 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBring Reason to Vision: Understanding Perception and Reasoning through Model Merging
May 08, 2025Vision-Language Models (VLMs) combine visual perception with the general capabilities, such as reasoning, of Large Language Models (LLMs). However, the mechanisms by which these two abilities can be combined and contribute remain poorly understood. In this work, we explore to compose perception and reasoning through model merging that connects parameters of different models. Unlike previous works that often focus on merging models of the same kind, we propose merging models across modalities, enabling the incorporation of the reasoning capabilities of LLMs into VLMs. Through extensive experiments, we demonstrate that model merging offers a successful pathway to transfer reasoning abilities from LLMs to VLMs in a training-free manner. Moreover, we utilize the merged models to understand the internal mechanism of perception and reasoning and how merging affects it. We find that perception capabilities are predominantly encoded in the early layers of the model, whereas reasoning is largely facilitated by the middle-to-late layers. After merging, we observe that all layers begin to contribute to reasoning, whereas the distribution of perception abilities across layers remains largely unchanged. These observations shed light on the potential of model merging as a tool for multimodal integration and interpretation.
DocSpiral: A Platform for Integrated Assistive Document Annotation through Human-in-the-Spiral
May 06, 2025Acquiring structured data from domain-specific, image-based documents such as scanned reports is crucial for many downstream tasks but remains challenging due to document variability. Many of these documents exist as images rather than as machine-readable text, which requires human annotation to train automated extraction systems. We present DocSpiral, the first Human-in-the-Spiral assistive document annotation platform, designed to address the challenge of extracting structured information from domain-specific, image-based document collections. Our spiral design establishes an iterative cycle in which human annotations train models that progressively require less manual intervention. DocSpiral integrates document format normalization, comprehensive annotation interfaces, evaluation metrics dashboard, and API endpoints for the development of AI / ML models into a unified workflow. Experiments demonstrate that our framework reduces annotation time by at least 41\% while showing consistent performance gains across three iterations during model training. By making this annotation platform freely accessible, we aim to lower barriers to AI/ML models development in document processing, facilitating the adoption of large language models in image-based, document-intensive fields such as geoscience and healthcare. The system is freely available at: https://app.ai4wa.com. The demonstration video is available: https://app.ai4wa.com/docs/docspiral/demo.
SymbioticRAG: Enhancing Document Intelligence Through Human-LLM Symbiotic Collaboration
May 05, 2025We present \textbf{SymbioticRAG}, a novel framework that fundamentally reimagines Retrieval-Augmented Generation~(RAG) systems by establishing a bidirectional learning relationship between humans and machines. Our approach addresses two critical challenges in current RAG systems: the inherently human-centered nature of relevance determination and users' progression from "unconscious incompetence" in query formulation. SymbioticRAG introduces a two-tier solution where Level 1 enables direct human curation of retrieved content through interactive source document exploration, while Level 2 aims to build personalized retrieval models based on captured user interactions. We implement Level 1 through three key components: (1)~a comprehensive document processing pipeline with specialized models for layout detection, OCR, and extraction of tables, formulas, and figures; (2)~an extensible retriever module supporting multiple retrieval strategies; and (3)~an interactive interface that facilitates both user engagement and interaction data logging. We experiment Level 2 implementation via a retriever strategy incorporated LLM summarized user intention from user interaction logs. To maintain high-quality data preparation, we develop a human-on-the-loop validation interface that improves pipeline output while advancing research in specialized extraction tasks. Evaluation across three scenarios (literature review, geological exploration, and education) demonstrates significant improvements in retrieval relevance and user satisfaction compared to traditional RAG approaches. To facilitate broader research and further advancement of SymbioticRAG Level 2 implementation, we will make our system openly accessible to the research community.
Adversarial Cooperative Rationalization: The Risk of Spurious Correlations in Even Clean Datasets
May 04, 2025



This study investigates the self-rationalization framework constructed with a cooperative game, where a generator initially extracts the most informative segment from raw input, and a subsequent predictor utilizes the selected subset for its input. The generator and predictor are trained collaboratively to maximize prediction accuracy. In this paper, we first uncover a potential caveat: such a cooperative game could unintentionally introduce a sampling bias during rationale extraction. Specifically, the generator might inadvertently create an incorrect correlation between the selected rationale candidate and the label, even when they are semantically unrelated in the original dataset. Subsequently, we elucidate the origins of this bias using both detailed theoretical analysis and empirical evidence. Our findings suggest a direction for inspecting these correlations through attacks, based on which we further introduce an instruction to prevent the predictor from learning the correlations. Through experiments on six text classification datasets and two graph classification datasets using three network architectures (GRUs, BERT, and GCN), we show that our method not only significantly outperforms recent rationalization methods, but also achieves comparable or even better results than a representative LLM (llama3.1-8b-instruct).
Weaving Context Across Images: Improving Vision-Language Models through Focus-Centric Visual Chains
Apr 28, 2025



Vision-language models (VLMs) achieve remarkable success in single-image tasks. However, real-world scenarios often involve intricate multi-image inputs, leading to a notable performance decline as models struggle to disentangle critical information scattered across complex visual features. In this work, we propose Focus-Centric Visual Chain, a novel paradigm that enhances VLMs'perception, comprehension, and reasoning abilities in multi-image scenarios. To facilitate this paradigm, we propose Focus-Centric Data Synthesis, a scalable bottom-up approach for synthesizing high-quality data with elaborate reasoning paths. Through this approach, We construct VISC-150K, a large-scale dataset with reasoning data in the form of Focus-Centric Visual Chain, specifically designed for multi-image tasks. Experimental results on seven multi-image benchmarks demonstrate that our method achieves average performance gains of 3.16% and 2.24% across two distinct model architectures, without compromising the general vision-language capabilities. our study represents a significant step toward more robust and capable vision-language systems that can handle complex visual scenarios.
Knowledge Distillation and Dataset Distillation of Large Language Models: Emerging Trends, Challenges, and Future Directions
Apr 20, 2025



The exponential growth of Large Language Models (LLMs) continues to highlight the need for efficient strategies to meet ever-expanding computational and data demands. This survey provides a comprehensive analysis of two complementary paradigms: Knowledge Distillation (KD) and Dataset Distillation (DD), both aimed at compressing LLMs while preserving their advanced reasoning capabilities and linguistic diversity. We first examine key methodologies in KD, such as task-specific alignment, rationale-based training, and multi-teacher frameworks, alongside DD techniques that synthesize compact, high-impact datasets through optimization-based gradient matching, latent space regularization, and generative synthesis. Building on these foundations, we explore how integrating KD and DD can produce more effective and scalable compression strategies. Together, these approaches address persistent challenges in model scalability, architectural heterogeneity, and the preservation of emergent LLM abilities. We further highlight applications across domains such as healthcare and education, where distillation enables efficient deployment without sacrificing performance. Despite substantial progress, open challenges remain in preserving emergent reasoning and linguistic diversity, enabling efficient adaptation to continually evolving teacher models and datasets, and establishing comprehensive evaluation protocols. By synthesizing methodological innovations, theoretical foundations, and practical insights, our survey charts a path toward sustainable, resource-efficient LLMs through the tighter integration of KD and DD principles.
Adaptive AI decision interface for autonomous electronic material discovery
Apr 17, 2025



AI-powered autonomous experimentation (AI/AE) can accelerate materials discovery but its effectiveness for electronic materials is hindered by data scarcity from lengthy and complex design-fabricate-test-analyze cycles. Unlike experienced human scientists, even advanced AI algorithms in AI/AE lack the adaptability to make informative real-time decisions with limited datasets. Here, we address this challenge by developing and implementing an AI decision interface on our AI/AE system. The central element of the interface is an AI advisor that performs real-time progress monitoring, data analysis, and interactive human-AI collaboration for actively adapting to experiments in different stages and types. We applied this platform to an emerging type of electronic materials-mixed ion-electron conducting polymers (MIECPs) -- to engineer and study the relationships between multiscale morphology and properties. Using organic electrochemical transistors (OECT) as the testing-bed device for evaluating the mixed-conducting figure-of-merit -- the product of charge-carrier mobility and the volumetric capacitance ({\mu}C*), our adaptive AI/AE platform achieved a 150% increase in {\mu}C* compared to the commonly used spin-coating method, reaching 1,275 F cm-1 V-1 s-1 in just 64 autonomous experimental trials. A study of 10 statistically selected samples identifies two key structural factors for achieving higher volumetric capacitance: larger crystalline lamellar spacing and higher specific surface area, while also uncovering a new polymer polymorph in this material.
Seedream 3.0 Technical Report
Apr 16, 2025



We present Seedream 3.0, a high-performance Chinese-English bilingual image generation foundation model. We develop several technical improvements to address existing challenges in Seedream 2.0, including alignment with complicated prompts, fine-grained typography generation, suboptimal visual aesthetics and fidelity, and limited image resolutions. Specifically, the advancements of Seedream 3.0 stem from improvements across the entire pipeline, from data construction to model deployment. At the data stratum, we double the dataset using a defect-aware training paradigm and a dual-axis collaborative data-sampling framework. Furthermore, we adopt several effective techniques such as mixed-resolution training, cross-modality RoPE, representation alignment loss, and resolution-aware timestep sampling in the pre-training phase. During the post-training stage, we utilize diversified aesthetic captions in SFT, and a VLM-based reward model with scaling, thereby achieving outputs that well align with human preferences. Furthermore, Seedream 3.0 pioneers a novel acceleration paradigm. By employing consistent noise expectation and importance-aware timestep sampling, we achieve a 4 to 8 times speedup while maintaining image quality. Seedream 3.0 demonstrates significant improvements over Seedream 2.0: it enhances overall capabilities, in particular for text-rendering in complicated Chinese characters which is important to professional typography generation. In addition, it provides native high-resolution output (up to 2K), allowing it to generate images with high visual quality.
HarmonySeg: Tubular Structure Segmentation with Deep-Shallow Feature Fusion and Growth-Suppression Balanced Loss
Apr 10, 2025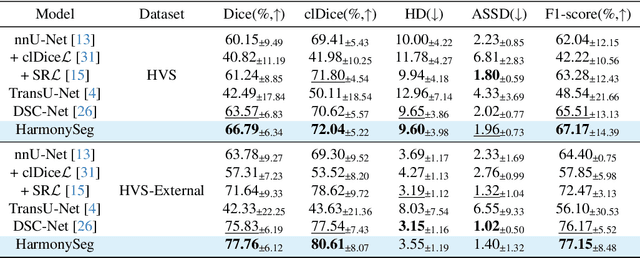
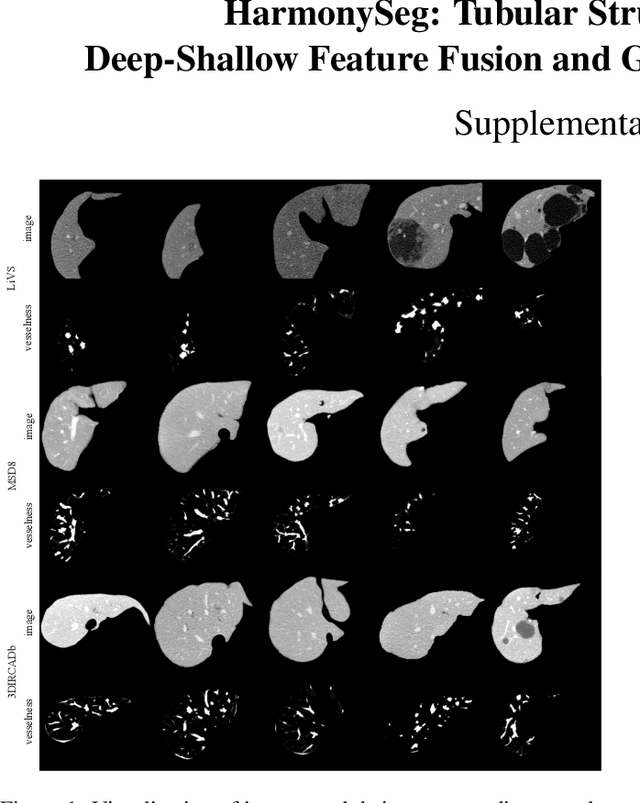

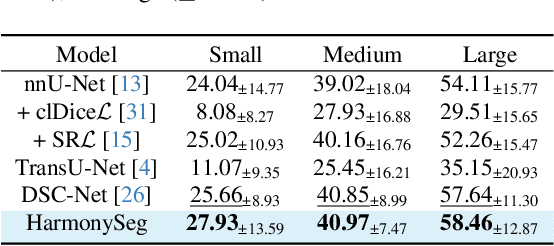
Accurate segmentation of tubular structures in medical images, such as vessels and airway trees, is crucial for computer-aided diagnosis, radiotherapy, and surgical planning. However, significant challenges exist in algorithm design when faced with diverse sizes, complex topologies, and (often) incomplete data annotation of these structures. We address these difficulties by proposing a new tubular structure segmentation framework named HarmonySeg. First, we design a deep-to-shallow decoder network featuring flexible convolution blocks with varying receptive fields, which enables the model to effectively adapt to tubular structures of different scales. Second, to highlight potential anatomical regions and improve the recall of small tubular structures, we incorporate vesselness maps as auxiliary information. These maps are aligned with image features through a shallow-and-deep fusion module, which simultaneously eliminates unreasonable candidates to maintain high precision. Finally, we introduce a topology-preserving loss function that leverages contextual and shape priors to balance the growth and suppression of tubular structures, which also allows the model to handle low-quality and incomplete annotations. Extensive quantitative experiments are conducted on four public datasets. The results show that our model can accurately segment 2D and 3D tubular structures and outperform existing state-of-the-art methods. External validation on a private dataset also demonstrates good generalizability.
A Deep Single Image Rectification Approach for Pan-Tilt-Zoom Cameras
Apr 09, 2025Pan-Tilt-Zoom (PTZ) cameras with wide-angle lenses are widely used in surveillance but often require image rectification due to their inherent nonlinear distortions. Current deep learning approaches typically struggle to maintain fine-grained geometric details, resulting in inaccurate rectification. This paper presents a Forward Distortion and Backward Warping Network (FDBW-Net), a novel framework for wide-angle image rectification. It begins by using a forward distortion model to synthesize barrel-distorted images, reducing pixel redundancy and preventing blur. The network employs a pyramid context encoder with attention mechanisms to generate backward warping flows containing geometric details. Then, a multi-scale decoder is used to restore distorted features and output rectified images. FDBW-Net's performance is validated on diverse datasets: public benchmarks, AirSim-rendered PTZ camera imagery, and real-scene PTZ camera datasets. It demonstrates that FDBW-Net achieves SOTA performance in distortion rectification, boosting the adaptability of PTZ cameras for practical visual applications.