 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-rewarding correction for mathematical reasoning
Feb 26, 2025We study self-rewarding reasoning large language models (LLMs), which can simultaneously generate step-by-step reasoning and evaluate the correctness of their outputs during the inference time-without external feedback. This integrated approach allows a single model to independently guide its reasoning process, offering computational advantages for model deployment. We particularly focus on the representative task of self-correction, where models autonomously detect errors in their responses, revise outputs, and decide when to terminate iterative refinement loops. To enable this, we propose a two-staged algorithmic framework for constructing self-rewarding reasoning models using only self-generated data. In the first stage, we employ sequential rejection sampling to synthesize long chain-of-thought trajectories that incorporate both self-rewarding and self-correction mechanisms. Fine-tuning models on these curated data allows them to learn the patterns of self-rewarding and self-correction. In the second stage, we further enhance the models' ability to assess response accuracy and refine outputs through reinforcement learning with rule-based signals. Experiments with Llama-3 and Qwen-2.5 demonstrate that our approach surpasses intrinsic self-correction capabilities and achieves performance comparable to systems that rely on external reward models.
Can LLMs Simulate Social Media Engagement? A Study on Action-Guided Response Generation
Feb 17, 2025



Social media enables dynamic user engagement with trending topics, and recent research has explored the potential of large language models (LLMs) for response generation. While some studies investigate LLMs as agents for simulating user behavior on social media, their focus remains on practical viability and scalability rather than a deeper understanding of how well LLM aligns with human behavior. This paper analyzes LLMs' ability to simulate social media engagement through action guided response generation, where a model first predicts a user's most likely engagement action-retweet, quote, or rewrite-towards a trending post before generating a personalized response conditioned on the predicted action. We benchmark GPT-4o-mini, O1-mini, and DeepSeek-R1 in social media engagement simulation regarding a major societal event discussed on X. Our findings reveal that zero-shot LLMs underperform BERT in action prediction, while few-shot prompting initially degrades the prediction accuracy of LLMs with limited examples. However, in response generation, few-shot LLMs achieve stronger semantic alignment with ground truth posts.
Logarithmic Regret for Online KL-Regularized Reinforcement Learning
Feb 11, 2025
Recent advances in Reinforcement Learning from Human Feedback (RLHF) have shown that KL-regularization plays a pivotal role in improving the efficiency of RL fine-tuning for large language models (LLMs). Despite its empirical advantage, the theoretical difference between KL-regularized RL and standard RL remains largely under-explored. While there is a recent line of work on the theoretical analysis of KL-regularized objective in decision making \citep{xiong2024iterative, xie2024exploratory,zhao2024sharp}, these analyses either reduce to the traditional RL setting or rely on strong coverage assumptions. In this paper, we propose an optimism-based KL-regularized online contextual bandit algorithm, and provide a novel analysis of its regret. By carefully leveraging the benign optimization landscape induced by the KL-regularization and the optimistic reward estimation, our algorithm achieves an $\mathcal{O}\big(\eta\log (N_{\mathcal R} T)\cdot d_{\mathcal R}\big)$ logarithmic regret bound, where $\eta, N_{\mathcal R},T,d_{\mathcal R}$ denote the KL-regularization parameter, the cardinality of the reward function class, number of rounds, and the complexity of the reward function class. Furthermore, we extend our algorithm and analysis to reinforcement learning by developing a novel decomposition over transition steps and also obtain a similar logarithmic regret bound.
Motion Forecasting for Autonomous Vehicles: A Survey
Feb 10, 2025In recent years, the field of autonomous driving has attracted increasingly significant public interest. Accurately forecasting the future behavior of various traffic participants is essential for the decision-making of Autonomous Vehicles (AVs). In this paper, we focus on both scenario-based and perception-based motion forecasting for AVs. We propose a formal problem formulation for motion forecasting and summarize the main challenges confronting this area of research. We also detail representative datasets and evaluation metrics pertinent to this field. Furthermore, this study classifies recent research into two main categories: supervised learning and self-supervised learning, reflecting the evolving paradigms in both scenario-based and perception-based motion forecasting. In the context of supervised learning, we thoroughly examine and analyze each key element of the methodology. For self-supervised learning, we summarize commonly adopted techniques. The paper concludes and discusses potential research directions, aiming to propel progress in this vital area of AV technology.
LLM Alignment as Retriever Optimization: An Information Retrieval Perspective
Feb 06, 2025



Large Language Models (LLMs) have revolutionized artificial intelligence with capabilities in reasoning, coding, and communication, driving innovation across industries. Their true potential depends on effective alignment to ensure correct, trustworthy and ethical behavior, addressing challenges like misinformation, hallucinations, bias and misuse. While existing Reinforcement Learning (RL)-based alignment methods are notoriously complex, direct optimization approaches offer a simpler alternative. In this work, we introduce a novel direct optimization approach for LLM alignment by drawing on established Information Retrieval (IR) principles. We present a systematic framework that bridges LLM alignment and IR methodologies, mapping LLM generation and reward models to IR's retriever-reranker paradigm. Building on this foundation, we propose LLM Alignment as Retriever Preference Optimization (LarPO), a new alignment method that enhances overall alignment quality. Extensive experiments validate LarPO's effectiveness with 38.9 % and 13.7 % averaged improvement on AlpacaEval2 and MixEval-Hard respectively. Our work opens new avenues for advancing LLM alignment by integrating IR foundations, offering a promising direction for future research.
EvTTC: An Event Camera Dataset for Time-to-Collision Estimation
Dec 06, 2024Time-to-Collision (TTC) estimation lies in the core of the forward collision warning (FCW) functionality, which is key to all Automatic Emergency Braking (AEB) systems. Although the success of solutions using frame-based cameras (e.g., Mobileye's solutions) has been witnessed in normal situations, some extreme cases, such as the sudden variation in the relative speed of leading vehicles and the sudden appearance of pedestrians, still pose significant risks that cannot be handled. This is due to the inherent imaging principles of frame-based cameras, where the time interval between adjacent exposures introduces considerable system latency to AEB. Event cameras, as a novel bio-inspired sensor, offer ultra-high temporal resolution and can asynchronously report brightness changes at the microsecond level. To explore the potential of event cameras in the above-mentioned challenging cases, we propose EvTTC, which is, to the best of our knowledge, the first multi-sensor dataset focusing on TTC tasks under high-relative-speed scenarios. EvTTC consists of data collected using standard cameras and event cameras, covering various potential collision scenarios in daily driving and involving multiple collision objects. Additionally, LiDAR and GNSS/INS measurements are provided for the calculation of ground-truth TTC. Considering the high cost of testing TTC algorithms on full-scale mobile platforms, we also provide a small-scale TTC testbed for experimental validation and data augmentation. All the data and the design of the testbed are open sourced, and they can serve as a benchmark that will facilitate the development of vision-based TTC techniques.
DIVE: Taming DINO for Subject-Driven Video Editing
Dec 04, 2024



Building on the success of diffusion models in image generation and editing, video editing has recently gained substantial attention. However, maintaining temporal consistency and motion alignment still remains challenging. To address these issues, this paper proposes DINO-guided Video Editing (DIVE), a framework designed to facilitate subject-driven editing in source videos conditioned on either target text prompts or reference images with specific identities. The core of DIVE lies in leveraging the powerful semantic features extracted from a pretrained DINOv2 model as implicit correspondences to guide the editing process. Specifically, to ensure temporal motion consistency, DIVE employs DINO features to align with the motion trajectory of the source video. Extensive experiments on diverse real-world videos demonstrate that our framework can achieve high-quality editing results with robust motion consistency, highlighting the potential of DINO to contribute to video editing. For precise subject editing, DIVE incorporates the DINO features of reference images into a pretrained text-to-image model to learn Low-Rank Adaptations (LoRAs), effectively registering the target subject's identity. Project page: https://dino-video-editing.github.io
MetaShadow: Object-Centered Shadow Detection, Removal, and Synthesis
Dec 03, 2024



Shadows are often under-considered or even ignored in image editing applications, limiting the realism of the edited results. In this paper, we introduce MetaShadow, a three-in-one versatile framework that enables detection, removal, and controllable synthesis of shadows in natural images in an object-centered fashion. MetaShadow combines the strengths of two cooperative components: Shadow Analyzer, for object-centered shadow detection and removal, and Shadow Synthesizer, for reference-based controllable shadow synthesis. Notably, we optimize the learning of the intermediate features from Shadow Analyzer to guide Shadow Synthesizer to generate more realistic shadows that blend seamlessly with the scene. Extensive evaluations on multiple shadow benchmark datasets show significant improvements of MetaShadow over the existing state-of-the-art methods on object-centered shadow detection, removal, and synthesis. MetaShadow excels in image-editing tasks such as object removal, relocation, and insertion, pushing the boundaries of object-centered image editing.
Refine-by-Align: Reference-Guided Artifacts Refinement through Semantic Alignment
Nov 30, 2024


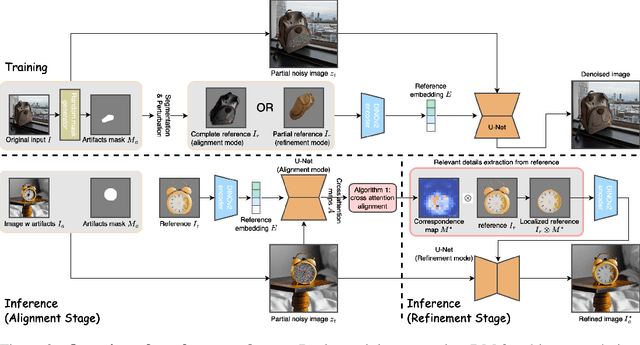
Personalized image generation has emerged from the recent advancements in generative models. However, these generated personalized images often suffer from localized artifacts such as incorrect logos, reducing fidelity and fine-grained identity details of the generated results. Furthermore, there is little prior work tackling this problem. To help improve these identity details in the personalized image generation, we introduce a new task: reference-guided artifacts refinement. We present Refine-by-Align, a first-of-its-kind model that employs a diffusion-based framework to address this challenge. Our model consists of two stages: Alignment Stage and Refinement Stage, which share weights of a unified neural network model. Given a generated image, a masked artifact region, and a reference image, the alignment stage identifies and extracts the corresponding regional features in the reference, which are then used by the refinement stage to fix the artifacts. Our model-agnostic pipeline requires no test-time tuning or optimization. It automatically enhances image fidelity and reference identity in the generated image, generalizing well to existing models on various tasks including but not limited to customization, generative compositing, view synthesis, and virtual try-on. Extensive experiments and comparisons demonstrate that our pipeline greatly pushes the boundary of fine details in the image synthesis models.
From Lists to Emojis: How Format Bias Affects Model Alignment
Sep 18, 2024



In this paper, we study format biases in reinforcement learning from human feedback (RLHF). We observe that many widely-used preference models, including human evaluators, GPT-4, and top-ranking models on the RewardBench benchmark, exhibit strong biases towards specific format patterns, such as lists, links, bold text, and emojis. Furthermore, large language models (LLMs) can exploit these biases to achieve higher rankings on popular benchmarks like AlpacaEval and LMSYS Chatbot Arena. One notable example of this is verbosity bias, where current preference models favor longer responses that appear more comprehensive, even when their quality is equal to or lower than shorter, competing responses. However, format biases beyond verbosity remain largely underexplored in the literature. In this work, we extend the study of biases in preference learning beyond the commonly recognized length bias, offering a comprehensive analysis of a wider range of format biases. Additionally, we show that with a small amount of biased data (less than 1%), we can inject significant bias into the reward model. Moreover, these format biases can also be easily exploited by downstream alignment algorithms, such as best-of-n sampling and online iterative DPO, as it is usually easier to manipulate the format than to improve the quality of responses. Our findings emphasize the need to disentangle format and content both for designing alignment algorithms and evaluating models.