 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimization-Guided Diffusion for Interactive Scene Generation
Dec 11, 2025



Realistic and diverse multi-agent driving scenes are crucial for evaluating autonomous vehicles, but safety-critical events which are essential for this task are rare and underrepresented in driving datasets. Data-driven scene generation offers a low-cost alternative by synthesizing complex traffic behaviors from existing driving logs. However, existing models often lack controllability or yield samples that violate physical or social constraints, limiting their usability. We present OMEGA, an optimization-guided, training-free framework that enforces structural consistency and interaction awareness during diffusion-based sampling from a scene generation model. OMEGA re-anchors each reverse diffusion step via constrained optimization, steering the generation towards physically plausible and behaviorally coherent trajectories. Building on this framework, we formulate ego-attacker interactions as a game-theoretic optimization in the distribution space, approximating Nash equilibria to generate realistic, safety-critical adversarial scenarios. Experiments on nuPlan and Waymo show that OMEGA improves generation realism, consistency, and controllability, increasing the ratio of physically and behaviorally valid scenes from 32.35% to 72.27% for free exploration capabilities, and from 11% to 80% for controllability-focused generation. Our approach can also generate $5\times$ more near-collision frames with a time-to-collision under three seconds while maintaining the overall scene realism.
Geo-R1: Improving Few-Shot Geospatial Referring Expression Understanding with Reinforcement Fine-Tuning
Sep 26, 2025



Referring expression understanding in remote sensing poses unique challenges, as it requires reasoning over complex object-context relationships. While supervised fine-tuning (SFT) on multimodal large language models achieves strong performance with massive labeled datasets, they struggle in data-scarce scenarios, leading to poor generalization. To address this limitation, we propose Geo-R1, a reasoning-centric reinforcement fine-tuning (RFT) paradigm for few-shot geospatial referring. Geo-R1 enforces the model to first generate explicit, interpretable reasoning chains that decompose referring expressions, and then leverage these rationales to localize target objects. This "reason first, then act" process enables the model to make more effective use of limited annotations, enhances generalization, and provides interpretability. We validate Geo-R1 on three carefully designed few-shot geospatial referring benchmarks, where our model consistently and substantially outperforms SFT baselines. It also demonstrates strong cross-dataset generalization, highlighting its robustness. Code and data will be released at http://geo-r1.github.io.
MoE-CE: Enhancing Generalization for Deep Learning based Channel Estimation via a Mixture-of-Experts Framework
Sep 19, 2025Reliable channel estimation (CE) is fundamental for robust communication in dynamic wireless environments, where models must generalize across varying conditions such as signal-to-noise ratios (SNRs), the number of resource blocks (RBs), and channel profiles. Traditional deep learning (DL)-based methods struggle to generalize effectively across such diverse settings, particularly under multitask and zero-shot scenarios. In this work, we propose MoE-CE, a flexible mixture-of-experts (MoE) framework designed to enhance the generalization capability of DL-based CE methods. MoE-CE provides an appropriate inductive bias by leveraging multiple expert subnetworks, each specialized in distinct channel characteristics, and a learned router that dynamically selects the most relevant experts per input. This architecture enhances model capacity and adaptability without a proportional rise in computational cost while being agnostic to the choice of the backbone model and the learning algorithm. Through extensive experiments on synthetic datasets generated under diverse SNRs, RB numbers, and channel profiles, including multitask and zero-shot evaluations, we demonstrate that MoE-CE consistently outperforms conventional DL approaches, achieving significant performance gains while maintaining efficiency.
FCPE: A Fast Context-based Pitch Estimation Model
Sep 18, 2025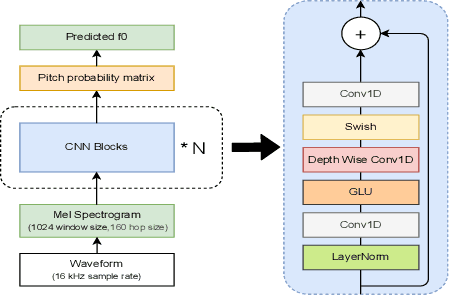
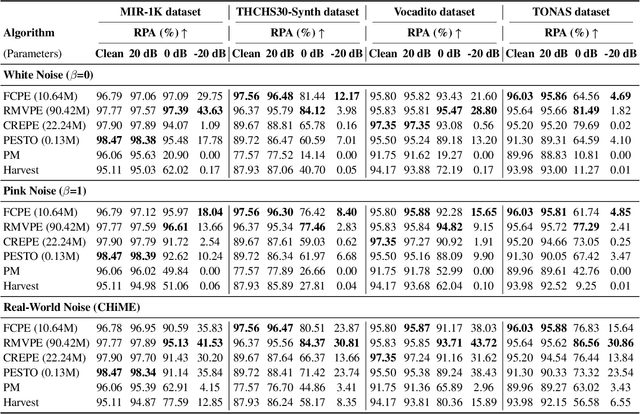
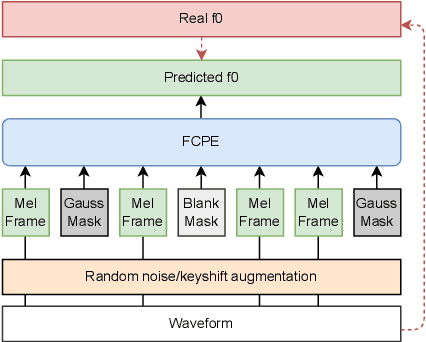

Pitch estimation (PE) in monophonic audio is crucial for MIDI transcription and singing voice conversion (SVC), but existing methods suffer significant performance degradation under noise. In this paper, we propose FCPE, a fast context-based pitch estimation model that employs a Lynx-Net architecture with depth-wise separable convolutions to effectively capture mel spectrogram features while maintaining low computational cost and robust noise tolerance. Experiments show that our method achieves 96.79\% Raw Pitch Accuracy (RPA) on the MIR-1K dataset, on par with the state-of-the-art methods. The Real-Time Factor (RTF) is 0.0062 on a single RTX 4090 GPU, which significantly outperforms existing algorithms in efficiency. Code is available at https://github.com/CNChTu/FCPE.
Implicit Counterfactual Learning for Audio-Visual Segmentation
Jul 28, 2025



Audio-visual segmentation (AVS) aims to segment objects in videos based on audio cues. Existing AVS methods are primarily designed to enhance interaction efficiency but pay limited attention to modality representation discrepancies and imbalances. To overcome this, we propose the implicit counterfactual framework (ICF) to achieve unbiased cross-modal understanding. Due to the lack of semantics, heterogeneous representations may lead to erroneous matches, especially in complex scenes with ambiguous visual content or interference from multiple audio sources. We introduce the multi-granularity implicit text (MIT) involving video-, segment- and frame-level as the bridge to establish the modality-shared space, reducing modality gaps and providing prior guidance. Visual content carries more information and typically dominates, thereby marginalizing audio features in the decision-making. To mitigate knowledge preference, we propose the semantic counterfactual (SC) to learn orthogonal representations in the latent space, generating diverse counterfactual samples, thus avoiding biases introduced by complex functional designs and explicit modifications of text structures or attributes. We further formulate the collaborative distribution-aware contrastive learning (CDCL), incorporating factual-counterfactual and inter-modality contrasts to align representations, promoting cohesion and decoupling. Extensive experiments on three public datasets validate that the proposed method achieves state-of-the-art performance.
Learning Physical Interaction Skills from Human Demonstrations
Jul 28, 2025



Learning physical interaction skills, such as dancing, handshaking, or sparring, remains a fundamental challenge for agents operating in human environments, particularly when the agent's morphology differs significantly from that of the demonstrator. Existing approaches often rely on handcrafted objectives or morphological similarity, limiting their capacity for generalization. Here, we introduce a framework that enables agents with diverse embodiments to learn wholebbody interaction behaviors directly from human demonstrations. The framework extracts a compact, transferable representation of interaction dynamics, called the Embedded Interaction Graph (EIG), which captures key spatiotemporal relationships between the interacting agents. This graph is then used as an imitation objective to train control policies in physics-based simulations, allowing the agent to generate motions that are both semantically meaningful and physically feasible. We demonstrate BuddyImitation on multiple agents, such as humans, quadrupedal robots with manipulators, or mobile manipulators and various interaction scenarios, including sparring, handshaking, rock-paper-scissors, or dancing. Our results demonstrate a promising path toward coordinated behaviors across morphologically distinct characters via cross embodiment interaction learning.
MultiTaskDeltaNet: Change Detection-based Image Segmentation for Operando ETEM with Application to Carbon Gasification Kinetics
Jul 22, 2025



Transforming in-situ transmission electron microscopy (TEM) imaging into a tool for spatially-resolved operando characterization of solid-state reactions requires automated, high-precision semantic segmentation of dynamically evolving features. However, traditional deep learning methods for semantic segmentation often encounter limitations due to the scarcity of labeled data, visually ambiguous features of interest, and small-object scenarios. To tackle these challenges, we introduce MultiTaskDeltaNet (MTDN), a novel deep learning architecture that creatively reconceptualizes the segmentation task as a change detection problem. By implementing a unique Siamese network with a U-Net backbone and using paired images to capture feature changes, MTDN effectively utilizes minimal data to produce high-quality segmentations. Furthermore, MTDN utilizes a multi-task learning strategy to leverage correlations between physical features of interest. In an evaluation using data from in-situ environmental TEM (ETEM) videos of filamentous carbon gasification, MTDN demonstrated a significant advantage over conventional segmentation models, particularly in accurately delineating fine structural features. Notably, MTDN achieved a 10.22% performance improvement over conventional segmentation models in predicting small and visually ambiguous physical features. This work bridges several key gaps between deep learning and practical TEM image analysis, advancing automated characterization of nanomaterials in complex experimental settings.
Reinforced Refinement with Self-Aware Expansion for End-to-End Autonomous Driving
Jun 11, 2025



End-to-end autonomous driving has emerged as a promising paradigm for directly mapping sensor inputs to planning maneuvers using learning-based modular integrations. However, existing imitation learning (IL)-based models suffer from generalization to hard cases, and a lack of corrective feedback loop under post-deployment. While reinforcement learning (RL) offers a potential solution to tackle hard cases with optimality, it is often hindered by overfitting to specific driving cases, resulting in catastrophic forgetting of generalizable knowledge and sample inefficiency. To overcome these challenges, we propose Reinforced Refinement with Self-aware Expansion (R2SE), a novel learning pipeline that constantly refines hard domain while keeping generalizable driving policy for model-agnostic end-to-end driving systems. Through reinforcement fine-tuning and policy expansion that facilitates continuous improvement, R2SE features three key components: 1) Generalist Pretraining with hard-case allocation trains a generalist imitation learning (IL) driving system while dynamically identifying failure-prone cases for targeted refinement; 2) Residual Reinforced Specialist Fine-tuning optimizes residual corrections using reinforcement learning (RL) to improve performance in hard case domain while preserving global driving knowledge; 3) Self-aware Adapter Expansion dynamically integrates specialist policies back into the generalist model, enhancing continuous performance improvement. Experimental results in closed-loop simulation and real-world datasets demonstrate improvements in generalization, safety, and long-horizon policy robustness over state-of-the-art E2E systems, highlighting the effectiveness of reinforce refinement for scalable autonomous driving.
Pseudo-Simulation for Autonomous Driving
Jun 04, 2025Existing evaluation paradigms for Autonomous Vehicles (AVs) face critical limitations. Real-world evaluation is often challenging due to safety concerns and a lack of reproducibility, whereas closed-loop simulation can face insufficient realism or high computational costs. Open-loop evaluation, while being efficient and data-driven, relies on metrics that generally overlook compounding errors. In this paper, we propose pseudo-simulation, a novel paradigm that addresses these limitations. Pseudo-simulation operates on real datasets, similar to open-loop evaluation, but augments them with synthetic observations generated prior to evaluation using 3D Gaussian Splatting. Our key idea is to approximate potential future states the AV might encounter by generating a diverse set of observations that vary in position, heading, and speed. Our method then assigns a higher importance to synthetic observations that best match the AV's likely behavior using a novel proximity-based weighting scheme. This enables evaluating error recovery and the mitigation of causal confusion, as in closed-loop benchmarks, without requiring sequential interactive simulation. We show that pseudo-simulation is better correlated with closed-loop simulations (R^2=0.8) than the best existing open-loop approach (R^2=0.7). We also establish a public leaderboard for the community to benchmark new methodologies with pseudo-simulation. Our code is available at https://github.com/autonomousvision/navsim.
TopoPoint: Enhance Topology Reasoning via Endpoint Detection in Autonomous Driving
May 23, 2025Topology reasoning, which unifies perception and structured reasoning, plays a vital role in understanding intersections for autonomous driving. However, its performance heavily relies on the accuracy of lane detection, particularly at connected lane endpoints. Existing methods often suffer from lane endpoints deviation, leading to incorrect topology construction. To address this issue, we propose TopoPoint, a novel framework that explicitly detects lane endpoints and jointly reasons over endpoints and lanes for robust topology reasoning. During training, we independently initialize point and lane query, and proposed Point-Lane Merge Self-Attention to enhance global context sharing through incorporating geometric distances between points and lanes as an attention mask . We further design Point-Lane Graph Convolutional Network to enable mutual feature aggregation between point and lane query. During inference, we introduce Point-Lane Geometry Matching algorithm that computes distances between detected points and lanes to refine lane endpoints, effectively mitigating endpoint deviation. Extensive experiments on the OpenLane-V2 benchmark demonstrate that TopoPoint achieves state-of-the-art performance in topology reasoning (48.8 on OLS). Additionally, we propose DET$_p$ to evaluate endpoint detection, under which our method significantly outperforms existing approaches (52.6 v.s. 45.2 on DET$_p$). The code is released at https://github.com/Franpin/TopoPoint.