 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQibo: A Large Language Model for Traditional Chinese Medicine
Mar 24, 2024



In the field of Artificial Intelligence, Large Language Models (LLMs) have demonstrated significant advances in user intent understanding and response in a number of specialized domains, including medicine, law, and finance. However, in the unique domain of traditional Chinese medicine (TCM), the performance enhancement of LLMs is challenged by the essential differences between its theories and modern medicine, as well as the lack of specialized corpus resources. In this paper, we aim to construct and organize a professional corpus in the field of TCM, to endow the large model with professional knowledge that is characteristic of TCM theory, and to successfully develop the Qibo model based on LLaMA, which is the first LLM in the field of TCM to undergo a complete training process from pre-training to Supervised Fine-Tuning (SFT). Furthermore, we develop the Qibo-benchmark, a specialized tool for evaluating the performance of LLMs, which is a specialized tool for evaluating the performance of LLMs in the TCM domain. This tool will provide an important basis for quantifying and comparing the understanding and application capabilities of different models in the field of traditional Chinese medicine, and provide guidance for future research directions and practical applications of intelligent assistants for traditional Chinese medicine. Finally, we conducted sufficient experiments to prove that Qibo has good performance in the field of traditional Chinese medicine.
Learning with Noisy Labels Using Collaborative Sample Selection and Contrastive Semi-Supervised Learning
Oct 24, 2023



Learning with noisy labels (LNL) has been extensively studied, with existing approaches typically following a framework that alternates between clean sample selection and semi-supervised learning (SSL). However, this approach has a limitation: the clean set selected by the Deep Neural Network (DNN) classifier, trained through self-training, inevitably contains noisy samples. This mixture of clean and noisy samples leads to misguidance in DNN training during SSL, resulting in impaired generalization performance due to confirmation bias caused by error accumulation in sample selection. To address this issue, we propose a method called Collaborative Sample Selection (CSS), which leverages the large-scale pre-trained model CLIP. CSS aims to remove the mixed noisy samples from the identified clean set. We achieve this by training a 2-Dimensional Gaussian Mixture Model (2D-GMM) that combines the probabilities from CLIP with the predictions from the DNN classifier. To further enhance the adaptation of CLIP to LNL, we introduce a co-training mechanism with a contrastive loss in semi-supervised learning. This allows us to jointly train the prompt of CLIP and the DNN classifier, resulting in improved feature representation, boosted classification performance of DNNs, and reciprocal benefits to our Collaborative Sample Selection. By incorporating auxiliary information from CLIP and utilizing prompt fine-tuning, we effectively eliminate noisy samples from the clean set and mitigate confirmation bias during training. Experimental results on multiple benchmark datasets demonstrate the effectiveness of our proposed method in comparison with the state-of-the-art approaches.
Ensemble-based Offline-to-Online Reinforcement Learning: From Pessimistic Learning to Optimistic Exploration
Jun 12, 2023Offline reinforcement learning (RL) is a learning paradigm where an agent learns from a fixed dataset of experience. However, learning solely from a static dataset can limit the performance due to the lack of exploration. To overcome it, offline-to-online RL combines offline pre-training with online fine-tuning, which enables the agent to further refine its policy by interacting with the environment in real-time. Despite its benefits, existing offline-to-online RL methods suffer from performance degradation and slow improvement during the online phase. To tackle these challenges, we propose a novel framework called Ensemble-based Offline-to-Online (E2O) RL. By increasing the number of Q-networks, we seamlessly bridge offline pre-training and online fine-tuning without degrading performance. Moreover, to expedite online performance enhancement, we appropriately loosen the pessimism of Q-value estimation and incorporate ensemble-based exploration mechanisms into our framework. Experimental results demonstrate that E2O can substantially improve the training stability, learning efficiency, and final performance of existing offline RL methods during online fine-tuning on a range of locomotion and navigation tasks, significantly outperforming existing offline-to-online RL methods.
HIPODE: Enhancing Offline Reinforcement Learning with High-Quality Synthetic Data from a Policy-Decoupled Approach
Jun 10, 2023



Offline reinforcement learning (ORL) has gained attention as a means of training reinforcement learning models using pre-collected static data. To address the issue of limited data and improve downstream ORL performance, recent work has attempted to expand the dataset's coverage through data augmentation. However, most of these methods are tied to a specific policy (policy-dependent), where the generated data can only guarantee to support the current downstream ORL policy, limiting its usage scope on other downstream policies. Moreover, the quality of synthetic data is often not well-controlled, which limits the potential for further improving the downstream policy. To tackle these issues, we propose \textbf{HI}gh-quality \textbf{PO}licy-\textbf{DE}coupled~(HIPODE), a novel data augmentation method for ORL. On the one hand, HIPODE generates high-quality synthetic data by selecting states near the dataset distribution with potentially high value among candidate states using the negative sampling technique. On the other hand, HIPODE is policy-decoupled, thus can be used as a common plug-in method for any downstream ORL process. We conduct experiments on the widely studied TD3BC and CQL algorithms, and the results show that HIPODE outperforms the state-of-the-art policy-decoupled data augmentation method and most prevalent model-based ORL methods on D4RL benchmarks.
In-Sample Policy Iteration for Offline Reinforcement Learning
Jun 09, 2023Offline reinforcement learning (RL) seeks to derive an effective control policy from previously collected data. To circumvent errors due to inadequate data coverage, behavior-regularized methods optimize the control policy while concurrently minimizing deviation from the data collection policy. Nevertheless, these methods often exhibit subpar practical performance, particularly when the offline dataset is collected by sub-optimal policies. In this paper, we propose a novel algorithm employing in-sample policy iteration that substantially enhances behavior-regularized methods in offline RL. The core insight is that by continuously refining the policy used for behavior regularization, in-sample policy iteration gradually improves itself while implicitly avoids querying out-of-sample actions to avert catastrophic learning failures. Our theoretical analysis verifies its ability to learn the in-sample optimal policy, exclusively utilizing actions well-covered by the dataset. Moreover, we propose competitive policy improvement, a technique applying two competitive policies, both of which are trained by iteratively improving over the best competitor. We show that this simple yet potent technique significantly enhances learning efficiency when function approximation is applied. Lastly, experimental results on the D4RL benchmark indicate that our algorithm outperforms previous state-of-the-art methods in most tasks.
ERL-Re$^2$: Efficient Evolutionary Reinforcement Learning with Shared State Representation and Individual Policy Representation
Oct 26, 2022



Deep Reinforcement Learning (Deep RL) and Evolutionary Algorithm (EA) are two major paradigms of policy optimization with distinct learning principles, i.e., gradient-based v.s. gradient free. An appealing research direction is integrating Deep RL and EA to devise new methods by fusing their complementary advantages. However, existing works on combining Deep RL and EA have two common drawbacks: 1) the RL agent and EA agents learn their policies individually, neglecting efficient sharing of useful common knowledge; 2) parameter-level policy optimization guarantees no semantic level of behavior evolution for the EA side. In this paper, we propose Evolutionary Reinforcement Learning with Two-scale State Representation and Policy Representation (ERL-Re2), a novel solution to the aforementioned two drawbacks. The key idea of ERL-Re2 is two-scale representation: all EA and RL policies share the same nonlinear state representation while maintaining individual linear policy representations. The state representation conveys expressive common features of the environment learned by all the agents collectively; the linear policy representation provides a favorable space for efficient policy optimization, where novel behavior-level crossover and mutation operations can be performed. Moreover, the linear policy representation allows convenient generalization of policy fitness with the help of Policy-extended Value Function Approximator (PeVFA), further improving the sample efficiency of fitness estimation. The experiments on a range of continuous control tasks show that ERL-Re2 consistently outperforms strong baselines and achieves significant improvement over both its Deep RL and EA components.
PAnDR: Fast Adaptation to New Environments from Offline Experiences via Decoupling Policy and Environment Representations
Apr 06, 2022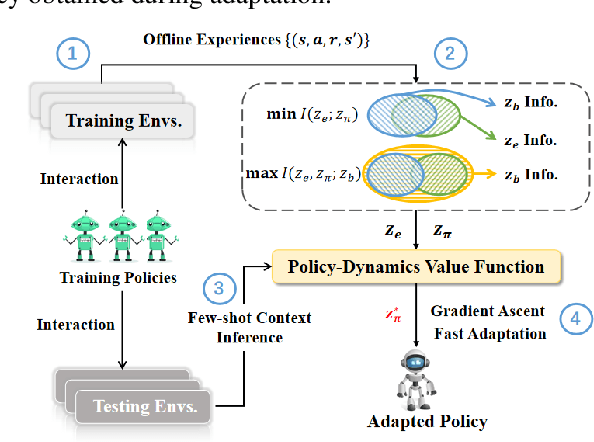
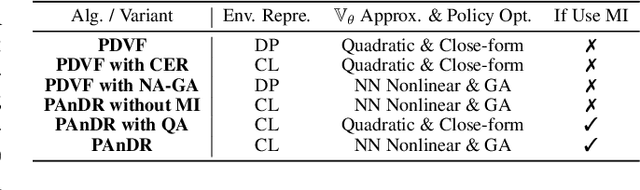
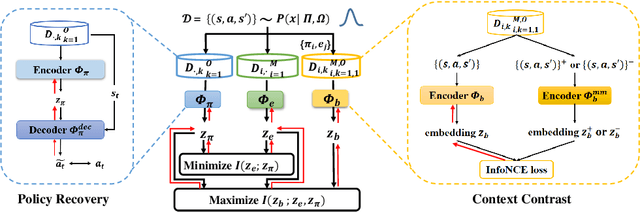

Deep Reinforcement Learning (DRL) has been a promising solution to many complex decision-making problems. Nevertheless, the notorious weakness in generalization among environments prevent widespread application of DRL agents in real-world scenarios. Although advances have been made recently, most prior works assume sufficient online interaction on training environments, which can be costly in practical cases. To this end, we focus on an \textit{offline-training-online-adaptation} setting, in which the agent first learns from offline experiences collected in environments with different dynamics and then performs online policy adaptation in environments with new dynamics. In this paper, we propose Policy Adaptation with Decoupled Representations (PAnDR) for fast policy adaptation. In offline training phase, the environment representation and policy representation are learned through contrastive learning and policy recovery, respectively. The representations are further refined by mutual information optimization to make them more decoupled and complete. With learned representations, a Policy-Dynamics Value Function (PDVF) (Raileanu et al., 2020) network is trained to approximate the values for different combinations of policies and environments. In online adaptation phase, with the environment context inferred from few experiences collected in new environments, the policy is optimized by gradient ascent with respect to the PDVF. Our experiments show that PAnDR outperforms existing algorithms in several representative policy adaptation problems.
Uncertainty-aware Low-Rank Q-Matrix Estimation for Deep Reinforcement Learning
Nov 19, 2021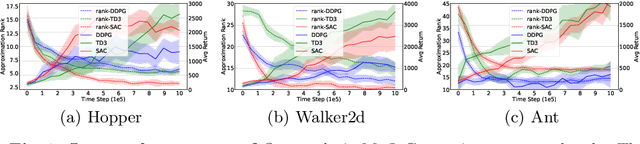
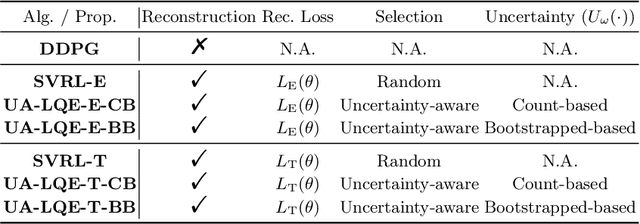
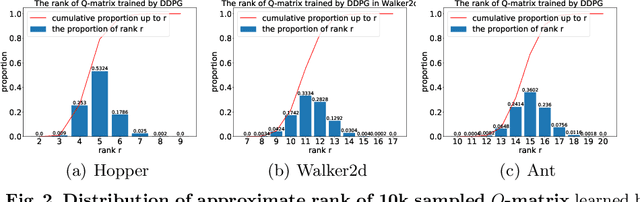
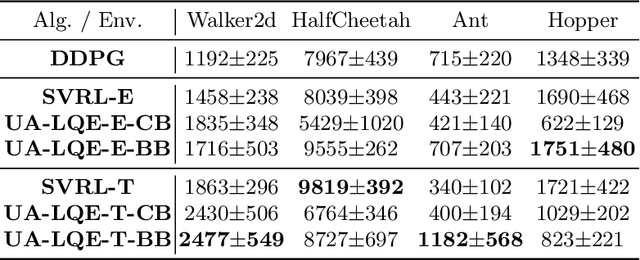
Value estimation is one key problem in Reinforcement Learning. Albeit many successes have been achieved by Deep Reinforcement Learning (DRL) in different fields, the underlying structure and learning dynamics of value function, especially with complex function approximation, are not fully understood. In this paper, we report that decreasing rank of $Q$-matrix widely exists during learning process across a series of continuous control tasks for different popular algorithms. We hypothesize that the low-rank phenomenon indicates the common learning dynamics of $Q$-matrix from stochastic high dimensional space to smooth low dimensional space. Moreover, we reveal a positive correlation between value matrix rank and value estimation uncertainty. Inspired by above evidence, we propose a novel Uncertainty-Aware Low-rank Q-matrix Estimation (UA-LQE) algorithm as a general framework to facilitate the learning of value function. Through quantifying the uncertainty of state-action value estimation, we selectively erase the entries of highly uncertain values in state-action value matrix and conduct low-rank matrix reconstruction for them to recover their values. Such a reconstruction exploits the underlying structure of value matrix to improve the value approximation, thus leading to a more efficient learning process of value function. In the experiments, we evaluate the efficacy of UA-LQE in several representative OpenAI MuJoCo continuous control tasks.
Exploration in Deep Reinforcement Learning: A Comprehensive Survey
Sep 15, 2021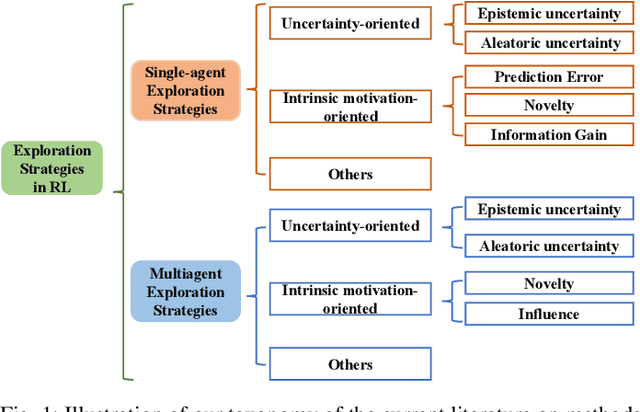

Deep Reinforcement Learning (DRL) and Deep Multi-agent Reinforcement Learning (MARL) have achieved significant success across a wide range of domains, such as game AI, autonomous vehicles, robotics and finance. However, DRL and deep MARL agents are widely known to be sample-inefficient and millions of interactions are usually needed even for relatively simple game settings, thus preventing the wide application in real-industry scenarios. One bottleneck challenge behind is the well-known exploration problem, i.e., how to efficiently explore the unknown environments and collect informative experiences that could benefit the policy learning most. In this paper, we conduct a comprehensive survey on existing exploration methods in DRL and deep MARL for the purpose of providing understandings and insights on the critical problems and solutions. We first identify several key challenges to achieve efficient exploration, which most of the exploration methods aim at addressing. Then we provide a systematic survey of existing approaches by classifying them into two major categories: uncertainty-oriented exploration and intrinsic motivation-oriented exploration. The essence of uncertainty-oriented exploration is to leverage the quantification of the epistemic and aleatoric uncertainty to derive efficient exploration. By contrast, intrinsic motivation-oriented exploration methods usually incorporate different reward agnostic information for intrinsic exploration guidance. Beyond the above two main branches, we also conclude other exploration methods which adopt sophisticated techniques but are difficult to be classified into the above two categories. In addition, we provide a comprehensive empirical comparison of exploration methods for DRL on a set of commonly used benchmarks. Finally, we summarize the open problems of exploration in DRL and deep MARL and point out a few future directions.
HyAR: Addressing Discrete-Continuous Action Reinforcement Learning via Hybrid Action Representation
Sep 12, 2021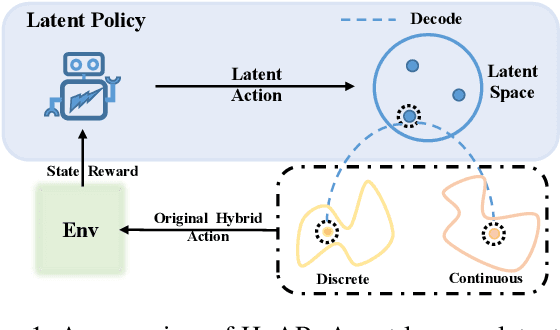
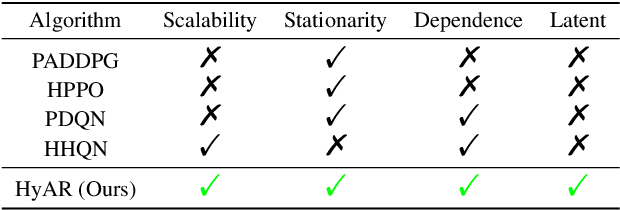
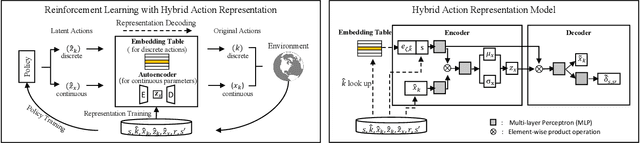
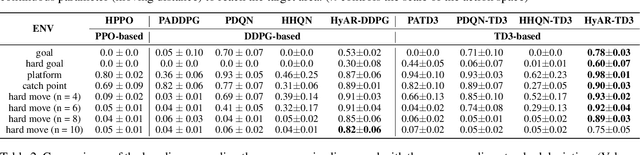
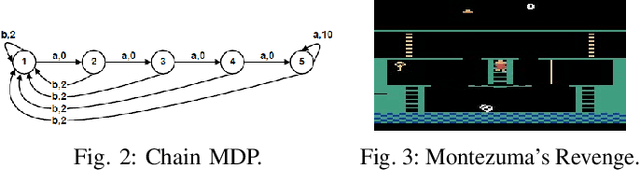
Discrete-continuous hybrid action space is a natural setting in many practical problems, such as robot control and game AI. However, most previous Reinforcement Learning (RL) works only demonstrate the success in controlling with either discrete or continuous action space, while seldom take into account the hybrid action space. One naive way to address hybrid action RL is to convert the hybrid action space into a unified homogeneous action space by discretization or continualization, so that conventional RL algorithms can be applied. However, this ignores the underlying structure of hybrid action space and also induces the scalability issue and additional approximation difficulties, thus leading to degenerated results. In this paper, we propose Hybrid Action Representation (HyAR) to learn a compact and decodable latent representation space for the original hybrid action space. HyAR constructs the latent space and embeds the dependence between discrete action and continuous parameter via an embedding table and conditional Variantional Auto-Encoder (VAE). To further improve the effectiveness, the action representation is trained to be semantically smooth through unsupervised environmental dynamics prediction. Finally, the agent then learns its policy with conventional DRL algorithms in the learned representation space and interacts with the environment by decoding the hybrid action embeddings to the original action space. We evaluate HyAR in a variety of environments with discrete-continuous action space. The results demonstrate the superiority of HyAR when compared with previous baselines, especially for high-dimensional action spaces.