 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGS-Octree: Octree-based 3D Gaussian Splatting for Robust Object-level 3D Reconstruction Under Strong Lighting
Jun 26, 2024



The 3D Gaussian Splatting technique has significantly advanced the construction of radiance fields from multi-view images, enabling real-time rendering. While point-based rasterization effectively reduces computational demands for rendering, it often struggles to accurately reconstruct the geometry of the target object, especially under strong lighting. To address this challenge, we introduce a novel approach that combines octree-based implicit surface representations with Gaussian splatting. Our method consists of four stages. Initially, it reconstructs a signed distance field (SDF) and a radiance field through volume rendering, encoding them in a low-resolution octree. The initial SDF represents the coarse geometry of the target object. Subsequently, it introduces 3D Gaussians as additional degrees of freedom, which are guided by the SDF. In the third stage, the optimized Gaussians further improve the accuracy of the SDF, allowing it to recover finer geometric details compared to the initial SDF obtained in the first stage. Finally, it adopts the refined SDF to further optimize the 3D Gaussians via splatting, eliminating those that contribute little to visual appearance. Experimental results show that our method, which leverages the distribution of 3D Gaussians with SDFs, reconstructs more accurate geometry, particularly in images with specular highlights caused by strong lighting.
OPE-SR: Orthogonal Position Encoding for Designing a Parameter-free Upsampling Module in Arbitrary-scale Image Super-Resolution
Mar 02, 2023



Implicit neural representation (INR) is a popular approach for arbitrary-scale image super-resolution (SR), as a key component of INR, position encoding improves its representation ability. Motivated by position encoding, we propose orthogonal position encoding (OPE) - an extension of position encoding - and an OPE-Upscale module to replace the INR-based upsampling module for arbitrary-scale image super-resolution. Same as INR, our OPE-Upscale Module takes 2D coordinates and latent code as inputs; however it does not require training parameters. This parameter-free feature allows the OPE-Upscale Module to directly perform linear combination operations to reconstruct an image in a continuous manner, achieving an arbitrary-scale image reconstruction. As a concise SR framework, our method has high computing efficiency and consumes less memory comparing to the state-of-the-art (SOTA), which has been confirmed by extensive experiments and evaluations. In addition, our method has comparable results with SOTA in arbitrary scale image super-resolution. Last but not the least, we show that OPE corresponds to a set of orthogonal basis, justifying our design principle.
Foresee then Evaluate: Decomposing Value Estimation with Latent Future Prediction
Mar 03, 2021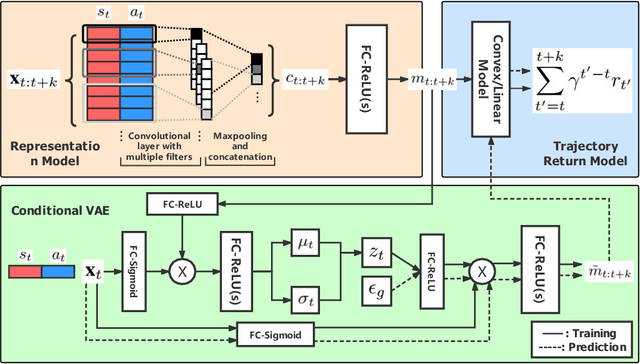

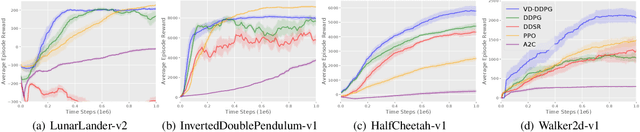
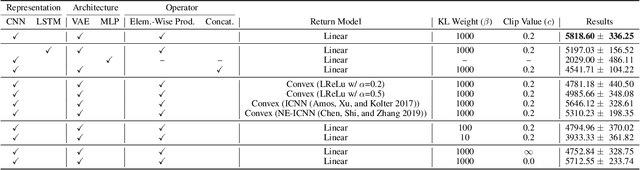
Value function is the central notion of Reinforcement Learning (RL). Value estimation, especially with function approximation, can be challenging since it involves the stochasticity of environmental dynamics and reward signals that can be sparse and delayed in some cases. A typical model-free RL algorithm usually estimates the values of a policy by Temporal Difference (TD) or Monte Carlo (MC) algorithms directly from rewards, without explicitly taking dynamics into consideration. In this paper, we propose Value Decomposition with Future Prediction (VDFP), providing an explicit two-step understanding of the value estimation process: 1) first foresee the latent future, 2) and then evaluate it. We analytically decompose the value function into a latent future dynamics part and a policy-independent trajectory return part, inducing a way to model latent dynamics and returns separately in value estimation. Further, we derive a practical deep RL algorithm, consisting of a convolutional model to learn compact trajectory representation from past experiences, a conditional variational auto-encoder to predict the latent future dynamics and a convex return model that evaluates trajectory representation. In experiments, we empirically demonstrate the effectiveness of our approach for both off-policy and on-policy RL in several OpenAI Gym continuous control tasks as well as a few challenging variants with delayed reward.
Hierarchical Reinforcement Learning for Multi-agent MOBA Game
Jan 23, 2019
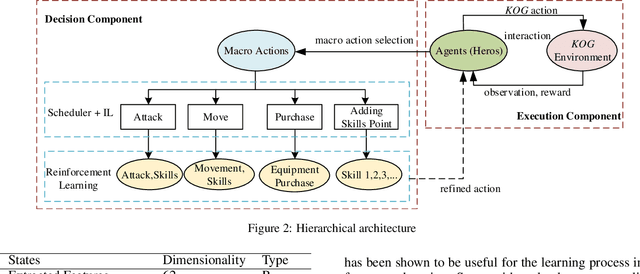
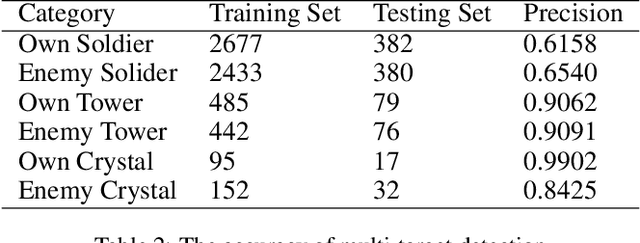
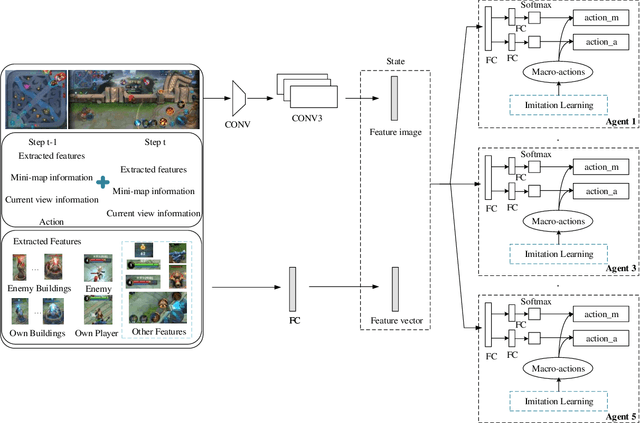
Although deep reinforcement learning has achieved great success recently, there are still challenges in Real Time Strategy (RTS) games. Due to its large state and action space, as well as hidden information, RTS games require macro strategies as well as micro level manipulation to obtain satisfactory performance. In this paper, we present a novel hierarchical reinforcement learning model for mastering Multiplayer Online Battle Arena (MOBA) games, a sub-genre of RTS games. In this hierarchical framework, agents make macro strategies by imitation learning and do micromanipulations through reinforcement learning. Moreover, we propose a simple self-learning method to get better sample efficiency for reinforcement part and extract some global features by multi-target detection method in the absence of game engine or API. In 1v1 mode, our agent successfully learns to combat and defeat built-in AI with 100\% win rate, and experiments show that our method can create a competitive multi-agent for a kind of mobile MOBA game King of Glory (KOG) in 5v5 mode.