 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTouchThinker: Scaling Tactile Commonsense Reasoning to the Open World with Large-scale Data and Action-aware Representation
Jun 10, 2026Touch is a key modality for embodied agents to understand the physical world. Although recent work has incorporated tactile signals into language systems for tactile commonsense reasoning, scaling such systems to realistic open-world settings remains challenging due to two key bottlenecks: (1) current tactile reasoning datasets remain limited in format and scale, providing insufficient supervision for reasoning from tactile observations to physical commonsense and hindering the learning of transferable tactile commonsense; (2) Tactile signals are inherently redundant and action-specific, yet existing methods often overlook these properties, resulting in inefficient representations with limited semantic expressiveness. To address these limitations, we propose TouchThinker, a tactile-language framework that scales tactile commonsense reasoning to the open world from both data and representation perspectives. First, we construct TouchThinker-1M, a million-scale, multi-source tactile reasoning dataset covering \textbf{415} objects, \textbf{8} scenarios, and \textbf{7} sensor types, providing a solid data foundation for open-world generalization. We further introduce TouchThinker-Bench, an open-world benchmark with more realistic and diverse tasks. Then, we propose action-aware modeling mechanism to improve tactile representation efficiency and enable efficient reasoning. Experimental results demonstrate that TouchThinker achieves competitive performance against state-of-the-art models across multiple datasets. Our code and dataset will be made available at: https://github.com/lvkailin0118/TouchThinker.
TVI-CoT: Text-Visual Interleaved Chain-of-Thought Reasoning for Multimodal Understanding
Jun 07, 2026Chain-of-thought (CoT) reasoning has proven effective for enhancing problem-solving in large language models. However, when applied to multimodal LLMs (MLLMs), existing CoT approaches suffer from a fundamental limitation: they perform reasoning entirely in text without accessing visual features during the reasoning process. After initial visual encoding, image information becomes inaccessible, forcing models to reason based solely on whatever was captured in the initial description, which forms a `vision-blind reasoning' paradigm that limits fine-grained visual extraction, error verification, and adaptive attention. We propose Text-Visual Interleaved Chain-of-Thought (TVI-CoT), a framework that enables explicit interleaving of textual reasoning and visual feature access through learnable control tokens <THINK>, <LOOK> and <ANSWER>. These tokens allow dynamic switching between reasoning and visual grounding, attending to relevant image regions conditioned on the evolving reasoning state. Experiments on eight benchmarks demonstrate state-of-the-art results among MLLM-based CoT methods and notable performance boost compared to the baseline: +6.1% on MMMU, +3.8% on MathVerse, +3.4% on MathVista, and +3.4% on ScienceQA. Code is available at https://github.com/hulianyuyy/TVI-CoT.
PhotoCraft: Agentic Reasoning with Hierarchical Self-Evolving Memory for Deep Image Search
Jun 02, 2026Deep Image Search requires multi-step reasoning over rich contextual cues, such as time, location, and event relations. However, most existing LLM-based agents are stateless and reactive, lacking persistent memory to maintain long-horizon context or transfer experience across tasks, which often leads to execution drift and experience isolation. To address these limitations, we propose PhotoCraft, a training-free, hierarchical memory system for photo-search agents. Inspired by human cognition, PhotoCraft equips MLLMs with working, episodic, and semantic memory, which are dynamically invoked during reasoning to preserve logical consistency and knowledge transferability throughout multi-step reasoning and answer generation. Extensive experiments on DISBench demonstrate that PhotoCraft consistently improves context-aware retrieval across diverse MLLM backbones, achieving gains of up to 18.5\% and effectively mitigating key bottlenecks in memoryless deep image search, offering a practical path toward reliable and generalizable multimodal search agents.
Reading Between the Pixels: An Inscriptive Jailbreak Attack on Text-to-Image Models
Apr 07, 2026Modern text-to-image (T2I) models can now render legible, paragraph-length text, enabling a fundamentally new class of misuse. We identify and formalize the inscriptive jailbreak, where an adversary coerces a T2I system into generating images containing harmful textual payloads (e.g., fraudulent documents) embedded within visually benign scenes. Unlike traditional depictive jailbreaks that elicit visually objectionable imagery, inscriptive attacks weaponize the text-rendering capability itself. Because existing jailbreak techniques are designed for coarse visual manipulation, they struggle to bypass multi-stage safety filters while maintaining character-level fidelity. To expose this vulnerability, we propose Etch, a black-box attack framework that decomposes the adversarial prompt into three functionally orthogonal layers: semantic camouflage, visual-spatial anchoring, and typographic encoding. This decomposition reduces joint optimization over the full prompt space to tractable sub-problems, which are iteratively refined through a zero-order loop. In this process, a vision-language model critiques each generated image, localizes failures to specific layers, and prescribes targeted revisions. Extensive evaluations across 7 models on the 2 benchmarks demonstrate that Etch achieves an average attack success rate of 65.57% (peaking at 91.00%), significantly outperforming existing baselines. Our results reveal a critical blind spot in current T2I safety alignments and underscore the urgent need for typography-aware defense multimodal mechanisms.
TennisExpert: Towards Expert-Level Analytical Sports Video Understanding
Mar 17, 2026Tennis is one of the most widely followed sports, generating extensive broadcast footage with strong potential for professional analysis, automated coaching, and real-time commentary. However, automatic tennis understanding remains underexplored due to two key challenges: (1) the lack of large-scale benchmarks with fine-grained annotations and expert-level commentary, and (2) the difficulty of building accurate yet efficient multimodal systems suitable for real-time deployment. To address these challenges, we introduce TennisVL, a large-scale tennis benchmark comprising over 200 professional matches (471.9 hours) and 40,000+ rally-level clips. Unlike existing commentary datasets that focus on descriptive play-by-play narration, TennisVL emphasizes expert analytical commentary capturing tactical reasoning, player decisions, and match momentum. Furthermore, we propose TennisExpert, a multimodal tennis understanding framework that integrates a video semantic parser with a memory-augmented model built on Qwen3-VL-8B. The parser extracts key match elements (e.g., scores, shot sequences, ball bounces, and player locations), while hierarchical memory modules capture both short- and long-term temporal context. Experiments show that TennisExpert consistently outperforms strong proprietary baselines, including GPT-5, Gemini, and Claude, and demonstrates improved ability to capture tactical context and match dynamics. Our dataset and code are publicly available at https://github.com/LZYAndy/TennisExpert.
HiMemVLN: Enhancing Reliability of Open-Source Zero-Shot Vision-and-Language Navigation with Hierarchical Memory System
Mar 16, 2026LLM-based agents have demonstrated impressive zero-shot performance in vision-language navigation (VLN) tasks. However, most zero-shot methods primarily rely on closed-source LLMs as navigators, which face challenges related to high token costs and potential data leakage risks. Recent efforts have attempted to address this by using open-source LLMs combined with a spatiotemporal CoT framework, but they still fall far short compared to closed-source models. In this work, we identify a critical issue, Navigation Amnesia, through a detailed analysis of the navigation process. This issue leads to navigation failures and amplifies the gap between open-source and closed-source methods. To address this, we propose HiMemVLN, which incorporates a Hierarchical Memory System into a multimodal large model to enhance visual perception recall and long-term localization, mitigating the amnesia issue and improving the agent's navigation performance. Extensive experiments in both simulated and real-world environments demonstrate that HiMemVLN achieves nearly twice the performance of the open-source state-of-the-art method. The code is available at https://github.com/lvkailin0118/HiMemVLN.
SSL-SSAW: Self-Supervised Learning with Sigmoid Self-Attention Weighting for Question-Based Sign Language Translation
Sep 17, 2025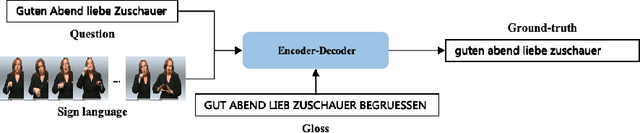
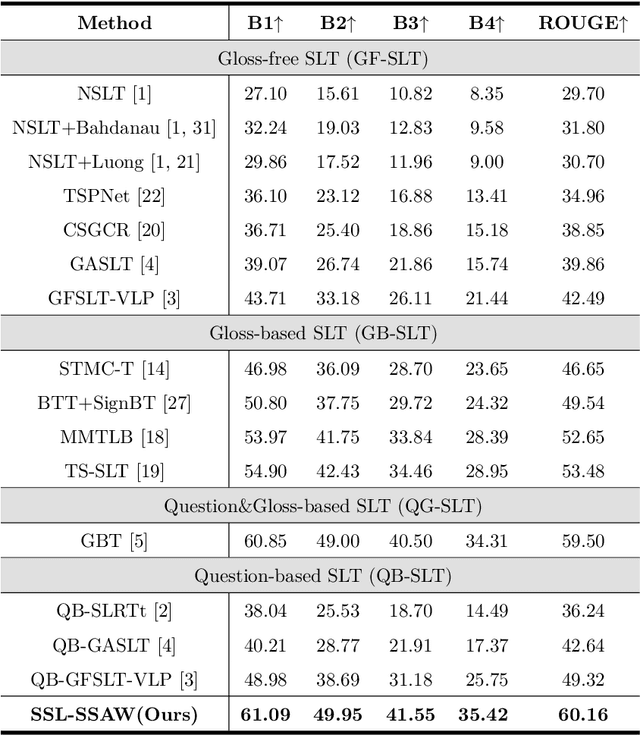
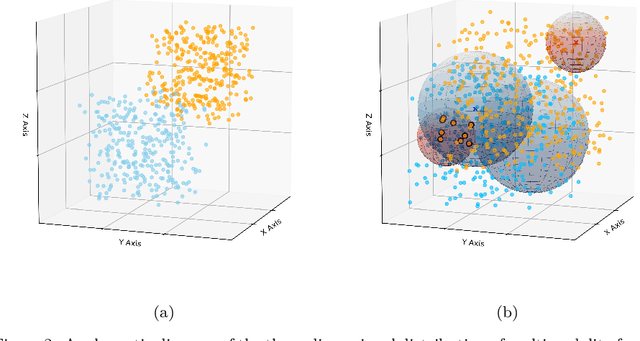
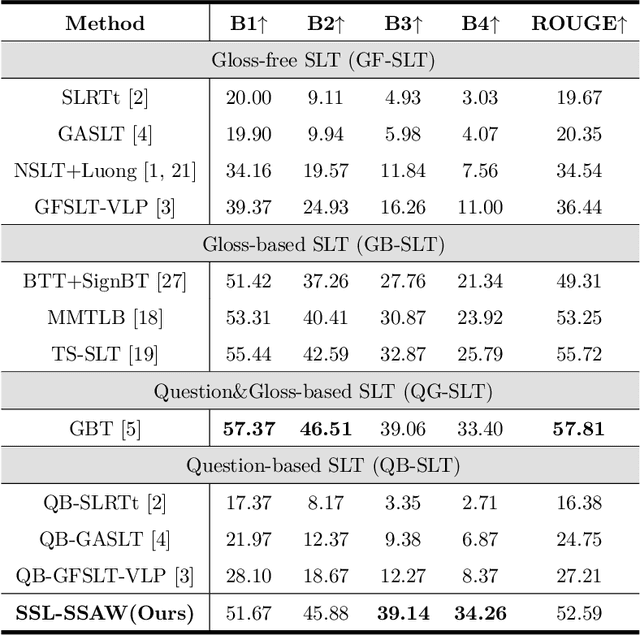
Sign Language Translation (SLT) bridges the communication gap between deaf people and hearing people, where dialogue provides crucial contextual cues to aid in translation. Building on this foundational concept, this paper proposes Question-based Sign Language Translation (QB-SLT), a novel task that explores the efficient integration of dialogue. Unlike gloss (sign language transcription) annotations, dialogue naturally occurs in communication and is easier to annotate. The key challenge lies in aligning multimodality features while leveraging the context of the question to improve translation. To address this issue, we propose a cross-modality Self-supervised Learning with Sigmoid Self-attention Weighting (SSL-SSAW) fusion method for sign language translation. Specifically, we employ contrastive learning to align multimodality features in QB-SLT, then introduce a Sigmoid Self-attention Weighting (SSAW) module for adaptive feature extraction from question and sign language sequences. Additionally, we leverage available question text through self-supervised learning to enhance representation and translation capabilities. We evaluated our approach on newly constructed CSL-Daily-QA and PHOENIX-2014T-QA datasets, where SSL-SSAW achieved SOTA performance. Notably, easily accessible question assistance can achieve or even surpass the performance of gloss assistance. Furthermore, visualization results demonstrate the effectiveness of incorporating dialogue in improving translation quality.
Adversarial Fair Multi-View Clustering
Aug 06, 2025Cluster analysis is a fundamental problem in data mining and machine learning. In recent years, multi-view clustering has attracted increasing attention due to its ability to integrate complementary information from multiple views. However, existing methods primarily focus on clustering performance, while fairness-a critical concern in human-centered applications-has been largely overlooked. Although recent studies have explored group fairness in multi-view clustering, most methods impose explicit regularization on cluster assignments, relying on the alignment between sensitive attributes and the underlying cluster structure. However, this assumption often fails in practice and can degrade clustering performance. In this paper, we propose an adversarial fair multi-view clustering (AFMVC) framework that integrates fairness learning into the representation learning process. Specifically, our method employs adversarial training to fundamentally remove sensitive attribute information from learned features, ensuring that the resulting cluster assignments are unaffected by it. Furthermore, we theoretically prove that aligning view-specific clustering assignments with a fairness-invariant consensus distribution via KL divergence preserves clustering consistency without significantly compromising fairness, thereby providing additional theoretical guarantees for our framework. Extensive experiments on data sets with fairness constraints demonstrate that AFMVC achieves superior fairness and competitive clustering performance compared to existing multi-view clustering and fairness-aware clustering methods.
Interpretable Clustering Ensemble
Jun 06, 2025Clustering ensemble has emerged as an important research topic in the field of machine learning. Although numerous methods have been proposed to improve clustering quality, most existing approaches overlook the need for interpretability in high-stakes applications. In domains such as medical diagnosis and financial risk assessment, algorithms must not only be accurate but also interpretable to ensure transparent and trustworthy decision-making. Therefore, to fill the gap of lack of interpretable algorithms in the field of clustering ensemble, we propose the first interpretable clustering ensemble algorithm in the literature. By treating base partitions as categorical variables, our method constructs a decision tree in the original feature space and use the statistical association test to guide the tree building process. Experimental results demonstrate that our algorithm achieves comparable performance to state-of-the-art (SOTA) clustering ensemble methods while maintaining an additional feature of interpretability. To the best of our knowledge, this is the first interpretable algorithm specifically designed for clustering ensemble, offering a new perspective for future research in interpretable clustering.
iLLaVA: An Image is Worth Fewer Than 1/3 Input Tokens in Large Multimodal Models
Dec 09, 2024



In this paper, we introduce iLLaVA, a simple method that can be seamlessly deployed upon current Large Vision-Language Models (LVLMs) to greatly increase the throughput with nearly lossless model performance, without a further requirement to train. iLLaVA achieves this by finding and gradually merging the redundant tokens with an accurate and fast algorithm, which can merge hundreds of tokens within only one step. While some previous methods have explored directly pruning or merging tokens in the inference stage to accelerate models, our method excels in both performance and throughput by two key designs. First, while most previous methods only try to save the computations of Large Language Models (LLMs), our method accelerates the forward pass of both image encoders and LLMs in LVLMs, which both occupy a significant part of time during inference. Second, our method recycles the beneficial information from the pruned tokens into existing tokens, which avoids directly dropping context tokens like previous methods to cause performance loss. iLLaVA can nearly 2$\times$ the throughput, and reduce the memory costs by half with only a 0.2\% - 0.5\% performance drop across models of different scales including 7B, 13B and 34B. On tasks across different domains including single-image, multi-images and videos, iLLaVA demonstrates strong generalizability with consistently promising efficiency. We finally offer abundant visualizations to show the merging processes of iLLaVA in each step, which show insights into the distribution of computing resources in LVLMs. Code is available at https://github.com/hulianyuyy/iLLaVA.