 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Depth Completion Model from Sparse Observations
May 28, 2026This work presents the Large Depth Completion Model (LDCM), a simple, effective, and robust framework for single-view metric depth estimation with sparse observations. Without relying on complex architectural designs, LDCM generates metric-accurate dense depth maps using a transformer. It outperforms existing approaches across diverse datasets and sparse observations. We achieve this from two key perspectives: (1) leveraging existing monocular foundation models to improve the quality of sparse depth inputs, and (2) reformulating training objectives to better capture geometric structure and metric consistency. Specifically, a Poisson-based depth initialization strategy is first introduced to generate a uniform coarse dense depth map from diverse sparse observations, providing a strong structural prior for the network. Regarding the training objective, we replace the conventional depth head with a point map head that regresses per-pixel 3D coordinates in camera space, enabling the model to directly learn the underlying 3D scene structure instead of performing pixel-wise depth map restoration. Moreover, this design eliminates the need for camera intrinsic parameters, allowing LDCM to naturally produce metric-scaled 3D point maps. Extensive experiments demonstrate that LDCM consistently outperforms state-of-the-art methods across multiple benchmarks and varying sparsity levels in both depth completion and point map estimation, showcasing its effectiveness and strong generalization to unseen data distributions.
Condition Matters in Full-head 3D GANs
Feb 06, 2026Conditioning is crucial for stable training of full-head 3D GANs. Without any conditioning signal, the model suffers from severe mode collapse, making it impractical to training. However, a series of previous full-head 3D GANs conventionally choose the view angle as the conditioning input, which leads to a bias in the learned 3D full-head space along the conditional view direction. This is evident in the significant differences in generation quality and diversity between the conditional view and non-conditional views of the generated 3D heads, resulting in global incoherence across different head regions. In this work, we propose to use view-invariant semantic feature as the conditioning input, thereby decoupling the generative capability of 3D heads from the viewing direction. To construct a view-invariant semantic condition for each training image, we create a novel synthesized head image dataset. We leverage FLUX.1 Kontext to extend existing high-quality frontal face datasets to a wide range of view angles. The image clip feature extracted from the frontal view is then used as a shared semantic condition across all views in the extended images, ensuring semantic alignment while eliminating directional bias. This also allows supervision from different views of the same subject to be consolidated under a shared semantic condition, which accelerates training and enhances the global coherence of the generated 3D heads. Moreover, as GANs often experience slower improvements in diversity once the generator learns a few modes that successfully fool the discriminator, our semantic conditioning encourages the generator to follow the true semantic distribution, thereby promoting continuous learning and diverse generation. Extensive experiments on full-head synthesis and single-view GAN inversion demonstrate that our method achieves significantly higher fidelity, diversity, and generalizability.
Prompt Reinjection: Alleviating Prompt Forgetting in Multimodal Diffusion Transformers
Feb 06, 2026Multimodal Diffusion Transformers (MMDiTs) for text-to-image generation maintain separate text and image branches, with bidirectional information flow between text tokens and visual latents throughout denoising. In this setting, we observe a prompt forgetting phenomenon: the semantics of the prompt representation in the text branch is progressively forgotten as depth increases. We further verify this effect on three representative MMDiTs--SD3, SD3.5, and FLUX.1 by probing linguistic attributes of the representations over the layers in the text branch. Motivated by these findings, we introduce a training-free approach, prompt reinjection, which reinjects prompt representations from early layers into later layers to alleviate this forgetting. Experiments on GenEval, DPG, and T2I-CompBench++ show consistent gains in instruction-following capability, along with improvements on metrics capturing preference, aesthetics, and overall text--image generation quality.
WebSplatter: Enabling Cross-Device Efficient Gaussian Splatting in Web Browsers via WebGPU
Feb 03, 2026We present WebSplatter, an end-to-end GPU rendering pipeline for the heterogeneous web ecosystem. Unlike naive ports, WebSplatter introduces a wait-free hierarchical radix sort that circumvents the lack of global atomics in WebGPU, ensuring deterministic execution across diverse hardware. Furthermore, we propose an opacity-aware geometry culling stage that dynamically prunes splats before rasterization, significantly reducing overdraw and peak memory footprint. Evaluation demonstrates that WebSplatter consistently achieves 1.2$\times$ to 4.5$\times$ speedups over state-of-the-art web viewers.
OmniMotion: Multimodal Motion Generation with Continuous Masked Autoregression
Oct 16, 2025


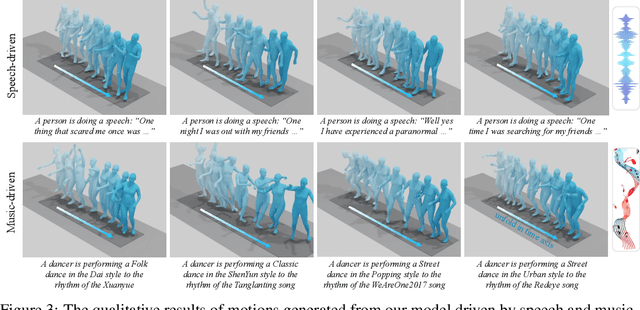
Whole-body multi-modal human motion generation poses two primary challenges: creating an effective motion generation mechanism and integrating various modalities, such as text, speech, and music, into a cohesive framework. Unlike previous methods that usually employ discrete masked modeling or autoregressive modeling, we develop a continuous masked autoregressive motion transformer, where a causal attention is performed considering the sequential nature within the human motion. Within this transformer, we introduce a gated linear attention and an RMSNorm module, which drive the transformer to pay attention to the key actions and suppress the instability caused by either the abnormal movements or the heterogeneous distributions within multi-modalities. To further enhance both the motion generation and the multimodal generalization, we employ the DiT structure to diffuse the conditions from the transformer towards the targets. To fuse different modalities, AdaLN and cross-attention are leveraged to inject the text, speech, and music signals. Experimental results demonstrate that our framework outperforms previous methods across all modalities, including text-to-motion, speech-to-gesture, and music-to-dance. The code of our method will be made public.
PanoLAM: Large Avatar Model for Gaussian Full-Head Synthesis from One-shot Unposed Image
Sep 09, 2025



We present a feed-forward framework for Gaussian full-head synthesis from a single unposed image. Unlike previous work that relies on time-consuming GAN inversion and test-time optimization, our framework can reconstruct the Gaussian full-head model given a single unposed image in a single forward pass. This enables fast reconstruction and rendering during inference. To mitigate the lack of large-scale 3D head assets, we propose a large-scale synthetic dataset from trained 3D GANs and train our framework using only synthetic data. For efficient high-fidelity generation, we introduce a coarse-to-fine Gaussian head generation pipeline, where sparse points from the FLAME model interact with the image features by transformer blocks for feature extraction and coarse shape reconstruction, which are then densified for high-fidelity reconstruction. To fully leverage the prior knowledge residing in pretrained 3D GANs for effective reconstruction, we propose a dual-branch framework that effectively aggregates the structured spherical triplane feature and unstructured point-based features for more effective Gaussian head reconstruction. Experimental results show the effectiveness of our framework towards existing work.
DicFace: Dirichlet-Constrained Variational Codebook Learning for Temporally Coherent Video Face Restoration
Jun 16, 2025



Video face restoration faces a critical challenge in maintaining temporal consistency while recovering fine facial details from degraded inputs. This paper presents a novel approach that extends Vector-Quantized Variational Autoencoders (VQ-VAEs), pretrained on static high-quality portraits, into a video restoration framework through variational latent space modeling. Our key innovation lies in reformulating discrete codebook representations as Dirichlet-distributed continuous variables, enabling probabilistic transitions between facial features across frames. A spatio-temporal Transformer architecture jointly models inter-frame dependencies and predicts latent distributions, while a Laplacian-constrained reconstruction loss combined with perceptual (LPIPS) regularization enhances both pixel accuracy and visual quality. Comprehensive evaluations on blind face restoration, video inpainting, and facial colorization tasks demonstrate state-of-the-art performance. This work establishes an effective paradigm for adapting intensive image priors, pretrained on high-quality images, to video restoration while addressing the critical challenge of flicker artifacts. The source code has been open-sourced and is available at https://github.com/fudan-generative-vision/DicFace.
PF-LHM: 3D Animatable Avatar Reconstruction from Pose-free Articulated Human Images
Jun 16, 2025Reconstructing an animatable 3D human from casually captured images of an articulated subject without camera or human pose information is a practical yet challenging task due to view misalignment, occlusions, and the absence of structural priors. While optimization-based methods can produce high-fidelity results from monocular or multi-view videos, they require accurate pose estimation and slow iterative optimization, limiting scalability in unconstrained scenarios. Recent feed-forward approaches enable efficient single-image reconstruction but struggle to effectively leverage multiple input images to reduce ambiguity and improve reconstruction accuracy. To address these challenges, we propose PF-LHM, a large human reconstruction model that generates high-quality 3D avatars in seconds from one or multiple casually captured pose-free images. Our approach introduces an efficient Encoder-Decoder Point-Image Transformer architecture, which fuses hierarchical geometric point features and multi-view image features through multimodal attention. The fused features are decoded to recover detailed geometry and appearance, represented using 3D Gaussian splats. Extensive experiments on both real and synthetic datasets demonstrate that our method unifies single- and multi-image 3D human reconstruction, achieving high-fidelity and animatable 3D human avatars without requiring camera and human pose annotations. Code and models will be released to the public.
Hallo4: High-Fidelity Dynamic Portrait Animation via Direct Preference Optimization and Temporal Motion Modulation
May 29, 2025Generating highly dynamic and photorealistic portrait animations driven by audio and skeletal motion remains challenging due to the need for precise lip synchronization, natural facial expressions, and high-fidelity body motion dynamics. We propose a human-preference-aligned diffusion framework that addresses these challenges through two key innovations. First, we introduce direct preference optimization tailored for human-centric animation, leveraging a curated dataset of human preferences to align generated outputs with perceptual metrics for portrait motion-video alignment and naturalness of expression. Second, the proposed temporal motion modulation resolves spatiotemporal resolution mismatches by reshaping motion conditions into dimensionally aligned latent features through temporal channel redistribution and proportional feature expansion, preserving the fidelity of high-frequency motion details in diffusion-based synthesis. The proposed mechanism is complementary to existing UNet and DiT-based portrait diffusion approaches, and experiments demonstrate obvious improvements in lip-audio synchronization, expression vividness, body motion coherence over baseline methods, alongside notable gains in human preference metrics. Our model and source code can be found at: https://github.com/xyz123xyz456/hallo4.
CoProSketch: Controllable and Progressive Sketch Generation with Diffusion Model
Apr 11, 2025
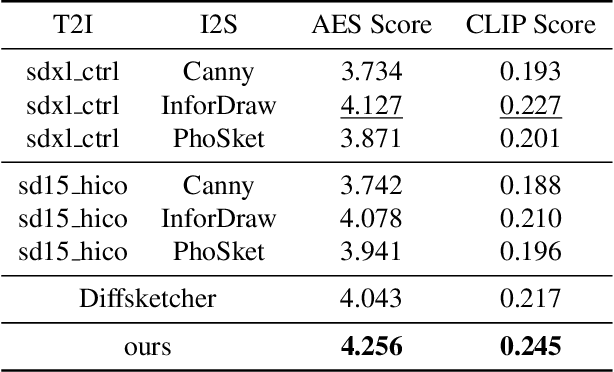
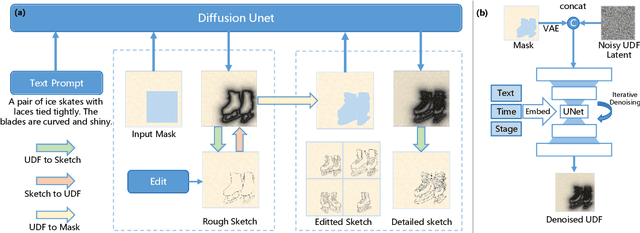
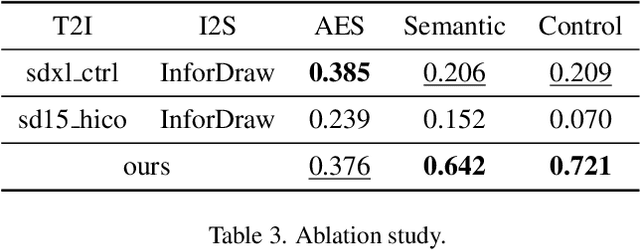
Sketches serve as fundamental blueprints in artistic creation because sketch editing is easier and more intuitive than pixel-level RGB image editing for painting artists, yet sketch generation remains unexplored despite advancements in generative models. We propose a novel framework CoProSketch, providing prominent controllability and details for sketch generation with diffusion models. A straightforward method is fine-tuning a pretrained image generation diffusion model with binarized sketch images. However, we find that the diffusion models fail to generate clear binary images, which makes the produced sketches chaotic. We thus propose to represent the sketches by unsigned distance field (UDF), which is continuous and can be easily decoded to sketches through a lightweight network. With CoProSketch, users generate a rough sketch from a bounding box and a text prompt. The rough sketch can be manually edited and fed back into the model for iterative refinement and will be decoded to a detailed sketch as the final result. Additionally, we curate the first large-scale text-sketch paired dataset as the training data. Experiments demonstrate superior semantic consistency and controllability over baselines, offering a practical solution for integrating user feedback into generative workflows.