 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Succinct Summary of Reinforcement Learning
Jan 03, 2023This document is a concise summary of many key results in single-agent reinforcement learning (RL). The intended audience are those who already have some familiarity with RL and are looking to review, reference and/or remind themselves of important ideas in the field.
SMARTS: Scalable Multi-Agent Reinforcement Learning Training School for Autonomous Driving
Nov 01, 2020
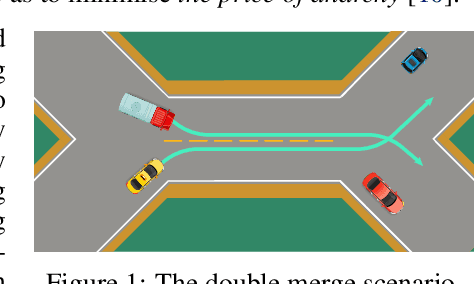
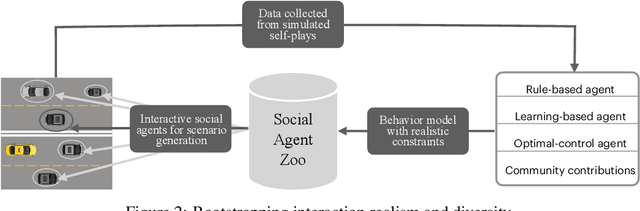
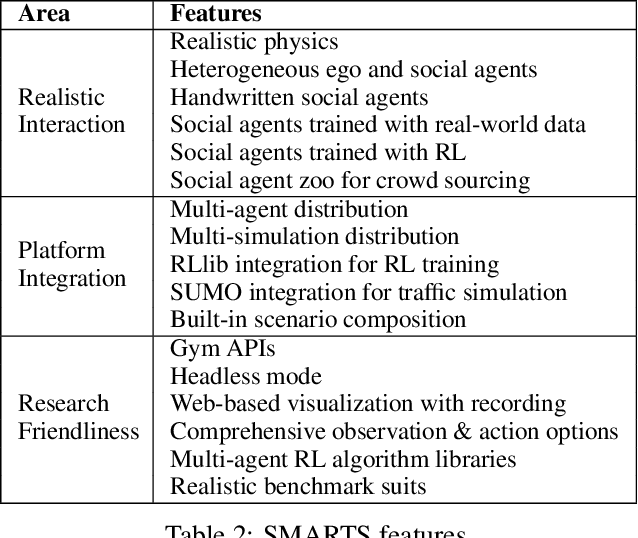
Multi-agent interaction is a fundamental aspect of autonomous driving in the real world. Despite more than a decade of research and development, the problem of how to competently interact with diverse road users in diverse scenarios remains largely unsolved. Learning methods have much to offer towards solving this problem. But they require a realistic multi-agent simulator that generates diverse and competent driving interactions. To meet this need, we develop a dedicated simulation platform called SMARTS (Scalable Multi-Agent RL Training School). SMARTS supports the training, accumulation, and use of diverse behavior models of road users. These are in turn used to create increasingly more realistic and diverse interactions that enable deeper and broader research on multi-agent interaction. In this paper, we describe the design goals of SMARTS, explain its basic architecture and its key features, and illustrate its use through concrete multi-agent experiments on interactive scenarios. We open-source the SMARTS platform and the associated benchmark tasks and evaluation metrics to encourage and empower research on multi-agent learning for autonomous driving. Our code is available at https://github.com/huawei-noah/SMARTS.
Correcting Experience Replay for Multi-Agent Communication
Oct 02, 2020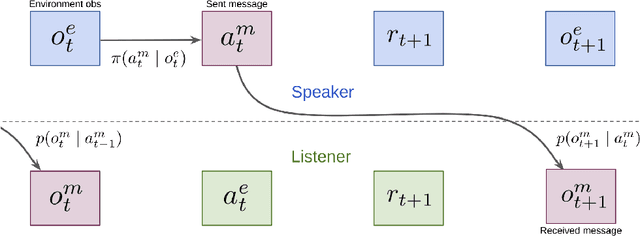
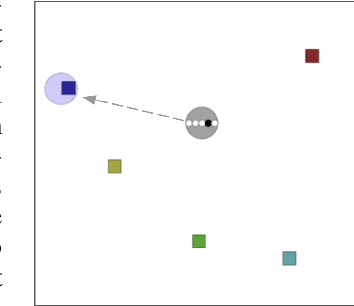
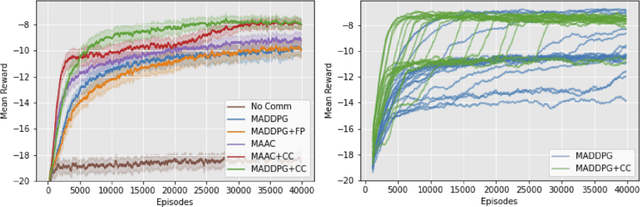
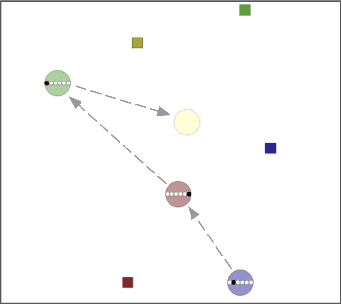
We consider the problem of learning to communicate using multi-agent reinforcement learning (MARL). A common approach is to learn off-policy, using data sampled from a replay buffer. However, messages received in the past may not accurately reflect the current communication policy of each agent, and this complicates learning. We therefore introduce a 'communication correction' which accounts for the non-stationarity of observed communication induced by multi-agent learning. It works by relabelling the received message to make it likely under the communicator's current policy, and thus be a better reflection of the receiver's current environment. To account for cases in which agents are both senders and receivers, we introduce an ordered relabelling scheme. Our correction is computationally efficient and can be integrated with a range of off-policy algorithms. It substantially improves the ability of communicating MARL systems to learn across a variety of cooperative and competitive tasks.
Feudal Multi-Agent Hierarchies for Cooperative Reinforcement Learning
Jan 24, 2019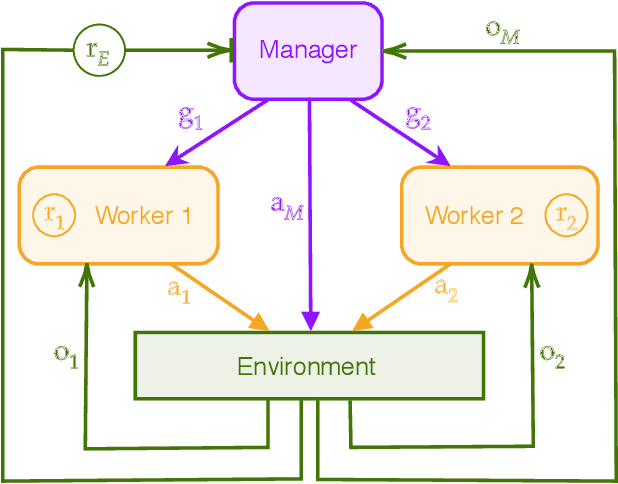

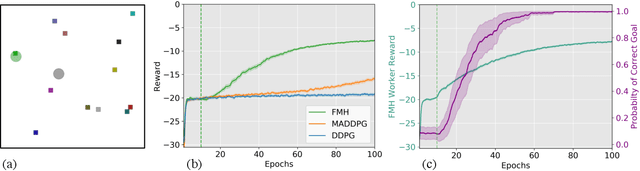
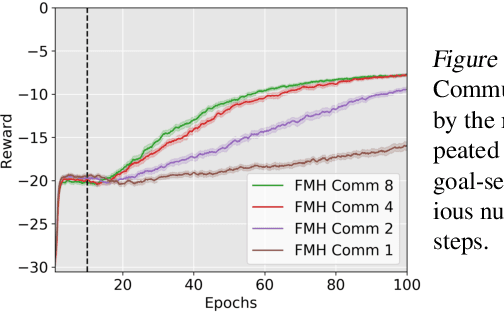
We investigate how reinforcement learning agents can learn to cooperate. Drawing inspiration from human societies, in which successful coordination of many individuals is often facilitated by hierarchical organisation, we introduce Feudal Multi-agent Hierarchies (FMH). In this framework, a 'manager' agent, which is tasked with maximising the environmentally-determined reward function, learns to communicate subgoals to multiple, simultaneously-operating, 'worker' agents. Workers, which are rewarded for achieving managerial subgoals, take concurrent actions in the world. We outline the structure of FMH and demonstrate its potential for decentralised learning and control. We find that, given an adequate set of subgoals from which to choose, FMH performs, and particularly scales, substantially better than cooperative approaches that use a shared reward function.