 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePAL-Bench: Evidence-Grounded Profile Reconstruction from Longitudinal Personal Albums
Jun 15, 2026Longitudinal personal albums are weak-schema multimodal databases: noisy perceptual records whose key facts require joins across faces, text, timestamps, locations, and repeated events. Existing visual, video, document, and lifelog benchmarks test sub-problems, but not album-scale profile reconstruction with social identity binding and evidence citation. Benchmarking this task is difficult because the ground truth needed for evaluation--owner profiles, social graphs, face-name maps, and evidence provenance--is private state that real albums cannot safely release. We introduce PAL-Bench, a controlled benchmark for evidence-grounded reconstruction under a public-record contract. Its Evidence Compiler builds latent private worlds, programs target-level evidence paths, renders album pixels, re-measures them through perception pipelines, and exports audited public/private views. Agents receive only perception-derived public records; targets, identifier maps, and evidence paths remain hidden. PAL-Bench contains 50 synthetic users, 36,659 public photo records, and 2,799 targets over owner facts, identities, and relations. A privacy-preserving audit with 10 participants confirms that PAL-Bench evidence structures match real private albums, though equivalent releases remain privacy-prohibitive. Across seven systems and two compute-matched diagnostics, a seven-metric protocol reveals a gap between plausible profile summarization and faithful social reconstruction: systems recover some owner facts but struggle with recurring identities and evidence citation. PAL-TRACE, a reference framework that freezes identity bindings before owner-fact mining, performs best but leaves hard identity resolution far from solved. PAL-Bench provides a testbed for perceptual entity resolution, multimodal data integration, temporal evidence aggregation, and provenance-aware structured prediction.
TouchThinker: Scaling Tactile Commonsense Reasoning to the Open World with Large-scale Data and Action-aware Representation
Jun 10, 2026Touch is a key modality for embodied agents to understand the physical world. Although recent work has incorporated tactile signals into language systems for tactile commonsense reasoning, scaling such systems to realistic open-world settings remains challenging due to two key bottlenecks: (1) current tactile reasoning datasets remain limited in format and scale, providing insufficient supervision for reasoning from tactile observations to physical commonsense and hindering the learning of transferable tactile commonsense; (2) Tactile signals are inherently redundant and action-specific, yet existing methods often overlook these properties, resulting in inefficient representations with limited semantic expressiveness. To address these limitations, we propose TouchThinker, a tactile-language framework that scales tactile commonsense reasoning to the open world from both data and representation perspectives. First, we construct TouchThinker-1M, a million-scale, multi-source tactile reasoning dataset covering \textbf{415} objects, \textbf{8} scenarios, and \textbf{7} sensor types, providing a solid data foundation for open-world generalization. We further introduce TouchThinker-Bench, an open-world benchmark with more realistic and diverse tasks. Then, we propose action-aware modeling mechanism to improve tactile representation efficiency and enable efficient reasoning. Experimental results demonstrate that TouchThinker achieves competitive performance against state-of-the-art models across multiple datasets. Our code and dataset will be made available at: https://github.com/lvkailin0118/TouchThinker.
WAM-Nav: Asymmetric Latent World-Action Modeling for Unified Visual Navigation
Jun 03, 2026Visual navigation requires generating smooth and collision-free trajectories under complex geometric and physical constraints. Existing reactive policies that directly map observations to actions lack anticipatory reasoning, limiting their ability to proactively avoid obstacles. While visual imagination offers predictive foresight, conventional modular approaches separate scene prediction from policy learning, often leading to error accumulation and inefficient inference. To address these limitations, we propose WAM-Nav, a Latent World-Action Model for embodied visual navigation that jointly learns action generation and latent visual foresight, enabling more robust and foresighted navigation decisions without compromising inference efficiency. Specifically, WAM-Nav utilizes a shared Diffusion Transformer for asymmetric joint diffusion to concurrently generate long-horizon actions and short-horizon visual foresight, reducing the inference latency and visual error accumulation inherent in multi-step autoregressive rollouts. To further encourage smooth and consistent trajectory generation, we introduce a dual-stream contextual conditioning mechanism that integrates episode-level ego-motion history with sequential visual observations. Combined with a unified goal alignment module that preserves balanced representations across goal types, WAM-Nav naturally supports Image-Goal, Point-Goal, and No-Goal exploration within a single policy. Extensive experiments on the challenging ClutterScenes and InternScenes benchmarks demonstrate strong generalization of WAM-Nav, particularly on Image-Goal and Point-Goal navigation, where it improves success rates by 15.7% and 3.3%, respectively. Real-world deployment further validates effective zero-shot sim-to-real transfer, achieving an average 85% task success rate across diverse indoor and outdoor environments.
PhotoCraft: Agentic Reasoning with Hierarchical Self-Evolving Memory for Deep Image Search
Jun 02, 2026Deep Image Search requires multi-step reasoning over rich contextual cues, such as time, location, and event relations. However, most existing LLM-based agents are stateless and reactive, lacking persistent memory to maintain long-horizon context or transfer experience across tasks, which often leads to execution drift and experience isolation. To address these limitations, we propose PhotoCraft, a training-free, hierarchical memory system for photo-search agents. Inspired by human cognition, PhotoCraft equips MLLMs with working, episodic, and semantic memory, which are dynamically invoked during reasoning to preserve logical consistency and knowledge transferability throughout multi-step reasoning and answer generation. Extensive experiments on DISBench demonstrate that PhotoCraft consistently improves context-aware retrieval across diverse MLLM backbones, achieving gains of up to 18.5\% and effectively mitigating key bottlenecks in memoryless deep image search, offering a practical path toward reliable and generalizable multimodal search agents.
Dual-Anchoring: Addressing State Drift in Vision-Language Navigation
Apr 19, 2026Vision-Language Navigation(VLN) requires an agent to navigate through 3D environments by following natural language instructions. While recent Video Large Language Models(Video-LLMs) have largely advanced VLN, they remain highly susceptible to State Drift in long scenarios. In these cases, the agent's internal state drifts away from the true task execution state, leading to aimless wandering and failure to execute essential maneuvers in the instruction. We attribute this failure to two distinct cognitive deficits: Progress Drift, where the agent fails to distinguish completed sub-goals from remaining ones, and Memory Drift, where the agent's history representations degrade, making it lose track of visited landmarks. In this paper, we propose a Dual-Anchoring Framework that explicitly anchors the instruction progress and history representations. First, to address progress drift, we introduce Instruction Progress Anchoring, which supervises the agent to generate structured text tokens that delineate completed versus remaining sub-goals. Second, to mitigate memory drift, we propose Memory Landmark Anchoring, which utilizes a Landmark-Centric World Model to retrospectively predict object-centric embeddings extracted by the Segment Anything Model, compelling the agent to explicitly verify past observations and preserve distinct representations of visited landmarks. Facilitating this framework, we curate two extensive datasets: 3.6 million samples with explicit progress descriptions, and 937k grounded landmark data for retrospective verification. Extensive experiments in both simulation and real-world environments demonstrate the superiority of our method, achieving a 15.2% improvement in Success Rate and a remarkable 24.7% gain on long-horizon trajectories. To facilitate further research, we will release our code, data generation pipelines, and the collected datasets.
HiMemVLN: Enhancing Reliability of Open-Source Zero-Shot Vision-and-Language Navigation with Hierarchical Memory System
Mar 16, 2026LLM-based agents have demonstrated impressive zero-shot performance in vision-language navigation (VLN) tasks. However, most zero-shot methods primarily rely on closed-source LLMs as navigators, which face challenges related to high token costs and potential data leakage risks. Recent efforts have attempted to address this by using open-source LLMs combined with a spatiotemporal CoT framework, but they still fall far short compared to closed-source models. In this work, we identify a critical issue, Navigation Amnesia, through a detailed analysis of the navigation process. This issue leads to navigation failures and amplifies the gap between open-source and closed-source methods. To address this, we propose HiMemVLN, which incorporates a Hierarchical Memory System into a multimodal large model to enhance visual perception recall and long-term localization, mitigating the amnesia issue and improving the agent's navigation performance. Extensive experiments in both simulated and real-world environments demonstrate that HiMemVLN achieves nearly twice the performance of the open-source state-of-the-art method. The code is available at https://github.com/lvkailin0118/HiMemVLN.
Wild-Drive: Off-Road Scene Captioning and Path Planning via Robust Multi-modal Routing and Efficient Large Language Model
Feb 28, 2026Explainability and transparent decision-making are essential for the safe deployment of autonomous driving systems. Scene captioning summarizes environmental conditions and risk factors in natural language, improving transparency, safety, and human--robot interaction. However, most existing approaches target structured urban scenarios; in off-road environments, they are vulnerable to single-modality degradations caused by rain, fog, snow, and darkness, and they lack a unified framework that jointly models structured scene captioning and path planning. To bridge this gap, we propose Wild-Drive, an efficient framework for off-road scene captioning and path planning. Wild-Drive adopts modern multimodal encoders and introduces a task-conditioned modality-routing bridge, MoRo-Former, to adaptively aggregate reliable information under degraded sensing. It then integrates an efficient large language model (LLM), together with a planning token and a gate recurrent unit (GRU) decoder, to generate structured captions and predict future trajectories. We also build the OR-C2P Benchmark, which covers structured off-road scene captioning and path planning under diverse sensor corruption conditions. Experiments on OR-C2P dataset and a self-collected dataset show that Wild-Drive outperforms prior LLM-based methods and remains more stable under degraded sensing. The code and benchmark will be publicly available at https://github.com/wangzihanggg/Wild-Drive.
Automating Hardware Design and Verification from Architectural Papers via a Neural-Symbolic Graph Framework
Nov 08, 2025The reproduction of hardware architectures from academic papers remains a significant challenge due to the lack of publicly available source code and the complexity of hardware description languages (HDLs). To this end, we propose \textbf{ArchCraft}, a Framework that converts abstract architectural descriptions from academic papers into synthesizable Verilog projects with register-transfer level (RTL) verification. ArchCraft introduces a structured workflow, which uses formal graphs to capture the Architectural Blueprint and symbols to define the Functional Specification, translating unstructured academic papers into verifiable, hardware-aware designs. The framework then generates RTL and testbench (TB) code decoupled via these symbols to facilitate verification and debugging, ultimately reporting the circuit's Power, Area, and Performance (PPA). Moreover, we propose the first benchmark, \textbf{ArchSynthBench}, for synthesizing hardware from architectural descriptions, with a complete set of evaluation indicators, 50 project-level circuits, and around 600 circuit blocks. We systematically assess ArchCraft on ArchSynthBench, where the experiment results demonstrate the superiority of our proposed method, surpassing direct generation methods and the VerilogCoder framework in both paper understanding and code completion. Furthermore, evaluation and physical implementation of the generated executable RTL code show that these implementations meet all timing constraints without violations, and their performance metrics are consistent with those reported in the original papers.
A Challenging Benchmark of Anime Style Recognition
Apr 29, 2022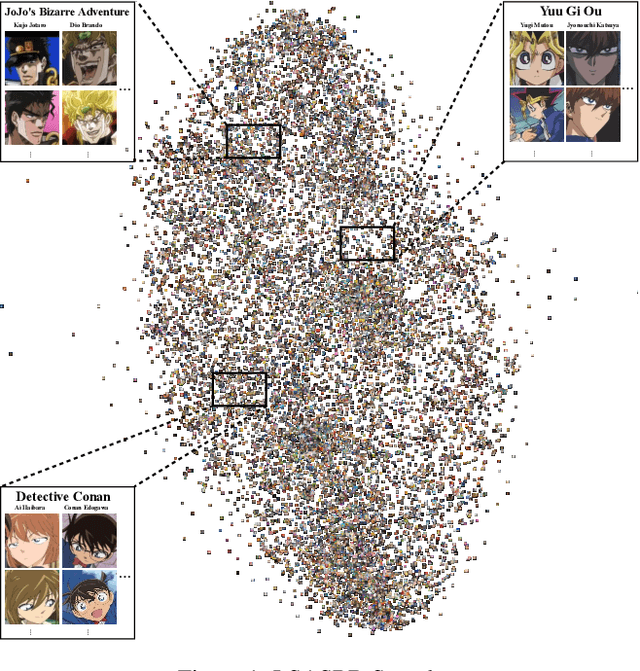


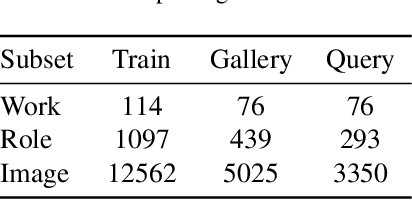
Given two images of different anime roles, anime style recognition (ASR) aims to learn abstract painting style to determine whether the two images are from the same work, which is an interesting but challenging problem. Unlike biometric recognition, such as face recognition, iris recognition, and person re-identification, ASR suffers from a much larger semantic gap but receives less attention. In this paper, we propose a challenging ASR benchmark. Firstly, we collect a large-scale ASR dataset (LSASRD), which contains 20,937 images of 190 anime works and each work at least has ten different roles. In addition to the large-scale, LSASRD contains a list of challenging factors, such as complex illuminations, various poses, theatrical colors and exaggerated compositions. Secondly, we design a cross-role protocol to evaluate ASR performance, in which query and gallery images must come from different roles to validate an ASR model is to learn abstract painting style rather than learn discriminative features of roles. Finally, we apply two powerful person re-identification methods, namely, AGW and TransReID, to construct the baseline performance on LSASRD. Surprisingly, the recent transformer model (i.e., TransReID) only acquires a 42.24% mAP on LSASRD. Therefore, we believe that the ASR task of a huge semantic gap deserves deep and long-term research. We will open our dataset and code at https://github.com/nkjcqvcpi/ASR.