 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFish Audio S2 Technical Report
Mar 11, 2026We introduce Fish Audio S2, an open-sourced text-to-speech system featuring multi-speaker, multi-turn generation, and, most importantly, instruction-following control via natural-language descriptions. To scale training, we develop a multi-stage training recipe together with a staged data pipeline covering video captioning and speech captioning, voice-quality assessment, and reward modeling. To push the frontier of open-source TTS, we release our model weights, fine-tuning code, and an SGLang-based inference engine. The inference engine is production-ready for streaming, achieving an RTF of 0.195 and a time-to-first-audio below 100 ms.Our code and weights are available on GitHub (https://github.com/fishaudio/fish-speech) and Hugging Face (https://huggingface.co/fishaudio/s2-pro). We highly encourage readers to visit https://fish.audio to try custom voices.
Physics Encoded Spatial and Temporal Generative Adversarial Network for Tropical Cyclone Image Super-resolution
Feb 19, 2026High-resolution satellite imagery is indispensable for tracking the genesis, intensification, and trajectory of tropical cyclones (TCs). However, existing deep learning-based super-resolution (SR) methods often treat satellite image sequences as generic videos, neglecting the underlying atmospheric physical laws governing cloud motion. To address this, we propose a Physics Encoded Spatial and Temporal Generative Adversarial Network (PESTGAN) for TC image super-resolution. Specifically, we design a disentangled generator architecture incorporating a PhyCell module, which approximates the vorticity equation via constrained convolutions and encodes the resulting approximate physical dynamics as implicit latent representations to separate physical dynamics from visual textures. Furthermore, a dual-discriminator framework is introduced, employing a temporal discriminator to enforce motion consistency alongside spatial realism. Experiments on the Digital Typhoon dataset for 4$\times$ upscaling demonstrate that PESTGAN establishes a better performance in structural fidelity and perceptual quality. While maintaining competitive pixel-wise accuracy compared to existing approaches, our method significantly excels in reconstructing meteorologically plausible cloud structures with superior physical fidelity.
FCPE: A Fast Context-based Pitch Estimation Model
Sep 18, 2025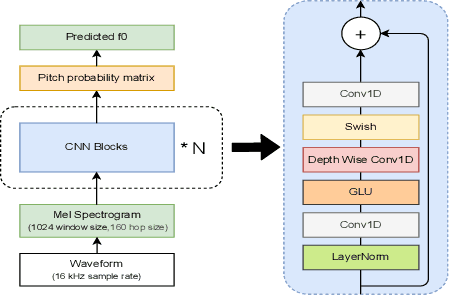
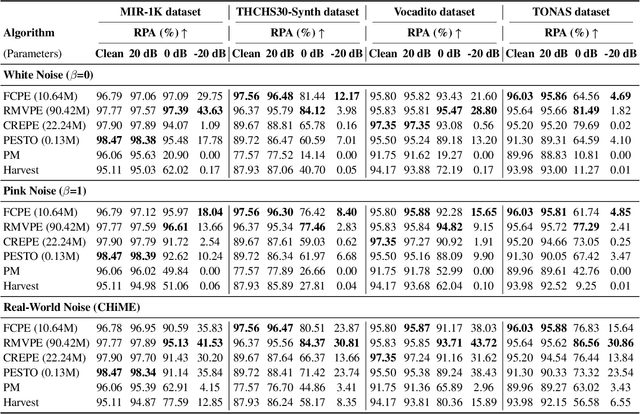
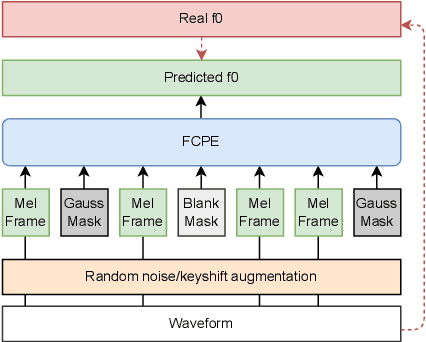

Pitch estimation (PE) in monophonic audio is crucial for MIDI transcription and singing voice conversion (SVC), but existing methods suffer significant performance degradation under noise. In this paper, we propose FCPE, a fast context-based pitch estimation model that employs a Lynx-Net architecture with depth-wise separable convolutions to effectively capture mel spectrogram features while maintaining low computational cost and robust noise tolerance. Experiments show that our method achieves 96.79\% Raw Pitch Accuracy (RPA) on the MIR-1K dataset, on par with the state-of-the-art methods. The Real-Time Factor (RTF) is 0.0062 on a single RTX 4090 GPU, which significantly outperforms existing algorithms in efficiency. Code is available at https://github.com/CNChTu/FCPE.
Real-IAD D3: A Real-World 2D/Pseudo-3D/3D Dataset for Industrial Anomaly Detection
Apr 19, 2025The increasing complexity of industrial anomaly detection (IAD) has positioned multimodal detection methods as a focal area of machine vision research. However, dedicated multimodal datasets specifically tailored for IAD remain limited. Pioneering datasets like MVTec 3D have laid essential groundwork in multimodal IAD by incorporating RGB+3D data, but still face challenges in bridging the gap with real industrial environments due to limitations in scale and resolution. To address these challenges, we introduce Real-IAD D3, a high-precision multimodal dataset that uniquely incorporates an additional pseudo3D modality generated through photometric stereo, alongside high-resolution RGB images and micrometer-level 3D point clouds. Real-IAD D3 features finer defects, diverse anomalies, and greater scale across 20 categories, providing a challenging benchmark for multimodal IAD Additionally, we introduce an effective approach that integrates RGB, point cloud, and pseudo-3D depth information to leverage the complementary strengths of each modality, enhancing detection performance. Our experiments highlight the importance of these modalities in boosting detection robustness and overall IAD performance. The dataset and code are publicly accessible for research purposes at https://realiad4ad.github.io/Real-IAD D3
Fish-Speech: Leveraging Large Language Models for Advanced Multilingual Text-to-Speech Synthesis
Nov 02, 2024



Text-to-Speech (TTS) systems face ongoing challenges in processing complex linguistic features, handling polyphonic expressions, and producing natural-sounding multilingual speech - capabilities that are crucial for future AI applications. In this paper, we present Fish-Speech, a novel framework that implements a serial fast-slow Dual Autoregressive (Dual-AR) architecture to enhance the stability of Grouped Finite Scalar Vector Quantization (GFSQ) in sequence generation tasks. This architecture improves codebook processing efficiency while maintaining high-fidelity outputs, making it particularly effective for AI interactions and voice cloning. Fish-Speech leverages Large Language Models (LLMs) for linguistic feature extraction, eliminating the need for traditional grapheme-to-phoneme (G2P) conversion and thereby streamlining the synthesis pipeline and enhancing multilingual support. Additionally, we developed FF-GAN through GFSQ to achieve superior compression ratios and near 100\% codebook utilization. Our approach addresses key limitations of current TTS systems while providing a foundation for more sophisticated, context-aware speech synthesis. Experimental results show that Fish-Speech significantly outperforms baseline models in handling complex linguistic scenarios and voice cloning tasks, demonstrating its potential to advance TTS technology in AI applications. The implementation is open source at \href{https://github.com/fishaudio/fish-speech}{https://github.com/fishaudio/fish-speech}.