the artificial intelligence (AI) industry since the ImageNet challenge in 2012. The size of deep models is increasing ever since, which brings new challenges to this field with applications in cell phones, personal computers, autonomous cars, and wireless base stations. Here we list a set of problems, ranging from training, inference, generalization bound, and optimization with some formalism to communicate these challenges with mathematicians, statisticians, and theoretical computer scientists. This is a subjective view of the research questions in deep learning that benefits the tech industry in long run.
Conformalized Fairness via Quantile Regression
Oct 05, 2022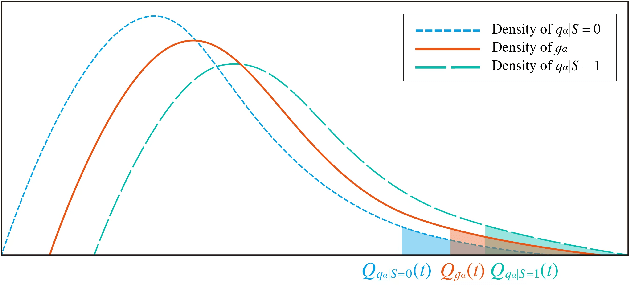
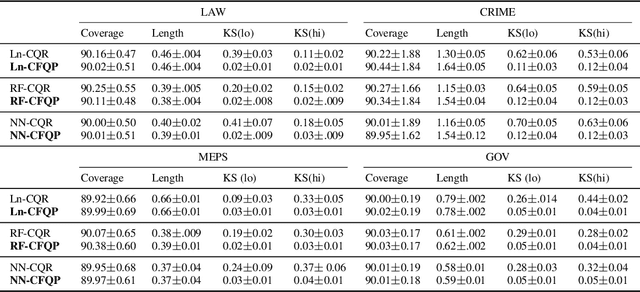
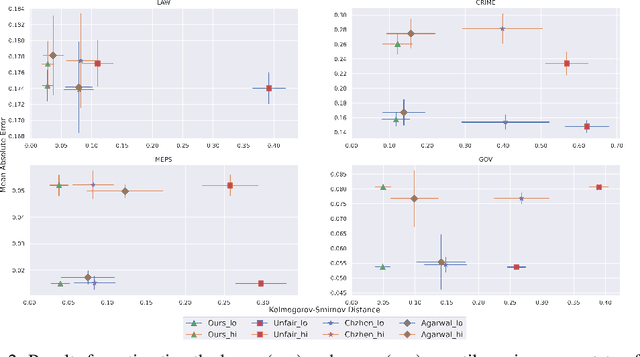
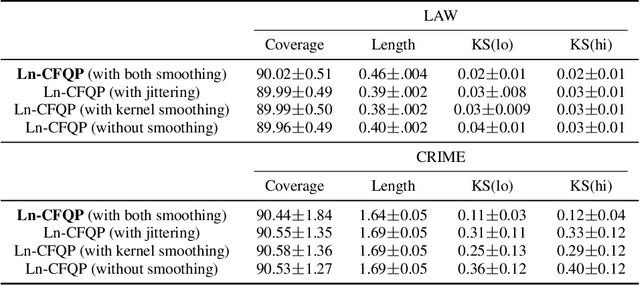
Algorithmic fairness has received increased attention in socially sensitive domains. While rich literature on mean fairness has been established, research on quantile fairness remains sparse but vital. To fulfill great needs and advocate the significance of quantile fairness, we propose a novel framework to learn a real-valued quantile function under the fairness requirement of Demographic Parity with respect to sensitive attributes, such as race or gender, and thereby derive a reliable fair prediction interval. Using optimal transport and functional synchronization techniques, we establish theoretical guarantees of distribution-free coverage and exact fairness for the induced prediction interval constructed by fair quantiles. A hands-on pipeline is provided to incorporate flexible quantile regressions with an efficient fairness adjustment post-processing algorithm. We demonstrate the superior empirical performance of this approach on several benchmark datasets. Our results show the model's ability to uncover the mechanism underlying the fairness-accuracy trade-off in a wide range of societal and medical applications.
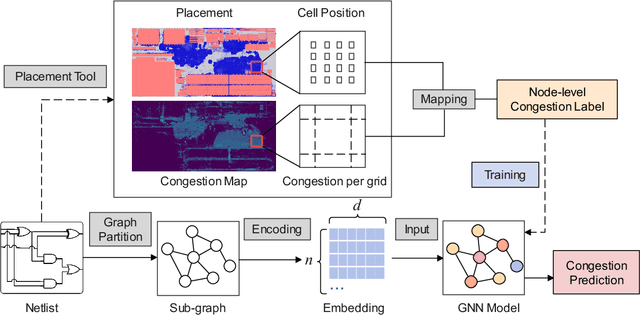
LHNN: Lattice Hypergraph Neural Network for VLSI Congestion Prediction
Mar 24, 2022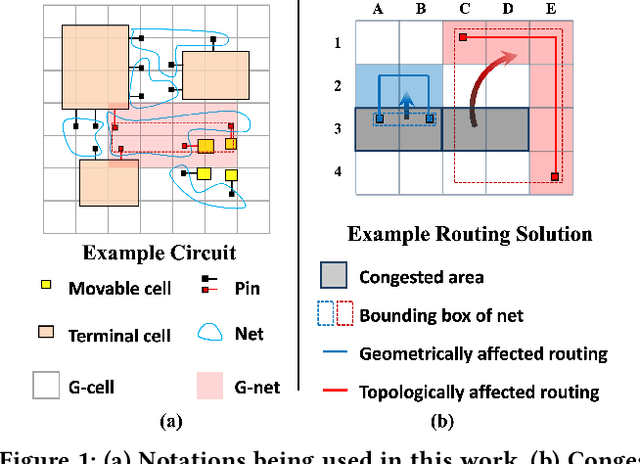
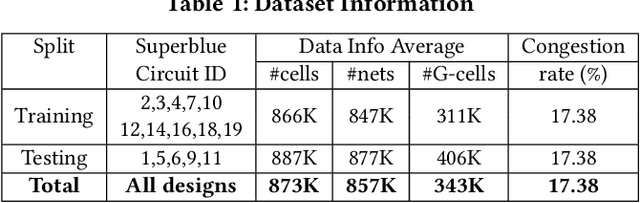
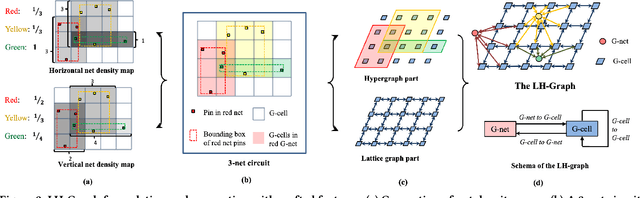
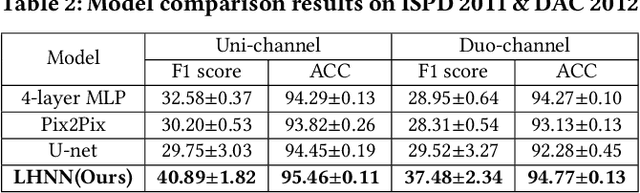
Precise congestion prediction from a placement solution plays a crucial role in circuit placement. This work proposes the lattice hypergraph (LH-graph), a novel graph formulation for circuits, which preserves netlist data during the whole learning process, and enables the congestion information propagated geometrically and topologically. Based on the formulation, we further developed a heterogeneous graph neural network architecture LHNN, jointing the routing demand regression to support the congestion spot classification. LHNN constantly achieves more than 35% improvements compared with U-nets and Pix2Pix on the F1 score. We expect our work shall highlight essential procedures using machine learning for congestion prediction.
Neuro-Symbolic Hierarchical Rule Induction
Dec 26, 2021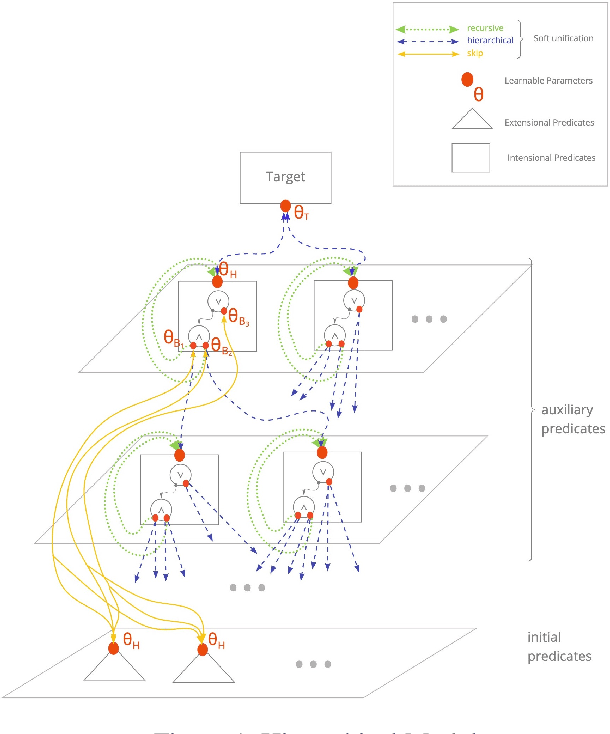
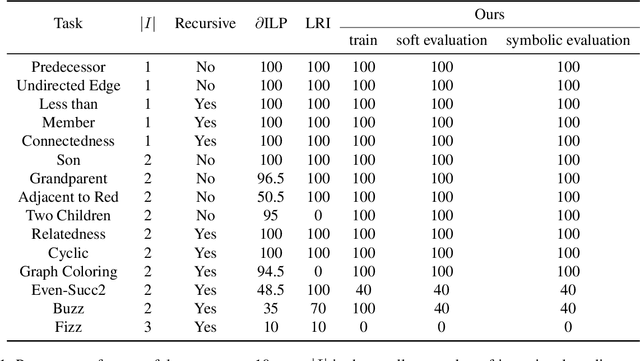
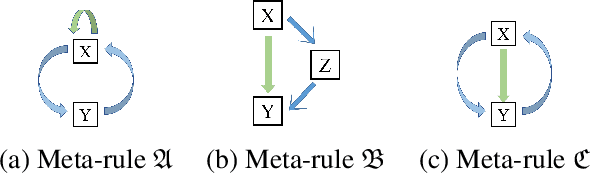
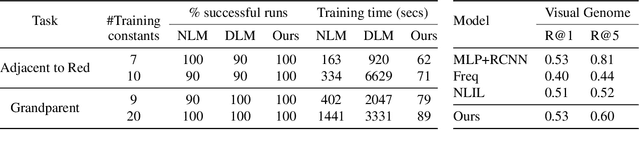
We propose an efficient interpretable neuro-symbolic model to solve Inductive Logic Programming (ILP) problems. In this model, which is built from a set of meta-rules organised in a hierarchical structure, first-order rules are invented by learning embeddings to match facts and body predicates of a meta-rule. To instantiate it, we specifically design an expressive set of generic meta-rules, and demonstrate they generate a consequent fragment of Horn clauses. During training, we inject a controlled \pw{Gumbel} noise to avoid local optima and employ interpretability-regularization term to further guide the convergence to interpretable rules. We empirically validate our model on various tasks (ILP, visual genome, reinforcement learning) against several state-of-the-art methods.
A Survey on Interpretable Reinforcement Learning
Dec 24, 2021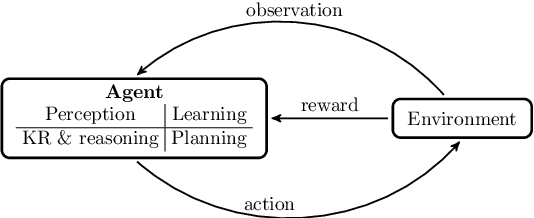
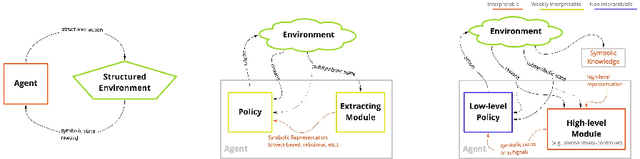

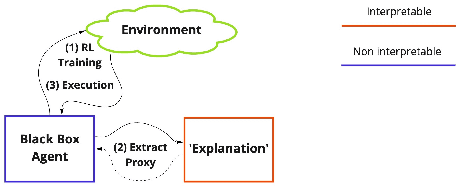
Although deep reinforcement learning has become a promising machine learning approach for sequential decision-making problems, it is still not mature enough for high-stake domains such as autonomous driving or medical applications. In such contexts, a learned policy needs for instance to be interpretable, so that it can be inspected before any deployment (e.g., for safety and verifiability reasons). This survey provides an overview of various approaches to achieve higher interpretability in reinforcement learning (RL). To that aim, we distinguish interpretability (as a property of a model) and explainability (as a post-hoc operation, with the intervention of a proxy) and discuss them in the context of RL with an emphasis on the former notion. In particular, we argue that interpretable RL may embrace different facets: interpretable inputs, interpretable (transition/reward) models, and interpretable decision-making. Based on this scheme, we summarize and analyze recent work related to interpretable RL with an emphasis on papers published in the past 10 years. We also discuss briefly some related research areas and point to some potential promising research directions.
Generalizable Cross-Graph Embedding for GNN-based Congestion Prediction
Nov 10, 2021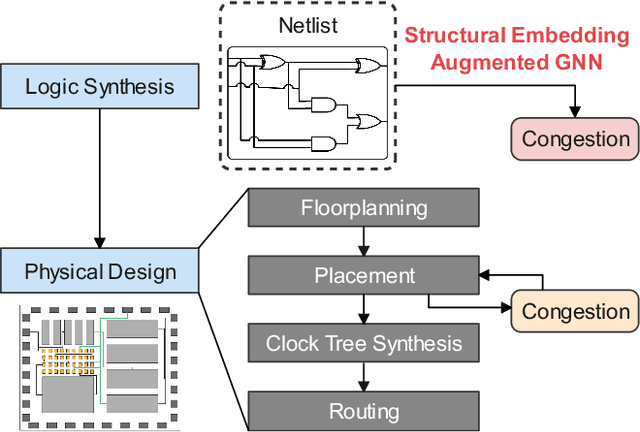
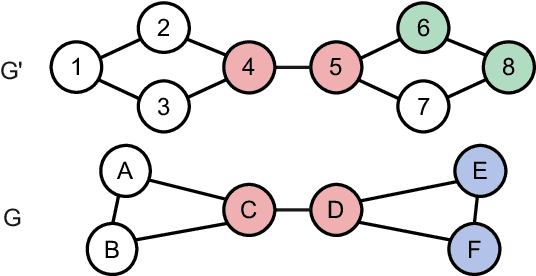
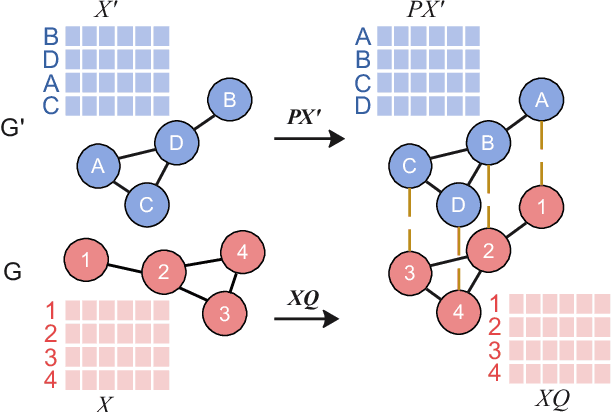
Presently with technology node scaling, an accurate prediction model at early design stages can significantly reduce the design cycle. Especially during logic synthesis, predicting cell congestion due to improper logic combination can reduce the burden of subsequent physical implementations. There have been attempts using Graph Neural Network (GNN) techniques to tackle congestion prediction during the logic synthesis stage. However, they require informative cell features to achieve reasonable performance since the core idea of GNNs is built on the message passing framework, which would be impractical at the early logic synthesis stage. To address this limitation, we propose a framework that can directly learn embeddings for the given netlist to enhance the quality of our node features. Popular random-walk based embedding methods such as Node2vec, LINE, and DeepWalk suffer from the issue of cross-graph alignment and poor generalization to unseen netlist graphs, yielding inferior performance and costing significant runtime. In our framework, we introduce a superior alternative to obtain node embeddings that can generalize across netlist graphs using matrix factorization methods. We propose an efficient mini-batch training method at the sub-graph level that can guarantee parallel training and satisfy the memory restriction for large-scale netlists. We present results utilizing open-source EDA tools such as DREAMPLACE and OPENROAD frameworks on a variety of openly available circuits. By combining the learned embedding on top of the netlist with the GNNs, our method improves prediction performance, generalizes to new circuit lines, and is efficient in training, potentially saving over $90 \%$ of runtime.
Reinforcement Learning based Negotiation-aware Motion Planning of Autonomous Vehicles
Jul 08, 2021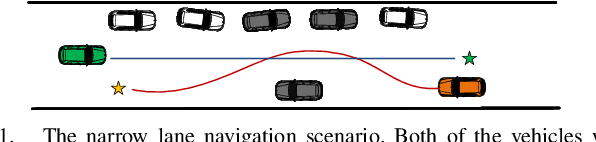
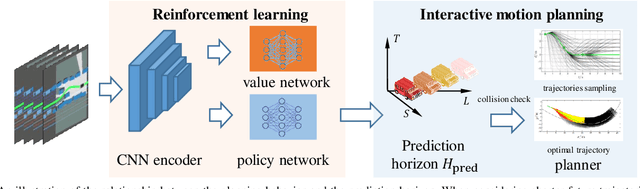
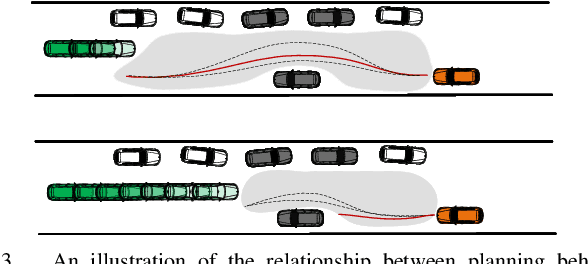
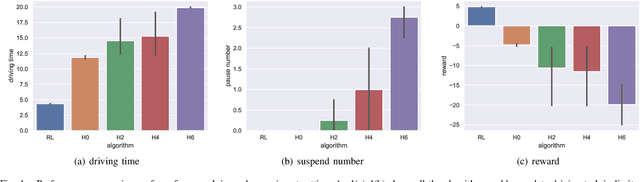
For autonomous vehicles integrating onto roadways with human traffic participants, it requires understanding and adapting to the participants' intention and driving styles by responding in predictable ways without explicit communication. This paper proposes a reinforcement learning based negotiation-aware motion planning framework, which adopts RL to adjust the driving style of the planner by dynamically modifying the prediction horizon length of the motion planner in real time adaptively w.r.t the event of a change in environment, typically triggered by traffic participants' switch of intents with different driving styles. The framework models the interaction between the autonomous vehicle and other traffic participants as a Markov Decision Process. A temporal sequence of occupancy grid maps are taken as inputs for RL module to embed an implicit intention reasoning. Curriculum learning is employed to enhance the training efficiency and the robustness of the algorithm. We applied our method to narrow lane navigation in both simulation and real world to demonstrate that the proposed method outperforms the common alternative due to its advantage in alleviating the social dilemma problem with proper negotiation skills.
$S^3$: Sign-Sparse-Shift Reparametrization for Effective Training of Low-bit Shift Networks
Jul 07, 2021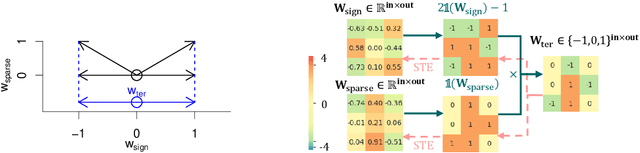



Shift neural networks reduce computation complexity by removing expensive multiplication operations and quantizing continuous weights into low-bit discrete values, which are fast and energy efficient compared to conventional neural networks. However, existing shift networks are sensitive to the weight initialization, and also yield a degraded performance caused by vanishing gradient and weight sign freezing problem. To address these issues, we propose S low-bit re-parameterization, a novel technique for training low-bit shift networks. Our method decomposes a discrete parameter in a sign-sparse-shift 3-fold manner. In this way, it efficiently learns a low-bit network with a weight dynamics similar to full-precision networks and insensitive to weight initialization. Our proposed training method pushes the boundaries of shift neural networks and shows 3-bit shift networks out-performs their full-precision counterparts in terms of top-1 accuracy on ImageNet.