 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3DThinkVLA: Endowing Vision-Language-Action Models with Latent 3D Priors via 3D-Thinking-Guided Co-training
Jun 03, 2026We propose a 3D-thinking-guided co-training framework that enables vision-language-action (VLA) models to perform 3D spatial reasoning implicitly during action prediction. Our core insight is that 3D geometry perception and 3D spatial reasoning are distinct capabilities that can be disentangled and injected at different feature hierarchies. During training, three tightly coupled components work in concert primarily within the latent space: (1) To gain geometric priors, a latent 3D geometry perception module aligns intermediate visual features with a 3D foundation model, acquiring low-level geometric cues without architectural modifications to the VLM backbone. (2) Complementing this, an online 3D reasoning distillation module mitigates the prompt-induced reasoning gap via a shared reasoning anchor token. During 3D VLM co-training, this anchor is emitted as the first output token to robustly encode spatial priors. During VLA training, it serves as an input token inserted between the task and action instructions, transferring high-level spatial thinking from explicit teacher reasoning prompts to student action prompts without chain-of-thought text generation. (3) These disentangled geometric and reasoning features are then united by a spatially augmented action integration, which jointly injects them into the action-query tokens as hierarchical spatial conditions to prevent action shortcuts. At deployment, our method retains only its lightweight adapters to perform implicit 3D reasoning, discarding the 3D foundation model and the teacher branch used for supervision. Consequently, it operates purely on 2D images without 3D sensors, external models, or explicit text generation while preventing catastrophic forgetting of the pretrained VLM, achieving state-of-the-art performance on LIBERO, LIBERO-PLUS, SimplerEnv, and real-world manipulation tasks.
Touch-R1: Reinforcing Touch Reasoning in MLLMs
May 26, 2026While rule-based reinforcement learning has recently catalyzed explicit reasoning in multimodal models, tactile reasoning remains largely underexplored. Existing tactile-language models primarily rely on supervised or contrastive objectives, which limits their capacity to ground predictions in physical evidence or rectify misleading visual priors. Tactile reasoning introduces two modality-specific challenges: the ordinal nature of physical attributes (e.g., hardness, roughness) and the cross-sensor distribution shifts inherent in optical tactile hardware. In this work, we introduce TouchReason-1M, a large-scale multimodal dataset comprising over 1M synchronized tactile pairs across four distinct sensors, and TouchReason-Bench, a rigorous framework for evaluating tactile perception and visual-tactile conflict resolution. Building upon these, we propose Touch-R1, a tactile reasoning MLLM based on Qwen2.5-VL-7B. Touch-R1 is trained via a tactile-grounded GRPO objective that combines ordinal-aware accuracy, cross-sensor physical consistency, structured-format control, and an input-side tactile grounding objective. Specifically, the tactile-use reward assigns credit only when authentic tactile inputs yield superior correctness relative to counterfactual controls where the tactile stream is removed, shuffled, or noise-masked. On TouchReason-Bench, Touch-R1-7B outperforms Octopi-13B by 18.4\% and GPT-4o by 24.7\% on average. Its structured reasoning traces reveal emergent behaviors of probing, comparison, and revision, demonstrating that R1-style reasoning can be effectively grounded in physical contact.
FocusVLA: Focused Visual Utilization for Vision-Language-Action Models
Mar 30, 2026Vision-Language-Action (VLA) models improve action generation by conditioning policies on rich vision-language information. However, current auto-regressive policies are constrained by three bottlenecks: (1) architectural bias drives models to overlook visual details, (2) an excessive number of visual tokens makes attention difficult to focus on the correct regions, and (3) task-irrelevant visual information introduces substantial noise - together severely impairing the quality of action. In this paper, we investigate how to effectively utilize different visual representations for action generation. To this end, we first empirically validate the above issues and show that VLA performance is primarily limited by how visual information is utilized, rather than by the quality of visual representations. Based on these insights, we introduce FocusVLA, a novel paradigm that directs the model's attention to task-relevant visual regions to effectively bridge vision to action. Specifically, we first propose Modality Cascaded Attention to eliminate shortcut pathways, thereby compelling VLA models to rely on task-relevant visual details for action generation. Furthermore, we propose Focus Attention, which dynamically selects task-relevant visual patches to control information quantity while explicitly modulating their influence to suppress task-irrelevant noise. Extensive experiments on both simulated and real-world robotic benchmarks demonstrate that FocusVLA not only effectively leverages visual details to perform dexterous manipulations, but also substantially improves performance and accelerates convergence across a variety of tasks.
ViSA: 3D-Aware Video Shading for Real-Time Upper-Body Avatar Creation
Dec 09, 2025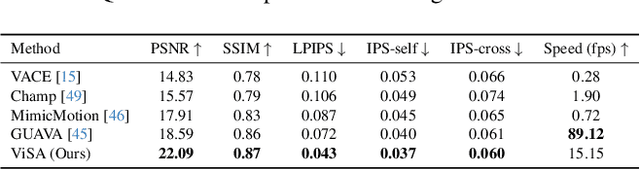
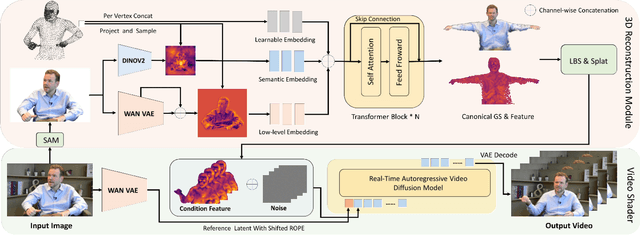
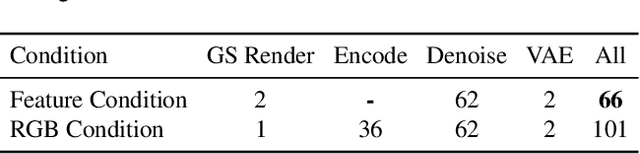
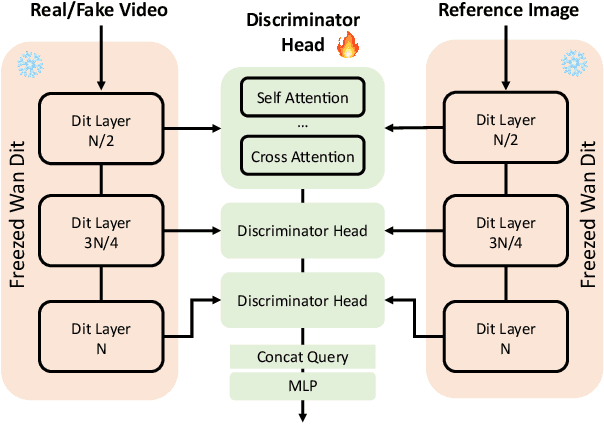
Generating high-fidelity upper-body 3D avatars from one-shot input image remains a significant challenge. Current 3D avatar generation methods, which rely on large reconstruction models, are fast and capable of producing stable body structures, but they often suffer from artifacts such as blurry textures and stiff, unnatural motion. In contrast, generative video models show promising performance by synthesizing photorealistic and dynamic results, but they frequently struggle with unstable behavior, including body structural errors and identity drift. To address these limitations, we propose a novel approach that combines the strengths of both paradigms. Our framework employs a 3D reconstruction model to provide robust structural and appearance priors, which in turn guides a real-time autoregressive video diffusion model for rendering. This process enables the model to synthesize high-frequency, photorealistic details and fluid dynamics in real time, effectively reducing texture blur and motion stiffness while preventing the structural inconsistencies common in video generation methods. By uniting the geometric stability of 3D reconstruction with the generative capabilities of video models, our method produces high-fidelity digital avatars with realistic appearance and dynamic, temporally coherent motion. Experiments demonstrate that our approach significantly reduces artifacts and achieves substantial improvements in visual quality over leading methods, providing a robust and efficient solution for real-time applications such as gaming and virtual reality. Project page: https://lhyfst.github.io/visa
OmniMotion: Multimodal Motion Generation with Continuous Masked Autoregression
Oct 16, 2025


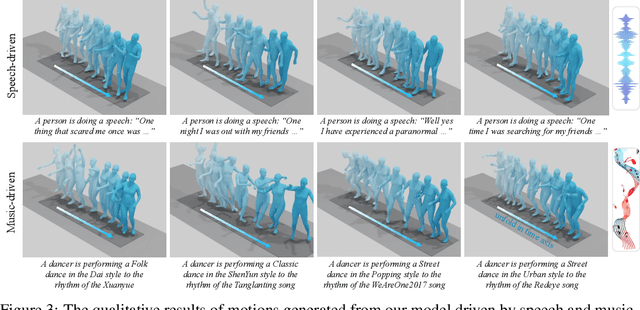
Whole-body multi-modal human motion generation poses two primary challenges: creating an effective motion generation mechanism and integrating various modalities, such as text, speech, and music, into a cohesive framework. Unlike previous methods that usually employ discrete masked modeling or autoregressive modeling, we develop a continuous masked autoregressive motion transformer, where a causal attention is performed considering the sequential nature within the human motion. Within this transformer, we introduce a gated linear attention and an RMSNorm module, which drive the transformer to pay attention to the key actions and suppress the instability caused by either the abnormal movements or the heterogeneous distributions within multi-modalities. To further enhance both the motion generation and the multimodal generalization, we employ the DiT structure to diffuse the conditions from the transformer towards the targets. To fuse different modalities, AdaLN and cross-attention are leveraged to inject the text, speech, and music signals. Experimental results demonstrate that our framework outperforms previous methods across all modalities, including text-to-motion, speech-to-gesture, and music-to-dance. The code of our method will be made public.
PanoLAM: Large Avatar Model for Gaussian Full-Head Synthesis from One-shot Unposed Image
Sep 09, 2025



We present a feed-forward framework for Gaussian full-head synthesis from a single unposed image. Unlike previous work that relies on time-consuming GAN inversion and test-time optimization, our framework can reconstruct the Gaussian full-head model given a single unposed image in a single forward pass. This enables fast reconstruction and rendering during inference. To mitigate the lack of large-scale 3D head assets, we propose a large-scale synthetic dataset from trained 3D GANs and train our framework using only synthetic data. For efficient high-fidelity generation, we introduce a coarse-to-fine Gaussian head generation pipeline, where sparse points from the FLAME model interact with the image features by transformer blocks for feature extraction and coarse shape reconstruction, which are then densified for high-fidelity reconstruction. To fully leverage the prior knowledge residing in pretrained 3D GANs for effective reconstruction, we propose a dual-branch framework that effectively aggregates the structured spherical triplane feature and unstructured point-based features for more effective Gaussian head reconstruction. Experimental results show the effectiveness of our framework towards existing work.
DicFace: Dirichlet-Constrained Variational Codebook Learning for Temporally Coherent Video Face Restoration
Jun 16, 2025



Video face restoration faces a critical challenge in maintaining temporal consistency while recovering fine facial details from degraded inputs. This paper presents a novel approach that extends Vector-Quantized Variational Autoencoders (VQ-VAEs), pretrained on static high-quality portraits, into a video restoration framework through variational latent space modeling. Our key innovation lies in reformulating discrete codebook representations as Dirichlet-distributed continuous variables, enabling probabilistic transitions between facial features across frames. A spatio-temporal Transformer architecture jointly models inter-frame dependencies and predicts latent distributions, while a Laplacian-constrained reconstruction loss combined with perceptual (LPIPS) regularization enhances both pixel accuracy and visual quality. Comprehensive evaluations on blind face restoration, video inpainting, and facial colorization tasks demonstrate state-of-the-art performance. This work establishes an effective paradigm for adapting intensive image priors, pretrained on high-quality images, to video restoration while addressing the critical challenge of flicker artifacts. The source code has been open-sourced and is available at https://github.com/fudan-generative-vision/DicFace.
PF-LHM: 3D Animatable Avatar Reconstruction from Pose-free Articulated Human Images
Jun 16, 2025Reconstructing an animatable 3D human from casually captured images of an articulated subject without camera or human pose information is a practical yet challenging task due to view misalignment, occlusions, and the absence of structural priors. While optimization-based methods can produce high-fidelity results from monocular or multi-view videos, they require accurate pose estimation and slow iterative optimization, limiting scalability in unconstrained scenarios. Recent feed-forward approaches enable efficient single-image reconstruction but struggle to effectively leverage multiple input images to reduce ambiguity and improve reconstruction accuracy. To address these challenges, we propose PF-LHM, a large human reconstruction model that generates high-quality 3D avatars in seconds from one or multiple casually captured pose-free images. Our approach introduces an efficient Encoder-Decoder Point-Image Transformer architecture, which fuses hierarchical geometric point features and multi-view image features through multimodal attention. The fused features are decoded to recover detailed geometry and appearance, represented using 3D Gaussian splats. Extensive experiments on both real and synthetic datasets demonstrate that our method unifies single- and multi-image 3D human reconstruction, achieving high-fidelity and animatable 3D human avatars without requiring camera and human pose annotations. Code and models will be released to the public.
LHM: Large Animatable Human Reconstruction Model from a Single Image in Seconds
Mar 13, 2025Animatable 3D human reconstruction from a single image is a challenging problem due to the ambiguity in decoupling geometry, appearance, and deformation. Recent advances in 3D human reconstruction mainly focus on static human modeling, and the reliance of using synthetic 3D scans for training limits their generalization ability. Conversely, optimization-based video methods achieve higher fidelity but demand controlled capture conditions and computationally intensive refinement processes. Motivated by the emergence of large reconstruction models for efficient static reconstruction, we propose LHM (Large Animatable Human Reconstruction Model) to infer high-fidelity avatars represented as 3D Gaussian splatting in a feed-forward pass. Our model leverages a multimodal transformer architecture to effectively encode the human body positional features and image features with attention mechanism, enabling detailed preservation of clothing geometry and texture. To further boost the face identity preservation and fine detail recovery, we propose a head feature pyramid encoding scheme to aggregate multi-scale features of the head regions. Extensive experiments demonstrate that our LHM generates plausible animatable human in seconds without post-processing for face and hands, outperforming existing methods in both reconstruction accuracy and generalization ability.
LAM: Large Avatar Model for One-shot Animatable Gaussian Head
Feb 25, 2025We present LAM, an innovative Large Avatar Model for animatable Gaussian head reconstruction from a single image. Unlike previous methods that require extensive training on captured video sequences or rely on auxiliary neural networks for animation and rendering during inference, our approach generates Gaussian heads that are immediately animatable and renderable. Specifically, LAM creates an animatable Gaussian head in a single forward pass, enabling reenactment and rendering without additional networks or post-processing steps. This capability allows for seamless integration into existing rendering pipelines, ensuring real-time animation and rendering across a wide range of platforms, including mobile phones. The centerpiece of our framework is the canonical Gaussian attributes generator, which utilizes FLAME canonical points as queries. These points interact with multi-scale image features through a Transformer to accurately predict Gaussian attributes in the canonical space. The reconstructed canonical Gaussian avatar can then be animated utilizing standard linear blend skinning (LBS) with corrective blendshapes as the FLAME model did and rendered in real-time on various platforms. Our experimental results demonstrate that LAM outperforms state-of-the-art methods on existing benchmarks.