 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMRecover: A Conditional Generative Model for Recovering Motion-Corrupted MR images Using AI Generated Contrast
May 20, 2026Hippocampal subfield segmentation requires high-resolution T2w turbo spin echo (TSE) MRI, yet this sequence is susceptible to motion artifacts, leading to substantial data loss. We developed a conditional generative model (MRecover) that synthesizes routinely acquired T1w images to create TSE images with autoregressive slice conditioning for volumetric consistency. Trained on 7T MRI data (n=577), the model achieved high in-domain fidelity (n=148, SSIM=0.84, FSIM=0.94) and generalized well to out-of-domain 3T data: subfield volumes from synthesized and the as-acquired images closely matched: (n=416, r=0.87-0.97) and yielded 31.8% more analyzable subjects in the motion-affected ADNI3 dataset after quality control (593 vs 450). The synthesized images also achieved larger effect sizes due to increasing the sample size for diagnostic group differences in hippocampal subfield atrophy (whole hippocampus $ε^2$= 0.121-0.100 vs. 0.086-0.062, left-right hemispheres). Project page: https://jinghangli98.github.io/MRecover/
Guide, Think, Act: Interactive Embodied Reasoning in Vision-Language-Action Models
May 13, 2026In this paper, we propose GTA-VLA(Guide, Think, Act), an interactive Vision-Language-Action (VLA) framework that enables spatially steerable embodied reasoning by allowing users to guide robot policies with explicit visual cues. Existing VLA models learn a direct "Sense-to-Act" mapping from multimodal observations to robot actions. While effective within the training distribution, such tightly coupled policies are brittle under out-of-domain (OOD) shifts and difficult to correct when failures occur. Although recent embodied Chain-of-Thought (CoT) approaches expose intermediate reasoning, they still lack a mechanism for incorporating human spatial guidance, limiting their ability to resolve visual ambiguities or recover from mistakes. To address this gap, our framework allows users to optionally guide the policy with spatial priors, such as affordance points, boxes, and traces, which the subsequent reasoning process can directly condition on. Based on these inputs, the model generates a unified spatial-visual Chain-of-Thought that integrates external guidance with internal task planning, aligning human visual intent with autonomous decision-making. For practical deployment, we further couple the reasoning module with a lightweight reactive action head for efficient action execution. Extensive experiments demonstrate the effectiveness of our approach. On the in-domain SimplerEnv WidowX benchmark, our framework achieves a state-of-the-art 81.2% success rate. Under OOD visual shifts and spatial ambiguities, a single visual interaction substantially improves task success over existing methods, highlighting the value of interactive reasoning for failure recovery in embodied control. Details of the project can be found here: https://signalispupupu.github.io/GTA-VLA_ProjPage/
Toward Deep Representation Learning for Event-Enhanced Visual Autonomous Perception: the eAP Dataset
Mar 17, 2026Recent visual autonomous perception systems achieve remarkable performances with deep representation learning. However, they fail in scenarios with challenging illumination.While event cameras can mitigate this problem, there is a lack of a large-scale dataset to develop event-enhanced deep visual perception models in autonomous driving scenes. To address the gap, we present the eAP (event-enhanced Autonomous Perception) dataset, the largest dataset with event cameras for autonomous perception. We demonstrate how eAP can facilitate the study of different autonomous perception tasks, including 3D vehicle detection and object time-to-contact (TTC) estimation, through deep representation learning. Based on eAP, we demonstrate the ffrst successful use of events to improve a popular 3D vehicle detection network in challenging illumination scenarios. eAP also enables a devoted study of the representation learning problem of object TTC estimation. We show how a geometryaware representation learning framework leads to the best eventbased object TTC estimation network that operates at 200 FPS. The dataset, code, and pre-trained models will be made publicly available for future research.
AirGS: Real-Time 4D Gaussian Streaming for Free-Viewpoint Video Experiences
Dec 24, 2025



Free-viewpoint video (FVV) enables immersive viewing experiences by allowing users to view scenes from arbitrary perspectives. As a prominent reconstruction technique for FVV generation, 4D Gaussian Splatting (4DGS) models dynamic scenes with time-varying 3D Gaussian ellipsoids and achieves high-quality rendering via fast rasterization. However, existing 4DGS approaches suffer from quality degradation over long sequences and impose substantial bandwidth and storage overhead, limiting their applicability in real-time and wide-scale deployments. Therefore, we present AirGS, a streaming-optimized 4DGS framework that rearchitects the training and delivery pipeline to enable high-quality, low-latency FVV experiences. AirGS converts Gaussian video streams into multi-channel 2D formats and intelligently identifies keyframes to enhance frame reconstruction quality. It further combines temporal coherence with inflation loss to reduce training time and representation size. To support communication-efficient transmission, AirGS models 4DGS delivery as an integer linear programming problem and design a lightweight pruning level selection algorithm to adaptively prune the Gaussian updates to be transmitted, balancing reconstruction quality and bandwidth consumption. Extensive experiments demonstrate that AirGS reduces quality deviation in PSNR by more than 20% when scene changes, maintains frame-level PSNR consistently above 30, accelerates training by 6 times, reduces per-frame transmission size by nearly 50% compared to the SOTA 4DGS approaches.
EvTTC: An Event Camera Dataset for Time-to-Collision Estimation
Dec 06, 2024Time-to-Collision (TTC) estimation lies in the core of the forward collision warning (FCW) functionality, which is key to all Automatic Emergency Braking (AEB) systems. Although the success of solutions using frame-based cameras (e.g., Mobileye's solutions) has been witnessed in normal situations, some extreme cases, such as the sudden variation in the relative speed of leading vehicles and the sudden appearance of pedestrians, still pose significant risks that cannot be handled. This is due to the inherent imaging principles of frame-based cameras, where the time interval between adjacent exposures introduces considerable system latency to AEB. Event cameras, as a novel bio-inspired sensor, offer ultra-high temporal resolution and can asynchronously report brightness changes at the microsecond level. To explore the potential of event cameras in the above-mentioned challenging cases, we propose EvTTC, which is, to the best of our knowledge, the first multi-sensor dataset focusing on TTC tasks under high-relative-speed scenarios. EvTTC consists of data collected using standard cameras and event cameras, covering various potential collision scenarios in daily driving and involving multiple collision objects. Additionally, LiDAR and GNSS/INS measurements are provided for the calculation of ground-truth TTC. Considering the high cost of testing TTC algorithms on full-scale mobile platforms, we also provide a small-scale TTC testbed for experimental validation and data augmentation. All the data and the design of the testbed are open sourced, and they can serve as a benchmark that will facilitate the development of vision-based TTC techniques.
Motion and Structure from Event-based Normal Flow
Jul 19, 2024



Recovering the camera motion and scene geometry from visual data is a fundamental problem in the field of computer vision. Its success in standard vision is attributed to the maturity of feature extraction, data association and multi-view geometry. The recent emergence of neuromorphic event-based cameras places great demands on approaches that use raw event data as input to solve this fundamental problem.Existing state-of-the-art solutions typically infer implicitly data association by iteratively reversing the event data generation process. However, the nonlinear nature of these methods limits their applicability in real-time tasks, and the constant-motion assumption leads to unstable results under agile motion. To this end, we rethink the problem formulation in a way that aligns better with the differential working principle of event cameras.We show that the event-based normal flow can be used, via the proposed geometric error term, as an alternative to the full flow in solving a family of geometric problems that involve instantaneous first-order kinematics and scene geometry. Furthermore, we develop a fast linear solver and a continuous-time nonlinear solver on top of the proposed geometric error term.Experiments on both synthetic and real data show the superiority of our linear solver in terms of accuracy and efficiency, and indicate its complementary feature as an initialization method for existing nonlinear solvers. Besides, our continuous-time non-linear solver exhibits exceptional capability in accommodating sudden variations in motion since it does not rely on the constant-motion assumption.
Event-Aided Time-to-Collision Estimation for Autonomous Driving
Jul 10, 2024Predicting a potential collision with leading vehicles is an essential functionality of any autonomous/assisted driving system. One bottleneck of existing vision-based solutions is that their updating rate is limited to the frame rate of standard cameras used. In this paper, we present a novel method that estimates the time to collision using a neuromorphic event-based camera, a biologically inspired visual sensor that can sense at exactly the same rate as scene dynamics. The core of the proposed algorithm consists of a two-step approach for efficient and accurate geometric model fitting on event data in a coarse-to-fine manner. The first step is a robust linear solver based on a novel geometric measurement that overcomes the partial observability of event-based normal flow. The second step further refines the resulting model via a spatio-temporal registration process formulated as a nonlinear optimization problem. Experiments on both synthetic and real data demonstrate the effectiveness of the proposed method, outperforming other alternative methods in terms of efficiency and accuracy.
BeNeRF: Neural Radiance Fields from a Single Blurry Image and Event Stream
Jul 03, 2024Neural implicit representation of visual scenes has attracted a lot of attention in recent research of computer vision and graphics. Most prior methods focus on how to reconstruct 3D scene representation from a set of images. In this work, we demonstrate the possibility to recover the neural radiance fields (NeRF) from a single blurry image and its corresponding event stream. We model the camera motion with a cubic B-Spline in SE(3) space. Both the blurry image and the brightness change within a time interval, can then be synthesized from the 3D scene representation given the 6-DoF poses interpolated from the cubic B-Spline. Our method can jointly learn both the implicit neural scene representation and recover the camera motion by minimizing the differences between the synthesized data and the real measurements without pre-computed camera poses from COLMAP. We evaluate the proposed method with both synthetic and real datasets. The experimental results demonstrate that we are able to render view-consistent latent sharp images from the learned NeRF and bring a blurry image alive in high quality. Code and data are available at https://github.com/WU-CVGL/BeNeRF.
wmh_seg: Transformer based U-Net for Robust and Automatic White Matter Hyperintensity Segmentation across 1.5T, 3T and 7T
Feb 20, 2024



White matter hyperintensity (WMH) remains the top imaging biomarker for neurodegenerative diseases. Robust and accurate segmentation of WMH holds paramount significance for neuroimaging studies. The growing shift from 3T to 7T MRI necessitates robust tools for harmonized segmentation across field strengths and artifacts. Recent deep learning models exhibit promise in WMH segmentation but still face challenges, including diverse training data representation and limited analysis of MRI artifacts' impact. To address these, we introduce wmh_seg, a novel deep learning model leveraging a transformer-based encoder from SegFormer. wmh_seg is trained on an unmatched dataset, including 1.5T, 3T, and 7T FLAIR images from various sources, alongside with artificially added MR artifacts. Our approach bridges gaps in training diversity and artifact analysis. Our model demonstrated stable performance across magnetic field strengths, scanner manufacturers, and common MR imaging artifacts. Despite the unique inhomogeneity artifacts on ultra-high field MR images, our model still offers robust and stable segmentation on 7T FLAIR images. Our model, to date, is the first that offers quality white matter lesion segmentation on 7T FLAIR images.
DIDO: Deep Inertial Quadrotor Dynamical Odometry
Mar 07, 2022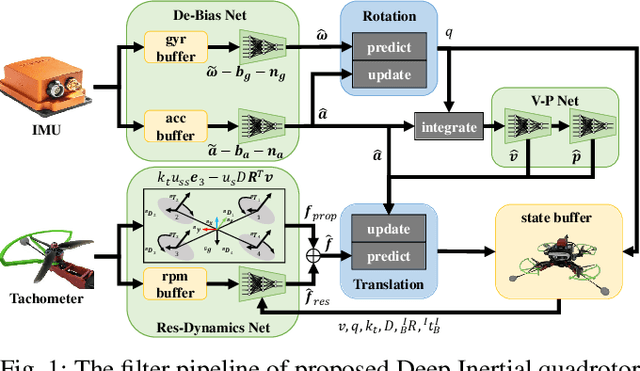
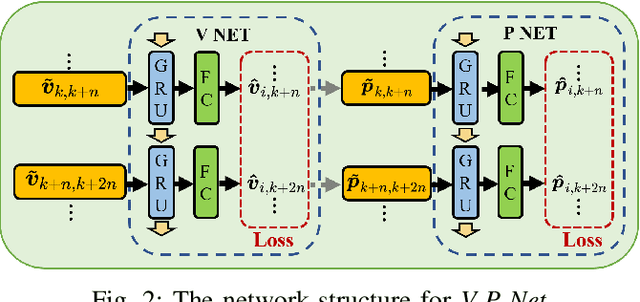
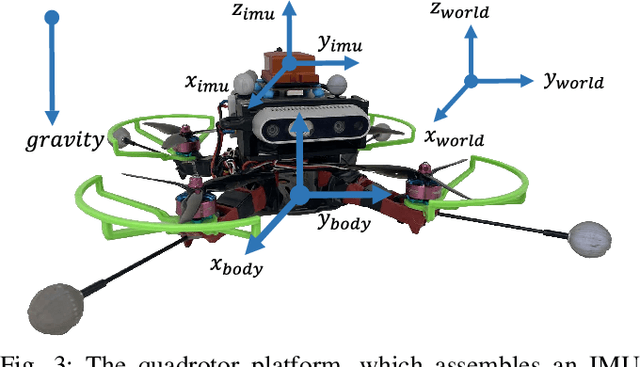
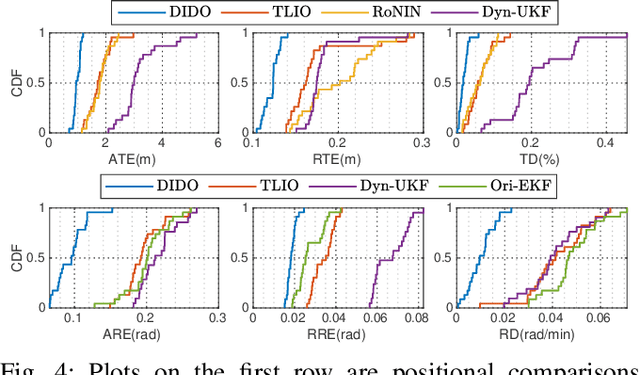
In this work, we propose an interoceptive-only state estimation system for a quadrotor with deep neural network processing, where the quadrotor dynamics is considered as a perceptive supplement of the inertial kinematics. To improve the precision of multi-sensor fusion, we train cascaded networks on real-world quadrotor flight data to learn IMU kinematic properties, quadrotor dynamic characteristics, and motion states of the quadrotor along with their uncertainty information, respectively. This encoded information empowers us to address the issues of IMU bias stability, dynamic constraints, and multi-sensor calibration during sensor fusion. The above multi-source information is fused into a two-stage Extended Kalman Filter (EKF) framework for better estimation. Experiments have demonstrated the advantages of our proposed work over several conventional and learning-based methods.