 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-grained Image Aesthetic Assessment: Learning Discriminative Scores from Relative Ranks
Mar 04, 2026Image aesthetic assessment (IAA) has extensive applications in content creation, album management, and recommendation systems, etc. In such applications, it is commonly needed to pick out the most aesthetically pleasing image from a series of images with subtle aesthetic variations, a topic we refer to as fine-grained IAA. Unfortunately, state-of-the-art IAA models are typically designed for coarse-grained evaluation, where images with notable aesthetic differences are evaluated independently on an absolute scale. These models are inherently limited in discriminating fine-grained aesthetic differences. To address the dilemma, we contribute FGAesthetics, a fine-grained IAA database with 32,217 images organized into 10,028 series, which are sourced from diverse categories including Natural, AIGC, and Cropping. Annotations are collected via pairwise comparisons within each series. We also devise Series Refinement and Rank Calibration to ensure the reliability of data and labels. Based on FGAesthetics, we further propose FGAesQ, a novel IAA framework that learns discriminative aesthetic scores from relative ranks through Difference-preserved Tokenization (DiffToken), Comparative Text-assisted Alignment (CTAlign), and Rank-aware Regression (RankReg). FGAesQ enables accurate aesthetic assessment in fine-grained scenarios while still maintains competitive performance in coarse-grained evaluation. Extensive experiments and comparisons demonstrate the superiority of the proposed method.
Boosting Segment Anything Model to Generalize Visually Non-Salient Scenarios
Jan 02, 2026Segment Anything Model (SAM), known for its remarkable zero-shot segmentation capabilities, has garnered significant attention in the community. Nevertheless, its performance is challenged when dealing with what we refer to as visually non-salient scenarios, where there is low contrast between the foreground and background. In these cases, existing methods often cannot capture accurate contours and fail to produce promising segmentation results. In this paper, we propose Visually Non-Salient SAM (VNS-SAM), aiming to enhance SAM's perception of visually non-salient scenarios while preserving its original zero-shot generalizability. We achieve this by effectively exploiting SAM's low-level features through two designs: Mask-Edge Token Interactive decoder and Non-Salient Feature Mining module. These designs help the SAM decoder gain a deeper understanding of non-salient characteristics with only marginal parameter increments and computational requirements. The additional parameters of VNS-SAM can be optimized within 4 hours, demonstrating its feasibility and practicality. In terms of data, we established VNS-SEG, a unified dataset for various VNS scenarios, with more than 35K images, in contrast to previous single-task adaptations. It is designed to make the model learn more robust VNS features and comprehensively benchmark the model's segmentation performance and generalizability on VNS scenarios. Extensive experiments across various VNS segmentation tasks demonstrate the superior performance of VNS-SAM, particularly under zero-shot settings, highlighting its potential for broad real-world applications. Codes and datasets are publicly available at https://guangqian-guo.github.io/VNS-SAM.
LongT2IBench: A Benchmark for Evaluating Long Text-to-Image Generation with Graph-structured Annotations
Dec 10, 2025The increasing popularity of long Text-to-Image (T2I) generation has created an urgent need for automatic and interpretable models that can evaluate the image-text alignment in long prompt scenarios. However, the existing T2I alignment benchmarks predominantly focus on short prompt scenarios and only provide MOS or Likert scale annotations. This inherent limitation hinders the development of long T2I evaluators, particularly in terms of the interpretability of alignment. In this study, we contribute LongT2IBench, which comprises 14K long text-image pairs accompanied by graph-structured human annotations. Given the detail-intensive nature of long prompts, we first design a Generate-Refine-Qualify annotation protocol to convert them into textual graph structures that encompass entities, attributes, and relations. Through this transformation, fine-grained alignment annotations are achieved based on these granular elements. Finally, the graph-structed annotations are converted into alignment scores and interpretations to facilitate the design of T2I evaluation models. Based on LongT2IBench, we further propose LongT2IExpert, a LongT2I evaluator that enables multi-modal large language models (MLLMs) to provide both quantitative scores and structured interpretations through an instruction-tuning process with Hierarchical Alignment Chain-of-Thought (CoT). Extensive experiments and comparisons demonstrate the superiority of the proposed LongT2IExpert in alignment evaluation and interpretation. Data and code have been released in https://welldky.github.io/LongT2IBench-Homepage/.
ConInstruct: Evaluating Large Language Models on Conflict Detection and Resolution in Instructions
Nov 19, 2025Instruction-following is a critical capability of Large Language Models (LLMs). While existing works primarily focus on assessing how well LLMs adhere to user instructions, they often overlook scenarios where instructions contain conflicting constraints-a common occurrence in complex prompts. The behavior of LLMs under such conditions remains under-explored. To bridge this gap, we introduce ConInstruct, a benchmark specifically designed to assess LLMs' ability to detect and resolve conflicts within user instructions. Using this dataset, we evaluate LLMs' conflict detection performance and analyze their conflict resolution behavior. Our experiments reveal two key findings: (1) Most proprietary LLMs exhibit strong conflict detection capabilities, whereas among open-source models, only DeepSeek-R1 demonstrates similarly strong performance. DeepSeek-R1 and Claude-4.5-Sonnet achieve the highest average F1-scores at 91.5% and 87.3%, respectively, ranking first and second overall. (2) Despite their strong conflict detection abilities, LLMs rarely explicitly notify users about the conflicts or request clarification when faced with conflicting constraints. These results underscore a critical shortcoming in current LLMs and highlight an important area for future improvement when designing instruction-following LLMs.
TuningIQA: Fine-Grained Blind Image Quality Assessment for Livestreaming Camera Tuning
Aug 25, 2025



Livestreaming has become increasingly prevalent in modern visual communication, where automatic camera quality tuning is essential for delivering superior user Quality of Experience (QoE). Such tuning requires accurate blind image quality assessment (BIQA) to guide parameter optimization decisions. Unfortunately, the existing BIQA models typically only predict an overall coarse-grained quality score, which cannot provide fine-grained perceptual guidance for precise camera parameter tuning. To bridge this gap, we first establish FGLive-10K, a comprehensive fine-grained BIQA database containing 10,185 high-resolution images captured under varying camera parameter configurations across diverse livestreaming scenarios. The dataset features 50,925 multi-attribute quality annotations and 19,234 fine-grained pairwise preference annotations. Based on FGLive-10K, we further develop TuningIQA, a fine-grained BIQA metric for livestreaming camera tuning, which integrates human-aware feature extraction and graph-based camera parameter fusion. Extensive experiments and comparisons demonstrate that TuningIQA significantly outperforms state-of-the-art BIQA methods in both score regression and fine-grained quality ranking, achieving superior performance when deployed for livestreaming camera tuning.
Fine-grained Image Quality Assessment for Perceptual Image Restoration
Aug 20, 2025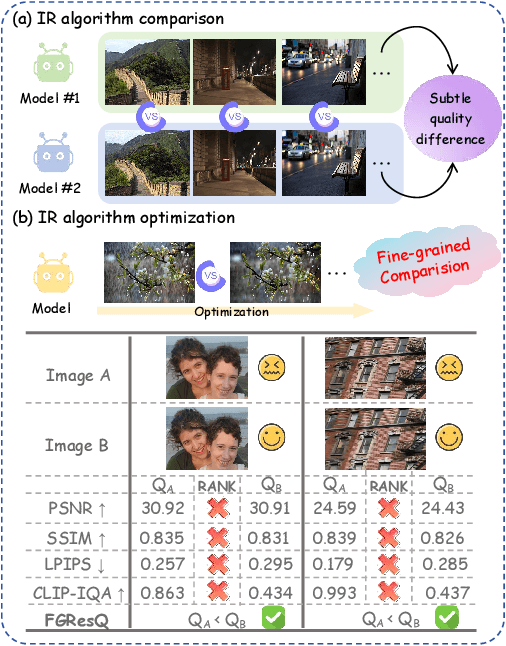

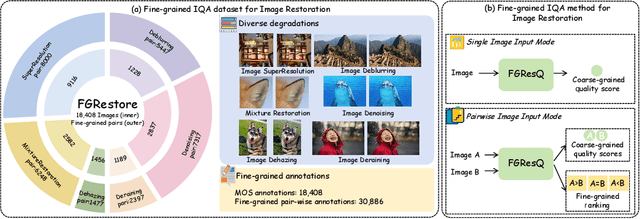

Recent years have witnessed remarkable achievements in perceptual image restoration (IR), creating an urgent demand for accurate image quality assessment (IQA), which is essential for both performance comparison and algorithm optimization. Unfortunately, the existing IQA metrics exhibit inherent weakness for IR task, particularly when distinguishing fine-grained quality differences among restored images. To address this dilemma, we contribute the first-of-its-kind fine-grained image quality assessment dataset for image restoration, termed FGRestore, comprising 18,408 restored images across six common IR tasks. Beyond conventional scalar quality scores, FGRestore was also annotated with 30,886 fine-grained pairwise preferences. Based on FGRestore, a comprehensive benchmark was conducted on the existing IQA metrics, which reveal significant inconsistencies between score-based IQA evaluations and the fine-grained restoration quality. Motivated by these findings, we further propose FGResQ, a new IQA model specifically designed for image restoration, which features both coarse-grained score regression and fine-grained quality ranking. Extensive experiments and comparisons demonstrate that FGResQ significantly outperforms state-of-the-art IQA metrics. Codes and model weights have been released in https://pxf0429.github.io/FGResQ/
Seed1.5-VL Technical Report
May 11, 2025



We present Seed1.5-VL, a vision-language foundation model designed to advance general-purpose multimodal understanding and reasoning. Seed1.5-VL is composed with a 532M-parameter vision encoder and a Mixture-of-Experts (MoE) LLM of 20B active parameters. Despite its relatively compact architecture, it delivers strong performance across a wide spectrum of public VLM benchmarks and internal evaluation suites, achieving the state-of-the-art performance on 38 out of 60 public benchmarks. Moreover, in agent-centric tasks such as GUI control and gameplay, Seed1.5-VL outperforms leading multimodal systems, including OpenAI CUA and Claude 3.7. Beyond visual and video understanding, it also demonstrates strong reasoning abilities, making it particularly effective for multimodal reasoning challenges such as visual puzzles. We believe these capabilities will empower broader applications across diverse tasks. In this report, we mainly provide a comprehensive review of our experiences in building Seed1.5-VL across model design, data construction, and training at various stages, hoping that this report can inspire further research. Seed1.5-VL is now accessible at https://www.volcengine.com/ (Volcano Engine Model ID: doubao-1-5-thinking-vision-pro-250428)
P2Object: Single Point Supervised Object Detection and Instance Segmentation
Apr 10, 2025Object recognition using single-point supervision has attracted increasing attention recently. However, the performance gap compared with fully-supervised algorithms remains large. Previous works generated class-agnostic \textbf{\textit{proposals in an image}} offline and then treated mixed candidates as a single bag, putting a huge burden on multiple instance learning (MIL). In this paper, we introduce Point-to-Box Network (P2BNet), which constructs balanced \textbf{\textit{instance-level proposal bags}} by generating proposals in an anchor-like way and refining the proposals in a coarse-to-fine paradigm. Through further research, we find that the bag of proposals, either at the image level or the instance level, is established on discrete box sampling. This leads the pseudo box estimation into a sub-optimal solution, resulting in the truncation of object boundaries or the excessive inclusion of background. Hence, we conduct a series exploration of discrete-to-continuous optimization, yielding P2BNet++ and Point-to-Mask Network (P2MNet). P2BNet++ conducts an approximately continuous proposal sampling strategy by better utilizing spatial clues. P2MNet further introduces low-level image information to assist in pixel prediction, and a boundary self-prediction is designed to relieve the limitation of the estimated boxes. Benefiting from the continuous object-aware \textbf{\textit{pixel-level perception}}, P2MNet can generate more precise bounding boxes and generalize to segmentation tasks. Our method largely surpasses the previous methods in terms of the mean average precision on COCO, VOC, SBD, and Cityscapes, demonstrating great potential to bridge the performance gap compared with fully supervised tasks.
Language-Guided Visual Perception Disentanglement for Image Quality Assessment and Conditional Image Generation
Mar 04, 2025Contrastive vision-language models, such as CLIP, have demonstrated excellent zero-shot capability across semantic recognition tasks, mainly attributed to the training on a large-scale I&1T (one Image with one Text) dataset. This kind of multimodal representations often blend semantic and perceptual elements, placing a particular emphasis on semantics. However, this could be problematic for popular tasks like image quality assessment (IQA) and conditional image generation (CIG), which typically need to have fine control on perceptual and semantic features. Motivated by the above facts, this paper presents a new multimodal disentangled representation learning framework, which leverages disentangled text to guide image disentanglement. To this end, we first build an I&2T (one Image with a perceptual Text and a semantic Text) dataset, which consists of disentangled perceptual and semantic text descriptions for an image. Then, the disentangled text descriptions are utilized as supervisory signals to disentangle pure perceptual representations from CLIP's original `coarse' feature space, dubbed DeCLIP. Finally, the decoupled feature representations are used for both image quality assessment (technical quality and aesthetic quality) and conditional image generation. Extensive experiments and comparisons have demonstrated the advantages of the proposed method on the two popular tasks. The dataset, code, and model will be available.
SAM-CP: Marrying SAM with Composable Prompts for Versatile Segmentation
Jul 23, 2024



The Segment Anything model (SAM) has shown a generalized ability to group image pixels into patches, but applying it to semantic-aware segmentation still faces major challenges. This paper presents SAM-CP, a simple approach that establishes two types of composable prompts beyond SAM and composes them for versatile segmentation. Specifically, given a set of classes (in texts) and a set of SAM patches, the Type-I prompt judges whether a SAM patch aligns with a text label, and the Type-II prompt judges whether two SAM patches with the same text label also belong to the same instance. To decrease the complexity in dealing with a large number of semantic classes and patches, we establish a unified framework that calculates the affinity between (semantic and instance) queries and SAM patches and merges patches with high affinity to the query. Experiments show that SAM-CP achieves semantic, instance, and panoptic segmentation in both open and closed domains. In particular, it achieves state-of-the-art performance in open-vocabulary segmentation. Our research offers a novel and generalized methodology for equipping vision foundation models like SAM with multi-grained semantic perception abilities.