 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLongCat-Next: Lexicalizing Modalities as Discrete Tokens
Mar 29, 2026The prevailing Next-Token Prediction (NTP) paradigm has driven the success of large language models through discrete autoregressive modeling. However, contemporary multimodal systems remain language-centric, often treating non-linguistic modalities as external attachments, leading to fragmented architectures and suboptimal integration. To transcend this limitation, we introduce Discrete Native Autoregressive (DiNA), a unified framework that represents multimodal information within a shared discrete space, enabling a consistent and principled autoregressive modeling across modalities. A key innovation is the Discrete Native Any-resolution Visual Transformer (dNaViT), which performs tokenization and de-tokenization at arbitrary resolutions, transforming continuous visual signals into hierarchical discrete tokens. Building on this foundation, we develop LongCat-Next, a native multimodal model that processes text, vision, and audio under a single autoregressive objective with minimal modality-specific design. As an industrial-strength foundation model, it excels at seeing, painting, and talking within a single framework, achieving strong performance across a wide range of multimodal benchmarks. In particular, LongCat-Next addresses the long-standing performance ceiling of discrete vision modeling on understanding tasks and provides a unified approach to effectively reconcile the conflict between understanding and generation. As an attempt toward native multimodality, we open-source the LongCat-Next and its tokenizers, hoping to foster further research and development in the community. GitHub: https://github.com/meituan-longcat/LongCat-Next
On Support Samples of Next Word Prediction
Jun 09, 2025Language models excel in various tasks by making complex decisions, yet understanding the rationale behind these decisions remains a challenge. This paper investigates \emph{data-centric interpretability} in language models, focusing on the next-word prediction task. Using representer theorem, we identify two types of \emph{support samples}-those that either promote or deter specific predictions. Our findings reveal that being a support sample is an intrinsic property, predictable even before training begins. Additionally, while non-support samples are less influential in direct predictions, they play a critical role in preventing overfitting and shaping generalization and representation learning. Notably, the importance of non-support samples increases in deeper layers, suggesting their significant role in intermediate representation formation. These insights shed light on the interplay between data and model decisions, offering a new dimension to understanding language model behavior and interpretability.
Knowledge Distillation and Dataset Distillation of Large Language Models: Emerging Trends, Challenges, and Future Directions
Apr 20, 2025



The exponential growth of Large Language Models (LLMs) continues to highlight the need for efficient strategies to meet ever-expanding computational and data demands. This survey provides a comprehensive analysis of two complementary paradigms: Knowledge Distillation (KD) and Dataset Distillation (DD), both aimed at compressing LLMs while preserving their advanced reasoning capabilities and linguistic diversity. We first examine key methodologies in KD, such as task-specific alignment, rationale-based training, and multi-teacher frameworks, alongside DD techniques that synthesize compact, high-impact datasets through optimization-based gradient matching, latent space regularization, and generative synthesis. Building on these foundations, we explore how integrating KD and DD can produce more effective and scalable compression strategies. Together, these approaches address persistent challenges in model scalability, architectural heterogeneity, and the preservation of emergent LLM abilities. We further highlight applications across domains such as healthcare and education, where distillation enables efficient deployment without sacrificing performance. Despite substantial progress, open challenges remain in preserving emergent reasoning and linguistic diversity, enabling efficient adaptation to continually evolving teacher models and datasets, and establishing comprehensive evaluation protocols. By synthesizing methodological innovations, theoretical foundations, and practical insights, our survey charts a path toward sustainable, resource-efficient LLMs through the tighter integration of KD and DD principles.
The Role of Visual Modality in Multimodal Mathematical Reasoning: Challenges and Insights
Mar 06, 2025Recent research has increasingly focused on multimodal mathematical reasoning, particularly emphasizing the creation of relevant datasets and benchmarks. Despite this, the role of visual information in reasoning has been underexplored. Our findings show that existing multimodal mathematical models minimally leverage visual information, and model performance remains largely unaffected by changes to or removal of images in the dataset. We attribute this to the dominance of textual information and answer options that inadvertently guide the model to correct answers. To improve evaluation methods, we introduce the HC-M3D dataset, specifically designed to require image reliance for problem-solving and to challenge models with similar, yet distinct, images that change the correct answer. In testing leading models, their failure to detect these subtle visual differences suggests limitations in current visual perception capabilities. Additionally, we observe that the common approach of improving general VQA capabilities by combining various types of image encoders does not contribute to math reasoning performance. This finding also presents a challenge to enhancing visual reliance during math reasoning. Our benchmark and code would be available at \href{https://github.com/Yufang-Liu/visual_modality_role}{https://github.com/Yufang-Liu/visual\_modality\_role}.
Large Language Models for Bioinformatics
Jan 10, 2025
With the rapid advancements in large language model (LLM) technology and the emergence of bioinformatics-specific language models (BioLMs), there is a growing need for a comprehensive analysis of the current landscape, computational characteristics, and diverse applications. This survey aims to address this need by providing a thorough review of BioLMs, focusing on their evolution, classification, and distinguishing features, alongside a detailed examination of training methodologies, datasets, and evaluation frameworks. We explore the wide-ranging applications of BioLMs in critical areas such as disease diagnosis, drug discovery, and vaccine development, highlighting their impact and transformative potential in bioinformatics. We identify key challenges and limitations inherent in BioLMs, including data privacy and security concerns, interpretability issues, biases in training data and model outputs, and domain adaptation complexities. Finally, we highlight emerging trends and future directions, offering valuable insights to guide researchers and clinicians toward advancing BioLMs for increasingly sophisticated biological and clinical applications.
Investigating and Mitigating Object Hallucinations in Pretrained Vision-Language (CLIP) Models
Oct 04, 2024



Large Vision-Language Models (LVLMs) have achieved impressive performance, yet research has pointed out a serious issue with object hallucinations within these models. However, there is no clear conclusion as to which part of the model these hallucinations originate from. In this paper, we present an in-depth investigation into the object hallucination problem specifically within the CLIP model, which serves as the backbone for many state-of-the-art vision-language systems. We unveil that even in isolation, the CLIP model is prone to object hallucinations, suggesting that the hallucination problem is not solely due to the interaction between vision and language modalities. To address this, we propose a counterfactual data augmentation method by creating negative samples with a variety of hallucination issues. We demonstrate that our method can effectively mitigate object hallucinations for CLIP model, and we show the the enhanced model can be employed as a visual encoder, effectively alleviating the object hallucination issue in LVLMs.
EAGLE: Elevating Geometric Reasoning through LLM-empowered Visual Instruction Tuning
Aug 21, 2024



Multi-modal Large Language Models have recently experienced rapid developments and excel in various multi-modal tasks. However, they still struggle with mathematical geometric problem solving, which requires exceptional visual perception proficiency. Existing MLLMs mostly optimize the LLM backbone to acquire geometric reasoning capabilities, while rarely emphasizing improvements in visual comprehension. In this paper, we first investigate the visual perception performance of MLLMs when facing geometric diagrams. Our findings reveal that current MLLMs severely suffer from inaccurate geometric perception and hallucinations. To address these limitations, we propose EAGLE, a novel two-stage end-to-end visual enhancement MLLM framework designed to ElevAte Geometric reasoning through LLM-Empowered visual instruction tuning. Specifically, in the preliminary stage, we feed geometric image-caption pairs into our MLLM that contains a fully fine-tuning CLIP ViT and a frozen LLM, aiming to endow our model with basic geometric knowledge. In the subsequent advanced stage, we incorporate LoRA modules into the vision encoder and unfreeze the LLM backbone. This enables the model to leverage the inherent CoT rationales within question-answer pairs, guiding the MLLM to focus on nuanced visual cues and enhancing its overall perceptual capacity. Moreover, we optimize the cross-modal projector in both stages to foster adaptive visual-linguistic alignments. After the two-stage visual enhancement, we develop the geometry expert model EAGLE-7B. Extensive experiments on popular benchmarks demonstrate the effectiveness of our model. For example, on the GeoQA benchmark, EAGLE-7B not only surpasses the exemplary G-LLaVA 7B model by 2.9%, but also marginally outperforms the larger G-LLaVA 13B model. On the MathVista benchmark, EAGLE-7B achieves remarkable 3.8% improvements compared with the proprietary model GPT-4V.
Unlearning with Fisher Masking
Oct 09, 2023



Machine unlearning aims to revoke some training data after learning in response to requests from users, model developers, and administrators. Most previous methods are based on direct fine-tuning, which may neither remove data completely nor retain full performances on the remain data. In this work, we find that, by first masking some important parameters before fine-tuning, the performances of unlearning could be significantly improved. We propose a new masking strategy tailored to unlearning based on Fisher information. Experiments on various datasets and network structures show the effectiveness of the method: without any fine-tuning, the proposed Fisher masking could unlearn almost completely while maintaining most of the performance on the remain data. It also exhibits stronger stability compared to other unlearning baselines
Few Clean Instances Help Denoising Distant Supervision
Sep 14, 2022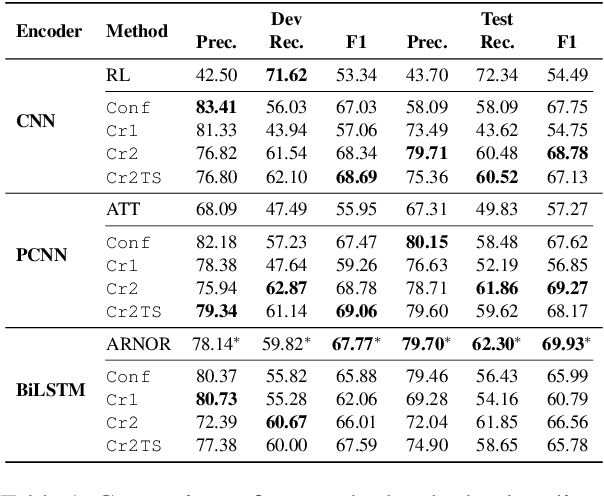
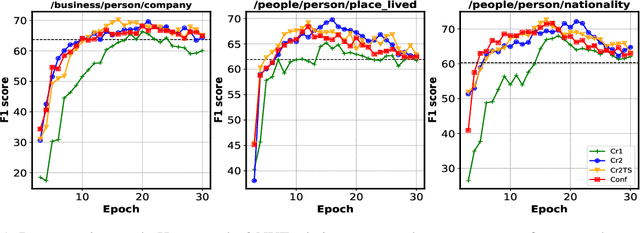
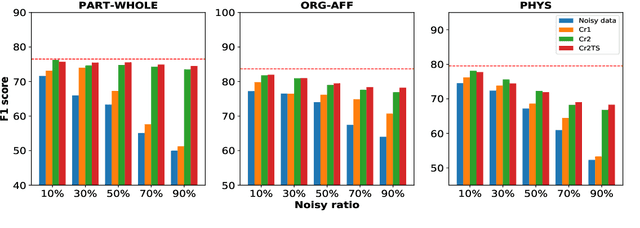
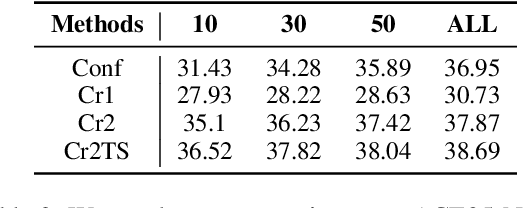
Existing distantly supervised relation extractors usually rely on noisy data for both model training and evaluation, which may lead to garbage-in-garbage-out systems. To alleviate the problem, we study whether a small clean dataset could help improve the quality of distantly supervised models. We show that besides getting a more convincing evaluation of models, a small clean dataset also helps us to build more robust denoising models. Specifically, we propose a new criterion for clean instance selection based on influence functions. It collects sample-level evidence for recognizing good instances (which is more informative than loss-level evidence). We also propose a teacher-student mechanism for controlling purity of intermediate results when bootstrapping the clean set. The whole approach is model-agnostic and demonstrates strong performances on both denoising real (NYT) and synthetic noisy datasets.
Generating CCG Categories
Mar 15, 2021
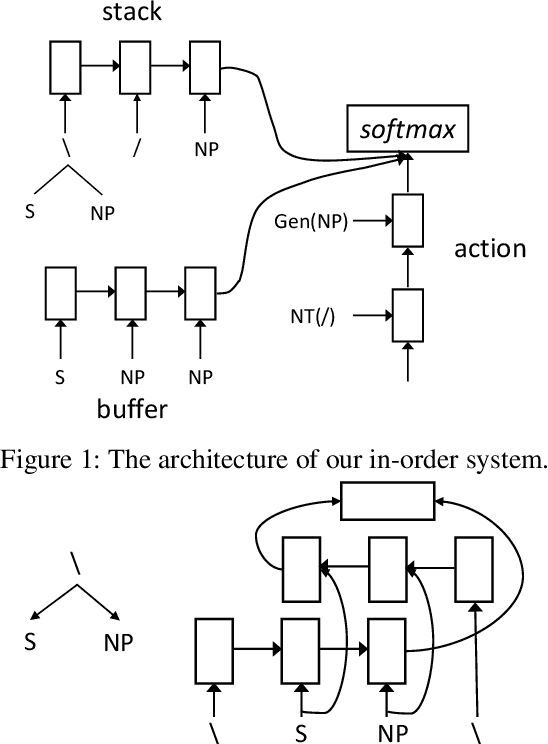
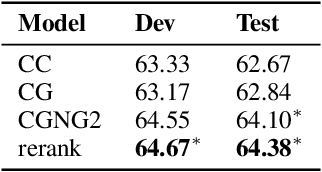
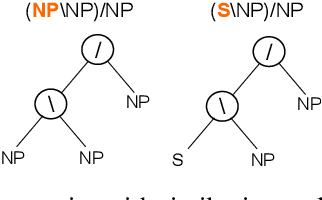
Previous CCG supertaggers usually predict categories using multi-class classification. Despite their simplicity, internal structures of categories are usually ignored. The rich semantics inside these structures may help us to better handle relations among categories and bring more robustness into existing supertaggers. In this work, we propose to generate categories rather than classify them: each category is decomposed into a sequence of smaller atomic tags, and the tagger aims to generate the correct sequence. We show that with this finer view on categories, annotations of different categories could be shared and interactions with sentence contexts could be enhanced. The proposed category generator is able to achieve state-of-the-art tagging (95.5% accuracy) and parsing (89.8% labeled F1) performances on the standard CCGBank. Furthermore, its performances on infrequent (even unseen) categories, out-of-domain texts and low resource language give promising results on introducing generation models to the general CCG analyses.