 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToken Expand-Merge: Training-Free Token Compression for Vision-Language-Action Models
Dec 10, 2025Vision-Language-Action (VLA) models pretrained on large-scale multimodal datasets have emerged as powerful foundations for robotic perception and control. However, their massive scale, often billions of parameters, poses significant challenges for real-time deployment, as inference becomes computationally expensive and latency-sensitive in dynamic environments. To address this, we propose Token Expand-and-Merge-VLA (TEAM-VLA), a training-free token compression framework that accelerates VLA inference while preserving task performance. TEAM-VLA introduces a dynamic token expansion mechanism that identifies and samples additional informative tokens in the spatial vicinity of attention-highlighted regions, enhancing contextual completeness. These expanded tokens are then selectively merged in deeper layers under action-aware guidance, effectively reducing redundancy while maintaining semantic coherence. By coupling expansion and merging within a single feed-forward pass, TEAM-VLA achieves a balanced trade-off between efficiency and effectiveness, without any retraining or parameter updates. Extensive experiments on LIBERO benchmark demonstrate that TEAM-VLA consistently improves inference speed while maintaining or even surpassing the task success rate of full VLA models. The code is public available on \href{https://github.com/Jasper-aaa/TEAM-VLA}{https://github.com/Jasper-aaa/TEAM-VLA}
NeuralHDHair: Automatic High-fidelity Hair Modeling from a Single Image Using Implicit Neural Representations
May 09, 2022

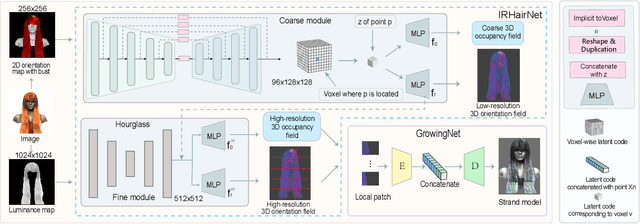

Undoubtedly, high-fidelity 3D hair plays an indispensable role in digital humans. However, existing monocular hair modeling methods are either tricky to deploy in digital systems (e.g., due to their dependence on complex user interactions or large databases) or can produce only a coarse geometry. In this paper, we introduce NeuralHDHair, a flexible, fully automatic system for modeling high-fidelity hair from a single image. The key enablers of our system are two carefully designed neural networks: an IRHairNet (Implicit representation for hair using neural network) for inferring high-fidelity 3D hair geometric features (3D orientation field and 3D occupancy field) hierarchically and a GrowingNet(Growing hair strands using neural network) to efficiently generate 3D hair strands in parallel. Specifically, we perform a coarse-to-fine manner and propose a novel voxel-aligned implicit function (VIFu) to represent the global hair feature, which is further enhanced by the local details extracted from a hair luminance map. To improve the efficiency of a traditional hair growth algorithm, we adopt a local neural implicit function to grow strands based on the estimated 3D hair geometric features. Extensive experiments show that our method is capable of constructing a high-fidelity 3D hair model from a single image, both efficiently and effectively, and achieves the-state-of-the-art performance.