 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpreting Neural Combinatorial Optimization via Evolving Programmatic Bottlenecks
Jun 18, 2026Neural Combinatorial Optimization (NCO) achieves strong performance, yet its black-box nature remains a key roadblock to deployment and scientific diagnosis. Standard interpretability tools, such as Concept Bottleneck Models (CBMs), are ill-equipped for NCO, whose decisions are dynamic, state-dependent, and lack proper concept vocabulary definition. To close this gap, we introduce Evolving Programmatic Bottlenecks (EPB), to our knowledge, the first framework for interpreting NCO policies by distilling black-box NCO models into human-readable program portfolios. EPB employs an LLM to autonomously evolve a bank of programs, where each program's per-step action distribution serves as the bottleneck. EPB works through an iterative framework: Block I fixes program bank capacity and introduces a hybrid textual-numerical gradient descent scheme that couples numerical gradients for student router updates and textual gradients for LLM-based program revision; Block II dynamically adapts bank capacity via fault-targeted expansion and redundancy pruning. Extensive experiments demonstrate EPB's effectiveness and broad applicability, where the distilled program portfolios largely match original performance. EPB also reveals that NCO behavior shifts across optimization stages and can be approximated as a composition of classic heuristic variants. Our work advances interpretable NCO and establishes EPB as a promising tool for interpreting sequential decision-making models.
FrontierOR: Benchmarking LLMs' Capacity for Efficient Algorithm Design in Large-Scale Optimization
May 26, 2026Large language models (LLMs) are increasingly used for optimization modeling and solver-code generation, yet practical operations research and optimization problems often require a harder capability: designing scalable algorithms that exploit problem structure and outperform direct formulation-and-solve baselines. Existing benchmarks are limited to small or simplified examples far below real-world scale and complexity. We introduce FrontierOR, among the first benchmarks to systematically evaluate LLM-based efficient algorithm design for realistic large-scale optimization problems. FrontierOR includes 180 tasks derived from methodologically diverse papers published in top-tier operations research venues, each with standardized instances and a hidden, expert-verified evaluation suite. We evaluate seven LLMs spanning frontier, cost-effective, and open-source models both in one-shot and test-time evolution settings. The results reveal that frontier models still struggle to move from executable formulations to efficient optimization algorithms: the strongest one-shot model outperforms Gurobi in only 31% of cases in both solution quality and computational efficiency, and even strong coding agents with test-time evolution achieve only 50% on selected hard tasks. FrontierOR establishes a practical evaluation platform for LLM-based optimization algorithm design, which enables future LLMs and agents to be systematically tested on whether they can move beyond correct formulation toward a feasible, high-quality, and efficient algorithm.
STIndex: A Context-Aware Multi-Dimensional Spatiotemporal Information Extraction System
Apr 07, 2026Extracting structured knowledge from unstructured data still faces practical limitations: entity and event extraction pipelines remain brittle, knowledge graph construction requires costly ontology engineering, and cross-domain generalization is rarely production-ready. In contrast, space and time provide universal contextual anchors that naturally align heterogeneous information and benefit downstream tasks such as retrieval and reasoning. We introduce \textbf{STIndex}, an end-to-end system that structures unstructured content into a multidimensional spatiotemporal data warehouse. Users define domain-specific analysis dimensions with configurable hierarchies, while large language models perform context-aware extraction and grounding. \textbf{STIndex} integrates document-level memory, geocoding correction, and quality validation, and offers an interactive analytics dashboard for visualization, clustering, burst detection, and entity network analysis. In evaluation on a public health benchmark, \textbf{STIndex} improves spatiotemporal entity extraction F1 by 4.37\% (GPT-4o-mini) and 3.60\% (Qwen3-8B). A live demonstration and open-source code are available at https://stindex.ai4wa.com/dashboard.
CORAL: Towards Autonomous Multi-Agent Evolution for Open-Ended Discovery
Apr 02, 2026Large language model (LLM)-based evolution is a promising approach for open-ended discovery, where progress requires sustained search and knowledge accumulation. Existing methods still rely heavily on fixed heuristics and hard-coded exploration rules, which limit the autonomy of LLM agents. We present CORAL, the first framework for autonomous multi-agent evolution on open-ended problems. CORAL replaces rigid control with long-running agents that explore, reflect, and collaborate through shared persistent memory, asynchronous multi-agent execution, and heartbeat-based interventions. It also provides practical safeguards, including isolated workspaces, evaluator separation, resource management, and agent session and health management. Evaluated on diverse mathematical, algorithmic, and systems optimization tasks, CORAL sets new state-of-the-art results on 10 tasks, achieving 3-10 times higher improvement rates with far fewer evaluations than fixed evolutionary search baselines across tasks. On Anthropic's kernel engineering task, four co-evolving agents improve the best known score from 1363 to 1103 cycles. Mechanistic analyses further show how these gains arise from knowledge reuse and multi-agent exploration and communication. Together, these results suggest that greater agent autonomy and multi-agent evolution can substantially improve open-ended discovery. Code is available at https://github.com/Human-Agent-Society/CORAL.
Docs2Synth: A Synthetic Data Trained Retriever Framework for Scanned Visually Rich Documents Understanding
Jan 18, 2026Document understanding (VRDU) in regulated domains is particularly challenging, since scanned documents often contain sensitive, evolving, and domain specific knowledge. This leads to two major challenges: the lack of manual annotations for model adaptation and the difficulty for pretrained models to stay up-to-date with domain-specific facts. While Multimodal Large Language Models (MLLMs) show strong zero-shot abilities, they still suffer from hallucination and limited domain grounding. In contrast, discriminative Vision-Language Pre-trained Models (VLPMs) provide reliable grounding but require costly annotations to cover new domains. We introduce Docs2Synth, a synthetic-supervision framework that enables retrieval-guided inference for private and low-resource domains. Docs2Synth automatically processes raw document collections, generates and verifies diverse QA pairs via an agent-based system, and trains a lightweight visual retriever to extract domain-relevant evidence. During inference, the retriever collaborates with an MLLM through an iterative retrieval--generation loop, reducing hallucination and improving response consistency. We further deliver Docs2Synth as an easy-to-use Python package, enabling plug-and-play deployment across diverse real-world scenarios. Experiments on multiple VRDU benchmarks show that Docs2Synth substantially enhances grounding and domain generalization without requiring human annotations.
Probability-Aware Parking Selection
Jan 02, 2026Current parking navigation systems often underestimate total travel time by failing to account for the time spent searching for a parking space, which significantly affects user experience, mode choice, congestion, and emissions. To address this issue, this paper introduces the probability-aware parking selection problem, which aims to direct drivers to the best parking location rather than straight to their destination. An adaptable dynamic programming framework is proposed for decision-making based on probabilistic information about parking availability at the parking lot level. Closed-form analysis determines when it is optimal to target a specific parking lot or explore alternatives, as well as the expected time cost. Sensitivity analysis and three illustrative cases are examined, demonstrating the model's ability to account for the dynamic nature of parking availability. Acknowledging the financial costs of permanent sensing infrastructure, the paper provides analytical and empirical assessments of errors incurred when leveraging stochastic observations to estimate parking availability. Experiments with real-world data from the US city of Seattle indicate this approach's viability, with mean absolute error decreasing from 7% to below 2% as observation frequency grows. In data-based simulations, probability-aware strategies demonstrate time savings up to 66% relative to probability-unaware baselines, yet still take up to 123% longer than direct-to-destination estimates.
MSC-180: A Benchmark for Automated Formal Theorem Proving from Mathematical Subject Classification
Dec 20, 2025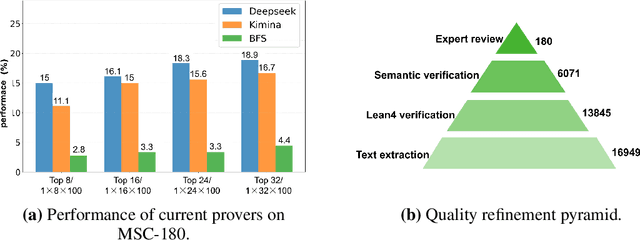



Automated Theorem Proving (ATP) represents a core research direction in artificial intelligence for achieving formal reasoning and verification, playing a significant role in advancing machine intelligence. However, current large language model (LLM)-based theorem provers suffer from limitations such as restricted domain coverage and weak generalization in mathematical reasoning. To address these issues, we propose MSC-180, a benchmark for evaluation based on the MSC2020 mathematical subject classification. It comprises 180 formal verification problems, 3 advanced problems from each of 60 mathematical branches, spanning from undergraduate to graduate levels. Each problem has undergone multiple rounds of verification and refinement by domain experts to ensure formal accuracy. Evaluations of state-of-the-art LLM-based theorem provers under the pass@32 setting reveal that the best model achieves only an 18.89% overall pass rate, with prominent issues including significant domain bias (maximum domain coverage 41.7%) and a difficulty gap (significantly lower pass rates on graduate-level problems). To further quantify performance variability across mathematical domains, we introduce the coefficient of variation (CV) as an evaluation metric. The observed CV values are 4-6 times higher than the statistical high-variability threshold, indicating that the models still rely on pattern matching from training corpora rather than possessing transferable reasoning mechanisms and systematic generalization capabilities. MSC-180, together with its multi-dimensional evaluation framework, provides a discriminative and systematic benchmark for driving the development of next-generation AI systems with genuine mathematical reasoning abilities.
Automated Formalization via Conceptual Retrieval-Augmented LLMs
Aug 09, 2025



Interactive theorem provers (ITPs) require manual formalization, which is labor-intensive and demands expert knowledge. While automated formalization offers a potential solution, it faces two major challenges: model hallucination (e.g., undefined predicates, symbol misuse, and version incompatibility) and the semantic gap caused by ambiguous or missing premises in natural language descriptions. To address these issues, we propose CRAMF, a Concept-driven Retrieval-Augmented Mathematical Formalization framework. CRAMF enhances LLM-based autoformalization by retrieving formal definitions of core mathematical concepts, providing contextual grounding during code generation. However, applying retrieval-augmented generation (RAG) in this setting is non-trivial due to the lack of structured knowledge bases, the polymorphic nature of mathematical concepts, and the high precision required in formal retrieval. We introduce a framework for automatically constructing a concept-definition knowledge base from Mathlib4, the standard mathematical library for the Lean 4 theorem prover, indexing over 26,000 formal definitions and 1,000+ core mathematical concepts. To address conceptual polymorphism, we propose contextual query augmentation with domain- and application-level signals. In addition, we design a dual-channel hybrid retrieval strategy with reranking to ensure accurate and relevant definition retrieval. Experiments on miniF2F, ProofNet, and our newly proposed AdvancedMath benchmark show that CRAMF can be seamlessly integrated into LLM-based autoformalizers, yielding consistent improvements in translation accuracy, achieving up to 62.1% and an average of 29.9% relative improvement.
SpeechRefiner: Towards Perceptual Quality Refinement for Front-End Algorithms
Jun 16, 2025Speech pre-processing techniques such as denoising, de-reverberation, and separation, are commonly employed as front-ends for various downstream speech processing tasks. However, these methods can sometimes be inadequate, resulting in residual noise or the introduction of new artifacts. Such deficiencies are typically not captured by metrics like SI-SNR but are noticeable to human listeners. To address this, we introduce SpeechRefiner, a post-processing tool that utilizes Conditional Flow Matching (CFM) to improve the perceptual quality of speech. In this study, we benchmark SpeechRefiner against recent task-specific refinement methods and evaluate its performance within our internal processing pipeline, which integrates multiple front-end algorithms. Experiments show that SpeechRefiner exhibits strong generalization across diverse impairment sources, significantly enhancing speech perceptual quality. Audio demos can be found at https://speechrefiner.github.io/SpeechRefiner/.
Autoformalization in the Era of Large Language Models: A Survey
May 29, 2025Autoformalization, the process of transforming informal mathematical propositions into verifiable formal representations, is a foundational task in automated theorem proving, offering a new perspective on the use of mathematics in both theoretical and applied domains. Driven by the rapid progress in artificial intelligence, particularly large language models (LLMs), this field has witnessed substantial growth, bringing both new opportunities and unique challenges. In this survey, we provide a comprehensive overview of recent advances in autoformalization from both mathematical and LLM-centric perspectives. We examine how autoformalization is applied across various mathematical domains and levels of difficulty, and analyze the end-to-end workflow from data preprocessing to model design and evaluation. We further explore the emerging role of autoformalization in enhancing the verifiability of LLM-generated outputs, highlighting its potential to improve both the trustworthiness and reasoning capabilities of LLMs. Finally, we summarize key open-source models and datasets supporting current research, and discuss open challenges and promising future directions for the field.