 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMonoHuman: Animatable Human Neural Field from Monocular Video
Apr 04, 2023



Animating virtual avatars with free-view control is crucial for various applications like virtual reality and digital entertainment. Previous studies have attempted to utilize the representation power of the neural radiance field (NeRF) to reconstruct the human body from monocular videos. Recent works propose to graft a deformation network into the NeRF to further model the dynamics of the human neural field for animating vivid human motions. However, such pipelines either rely on pose-dependent representations or fall short of motion coherency due to frame-independent optimization, making it difficult to generalize to unseen pose sequences realistically. In this paper, we propose a novel framework MonoHuman, which robustly renders view-consistent and high-fidelity avatars under arbitrary novel poses. Our key insight is to model the deformation field with bi-directional constraints and explicitly leverage the off-the-peg keyframe information to reason the feature correlations for coherent results. Specifically, we first propose a Shared Bidirectional Deformation module, which creates a pose-independent generalizable deformation field by disentangling backward and forward deformation correspondences into shared skeletal motion weight and separate non-rigid motions. Then, we devise a Forward Correspondence Search module, which queries the correspondence feature of keyframes to guide the rendering network. The rendered results are thus multi-view consistent with high fidelity, even under challenging novel pose settings. Extensive experiments demonstrate the superiority of our proposed MonoHuman over state-of-the-art methods.
SynBody: Synthetic Dataset with Layered Human Models for 3D Human Perception and Modeling
Mar 30, 2023



Synthetic data has emerged as a promising source for 3D human research as it offers low-cost access to large-scale human datasets. To advance the diversity and annotation quality of human models, we introduce a new synthetic dataset, Synbody, with three appealing features: 1) a clothed parametric human model that can generate a diverse range of subjects; 2) the layered human representation that naturally offers high-quality 3D annotations to support multiple tasks; 3) a scalable system for producing realistic data to facilitate real-world tasks. The dataset comprises 1.7M images with corresponding accurate 3D annotations, covering 10,000 human body models, 1000 actions, and various viewpoints. The dataset includes two subsets for human mesh recovery as well as human neural rendering. Extensive experiments on SynBody indicate that it substantially enhances both SMPL and SMPL-X estimation. Furthermore, the incorporation of layered annotations offers a valuable training resource for investigating the Human Neural Radiance Fields (NeRF).
CelebV-Text: A Large-Scale Facial Text-Video Dataset
Mar 26, 2023Text-driven generation models are flourishing in video generation and editing. However, face-centric text-to-video generation remains a challenge due to the lack of a suitable dataset containing high-quality videos and highly relevant texts. This paper presents CelebV-Text, a large-scale, diverse, and high-quality dataset of facial text-video pairs, to facilitate research on facial text-to-video generation tasks. CelebV-Text comprises 70,000 in-the-wild face video clips with diverse visual content, each paired with 20 texts generated using the proposed semi-automatic text generation strategy. The provided texts are of high quality, describing both static and dynamic attributes precisely. The superiority of CelebV-Text over other datasets is demonstrated via comprehensive statistical analysis of the videos, texts, and text-video relevance. The effectiveness and potential of CelebV-Text are further shown through extensive self-evaluation. A benchmark is constructed with representative methods to standardize the evaluation of the facial text-to-video generation task. All data and models are publicly available.
OmniObject3D: Large-Vocabulary 3D Object Dataset for Realistic Perception, Reconstruction and Generation
Jan 18, 2023



Recent advances in modeling 3D objects mostly rely on synthetic datasets due to the lack of large-scale realscanned 3D databases. To facilitate the development of 3D perception, reconstruction, and generation in the real world, we propose OmniObject3D, a large vocabulary 3D object dataset with massive high-quality real-scanned 3D objects. OmniObject3D has several appealing properties: 1) Large Vocabulary: It comprises 6,000 scanned objects in 190 daily categories, sharing common classes with popular 2D datasets (e.g., ImageNet and LVIS), benefiting the pursuit of generalizable 3D representations. 2) Rich Annotations: Each 3D object is captured with both 2D and 3D sensors, providing textured meshes, point clouds, multiview rendered images, and multiple real-captured videos. 3) Realistic Scans: The professional scanners support highquality object scans with precise shapes and realistic appearances. With the vast exploration space offered by OmniObject3D, we carefully set up four evaluation tracks: a) robust 3D perception, b) novel-view synthesis, c) neural surface reconstruction, and d) 3D object generation. Extensive studies are performed on these four benchmarks, revealing new observations, challenges, and opportunities for future research in realistic 3D vision.
3DHumanGAN: Towards Photo-Realistic 3D-Aware Human Image Generation
Dec 14, 2022We present 3DHumanGAN, a 3D-aware generative adversarial network (GAN) that synthesizes images of full-body humans with consistent appearances under different view-angles and body-poses. To tackle the representational and computational challenges in synthesizing the articulated structure of human bodies, we propose a novel generator architecture in which a 2D convolutional backbone is modulated by a 3D pose mapping network. The 3D pose mapping network is formulated as a renderable implicit function conditioned on a posed 3D human mesh. This design has several merits: i) it allows us to harness the power of 2D GANs to generate photo-realistic images; ii) it generates consistent images under varying view-angles and specifiable poses; iii) the model can benefit from the 3D human prior. Our model is adversarially learned from a collection of web images needless of manual annotation.
Audio-Driven Co-Speech Gesture Video Generation
Dec 05, 2022Co-speech gesture is crucial for human-machine interaction and digital entertainment. While previous works mostly map speech audio to human skeletons (e.g., 2D keypoints), directly generating speakers' gestures in the image domain remains unsolved. In this work, we formally define and study this challenging problem of audio-driven co-speech gesture video generation, i.e., using a unified framework to generate speaker image sequence driven by speech audio. Our key insight is that the co-speech gestures can be decomposed into common motion patterns and subtle rhythmic dynamics. To this end, we propose a novel framework, Audio-driveN Gesture vIdeo gEneration (ANGIE), to effectively capture the reusable co-speech gesture patterns as well as fine-grained rhythmic movements. To achieve high-fidelity image sequence generation, we leverage an unsupervised motion representation instead of a structural human body prior (e.g., 2D skeletons). Specifically, 1) we propose a vector quantized motion extractor (VQ-Motion Extractor) to summarize common co-speech gesture patterns from implicit motion representation to codebooks. 2) Moreover, a co-speech gesture GPT with motion refinement (Co-Speech GPT) is devised to complement the subtle prosodic motion details. Extensive experiments demonstrate that our framework renders realistic and vivid co-speech gesture video. Demo video and more resources can be found in: https://alvinliu0.github.io/projects/ANGIE
VLG: General Video Recognition with Web Textual Knowledge
Dec 03, 2022Video recognition in an open and dynamic world is quite challenging, as we need to handle different settings such as close-set, long-tail, few-shot and open-set. By leveraging semantic knowledge from noisy text descriptions crawled from the Internet, we focus on the general video recognition (GVR) problem of solving different recognition tasks within a unified framework. The core contribution of this paper is twofold. First, we build a comprehensive video recognition benchmark of Kinetics-GVR, including four sub-task datasets to cover the mentioned settings. To facilitate the research of GVR, we propose to utilize external textual knowledge from the Internet and provide multi-source text descriptions for all action classes. Second, inspired by the flexibility of language representation, we present a unified visual-linguistic framework (VLG) to solve the problem of GVR by an effective two-stage training paradigm. Our VLG is first pre-trained on video and language datasets to learn a shared feature space, and then devises a flexible bi-modal attention head to collaborate high-level semantic concepts under different settings. Extensive results show that our VLG obtains the state-of-the-art performance under four settings. The superior performance demonstrates the effectiveness and generalization ability of our proposed framework. We hope our work makes a step towards the general video recognition and could serve as a baseline for future research. The code and models will be available at https://github.com/MCG-NJU/VLG.
MotionBERT: Unified Pretraining for Human Motion Analysis
Oct 12, 2022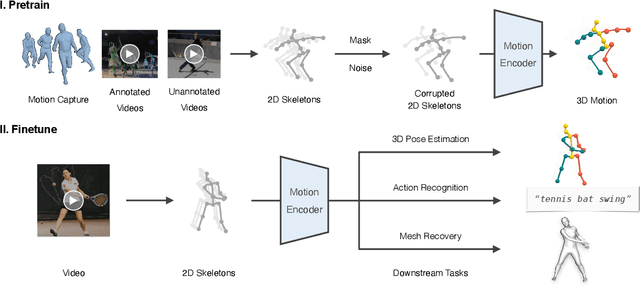
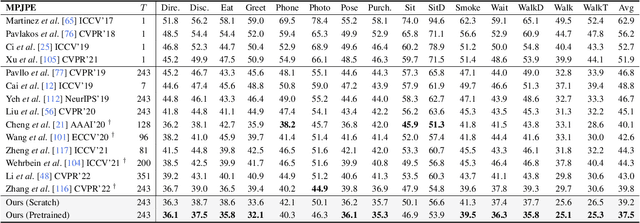
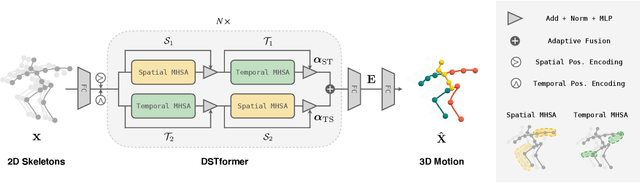
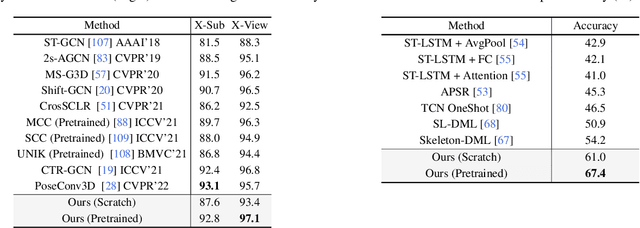
We present MotionBERT, a unified pretraining framework, to tackle different sub-tasks of human motion analysis including 3D pose estimation, skeleton-based action recognition, and mesh recovery. The proposed framework is capable of utilizing all kinds of human motion data resources, including motion capture data and in-the-wild videos. During pretraining, the pretext task requires the motion encoder to recover the underlying 3D motion from noisy partial 2D observations. The pretrained motion representation thus acquires geometric, kinematic, and physical knowledge about human motion and therefore can be easily transferred to multiple downstream tasks. We implement the motion encoder with a novel Dual-stream Spatio-temporal Transformer (DSTformer) neural network. It could capture long-range spatio-temporal relationships among the skeletal joints comprehensively and adaptively, exemplified by the lowest 3D pose estimation error so far when trained from scratch. More importantly, the proposed framework achieves state-of-the-art performance on all three downstream tasks by simply finetuning the pretrained motion encoder with 1-2 linear layers, which demonstrates the versatility of the learned motion representations.
StyleFaceV: Face Video Generation via Decomposing and Recomposing Pretrained StyleGAN3
Aug 16, 2022
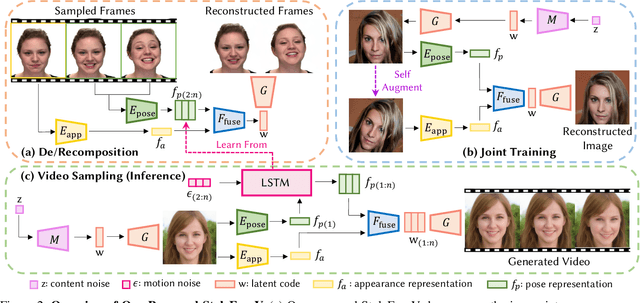
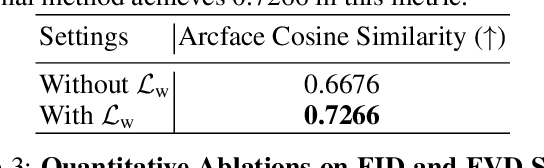

Realistic generative face video synthesis has long been a pursuit in both computer vision and graphics community. However, existing face video generation methods tend to produce low-quality frames with drifted facial identities and unnatural movements. To tackle these challenges, we propose a principled framework named StyleFaceV, which produces high-fidelity identity-preserving face videos with vivid movements. Our core insight is to decompose appearance and pose information and recompose them in the latent space of StyleGAN3 to produce stable and dynamic results. Specifically, StyleGAN3 provides strong priors for high-fidelity facial image generation, but the latent space is intrinsically entangled. By carefully examining its latent properties, we propose our decomposition and recomposition designs which allow for the disentangled combination of facial appearance and movements. Moreover, a temporal-dependent model is built upon the decomposed latent features, and samples reasonable sequences of motions that are capable of generating realistic and temporally coherent face videos. Particularly, our pipeline is trained with a joint training strategy on both static images and high-quality video data, which is of higher data efficiency. Extensive experiments demonstrate that our framework achieves state-of-the-art face video generation results both qualitatively and quantitatively. Notably, StyleFaceV is capable of generating realistic $1024\times1024$ face videos even without high-resolution training videos.
CelebV-HQ: A Large-Scale Video Facial Attributes Dataset
Jul 25, 2022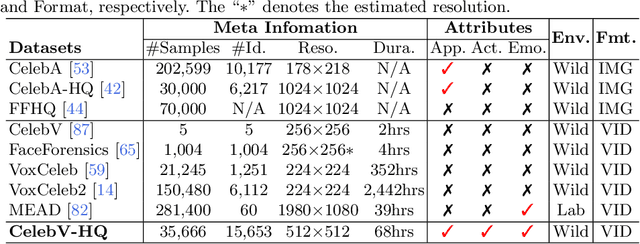
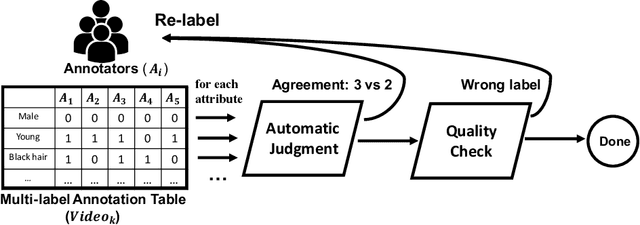

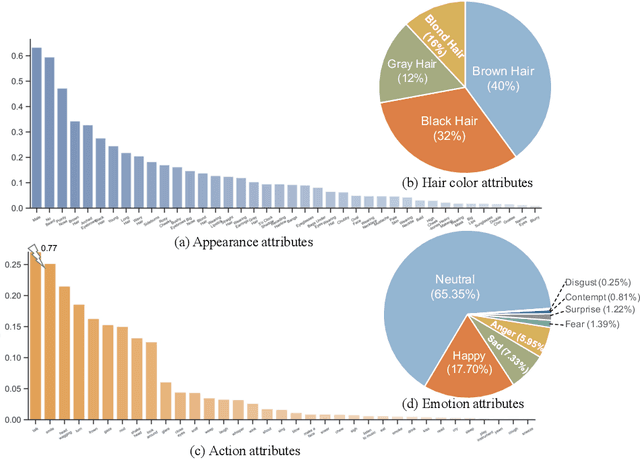
Large-scale datasets have played indispensable roles in the recent success of face generation/editing and significantly facilitated the advances of emerging research fields. However, the academic community still lacks a video dataset with diverse facial attribute annotations, which is crucial for the research on face-related videos. In this work, we propose a large-scale, high-quality, and diverse video dataset with rich facial attribute annotations, named the High-Quality Celebrity Video Dataset (CelebV-HQ). CelebV-HQ contains 35,666 video clips with the resolution of 512x512 at least, involving 15,653 identities. All clips are labeled manually with 83 facial attributes, covering appearance, action, and emotion. We conduct a comprehensive analysis in terms of age, ethnicity, brightness stability, motion smoothness, head pose diversity, and data quality to demonstrate the diversity and temporal coherence of CelebV-HQ. Besides, its versatility and potential are validated on two representative tasks, i.e., unconditional video generation and video facial attribute editing. Furthermore, we envision the future potential of CelebV-HQ, as well as the new opportunities and challenges it would bring to related research directions. Data, code, and models are publicly available. Project page: https://celebv-hq.github.io.