 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyp2Former: Hierarchy-Aware Hyperbolic Embeddings for Open-Set Panoptic Segmentation
May 04, 2026Recognizing unknown objects is crucial for safety-critical applications such as autonomous driving and robotics. Open-Set Panoptic Segmentation (OPS) aims to segment known thing and stuff classes while identifying valid unknown objects as separate instances. Prior OPS approaches largely treat known categories as a flat label set, ignoring the semantic hierarchy that provides valuable structural priors for distinguishing unknown objects from in-distribution classes. In this work, we propose Hyp2Former, an end-to-end framework for OPS that does not require explicit modeling of unknowns during training, and instead learns hierarchical semantic similarities continuously in hyperbolic space. By explicitly encoding hierarchical relationships among known categories, the model learns a structured embedding space that captures multiple levels of semantic abstraction. As a result, unknown objects that cannot be confidently classified as known categories still remain in close proximity to higher-level concepts (e.g., an unknown animal remains closer to "animal" or "object" than to unrelated concepts such as "electronics" or "stuff") and can therefore be reliably detected, even if their fine-grained category was not represented during training. Empirical evaluations across multiple public datasets such as MS COCO, Cityscapes, and Lost&Found demonstrate that Hyp2Former outperforms existing methods on OPS, achieving the best balance between unknown object discovery and in-distribution robustness.
Leveraging Previous-Traversal Point Cloud Map Priors for Camera-Based 3D Object Detection and Tracking
Apr 28, 2026Camera-based 3D object detection and tracking are central to autonomous driving, yet precise 3D object localization remains fundamentally constrained by depth ambiguity when no expensive, depth-rich online LiDAR is available at inference. In many deployments, however, vehicles repeatedly traverse the same environments, making static point cloud maps from prior traversals a practical source of geometric priors. We propose DualViewMapDet, a camera-only inference framework that retrieves such map priors online and leverages them to mitigate the absence of a LiDAR sensor during deployment. The key idea is a dual-space camera-map fusion strategy that avoids one-sided view conversion. Specifically, we (i) project the map into perspective view (PV) and encode multi-channel geometric cues to enrich image features and support BEV lifting, and (ii) encode the map directly in bird's-eye view (BEV) with a sparse voxel backbone and fuse it with lifted camera features in a shared metric space. Extensive evaluations on nuScenes and Argoverse 2 demonstrate consistent improvements over strong camera-only baselines, with particularly strong gains in object localization. Ablations further validate the contributions of PV/BEV fusion and prior-map coverage. We make the code and pre-trained models available at https://dualviewmapdet.cs.uni-freiburg.de .
Latent Gaussian Splatting for 4D Panoptic Occupancy Tracking
Feb 26, 2026Capturing 4D spatiotemporal surroundings is crucial for the safe and reliable operation of robots in dynamic environments. However, most existing methods address only one side of the problem: they either provide coarse geometric tracking via bounding boxes, or detailed 3D structures like voxel-based occupancy that lack explicit temporal association. In this work, we present Latent Gaussian Splatting for 4D Panoptic Occupancy Tracking (LaGS) that advances spatiotemporal scene understanding in a holistic direction. Our approach incorporates camera-based end-to-end tracking with mask-based multi-view panoptic occupancy prediction, and addresses the key challenge of efficiently aggregating multi-view information into 3D voxel grids via a novel latent Gaussian splatting approach. Specifically, we first fuse observations into 3D Gaussians that serve as a sparse point-centric latent representation of the 3D scene, and then splat the aggregated features onto a 3D voxel grid that is decoded by a mask-based segmentation head. We evaluate LaGS on the Occ3D nuScenes and Waymo datasets, achieving state-of-the-art performance for 4D panoptic occupancy tracking. We make our code available at https://lags.cs.uni-freiburg.de/.
UP-Fuse: Uncertainty-guided LiDAR-Camera Fusion for 3D Panoptic Segmentation
Feb 22, 2026LiDAR-camera fusion enhances 3D panoptic segmentation by leveraging camera images to complement sparse LiDAR scans, but it also introduces a critical failure mode. Under adverse conditions, degradation or failure of the camera sensor can significantly compromise the reliability of the perception system. To address this problem, we introduce UP-Fuse, a novel uncertainty-aware fusion framework in the 2D range-view that remains robust under camera sensor degradation, calibration drift, and sensor failure. Raw LiDAR data is first projected into the range-view and encoded by a LiDAR encoder, while camera features are simultaneously extracted and projected into the same shared space. At its core, UP-Fuse employs an uncertainty-guided fusion module that dynamically modulates cross-modal interaction using predicted uncertainty maps. These maps are learned by quantifying representational divergence under diverse visual degradations, ensuring that only reliable visual cues influence the fused representation. The fused range-view features are decoded by a novel hybrid 2D-3D transformer that mitigates spatial ambiguities inherent to the 2D projection and directly predicts 3D panoptic segmentation masks. Extensive experiments on Panoptic nuScenes, SemanticKITTI, and our introduced Panoptic Waymo benchmark demonstrate the efficacy and robustness of UP-Fuse, which maintains strong performance even under severe visual corruption or misalignment, making it well suited for robotic perception in safety-critical settings.
DOS: Distilling Observable Softmaps of Zipfian Prototypes for Self-Supervised Point Representation
Dec 12, 2025Recent advances in self-supervised learning (SSL) have shown tremendous potential for learning 3D point cloud representations without human annotations. However, SSL for 3D point clouds still faces critical challenges due to irregular geometry, shortcut-prone reconstruction, and unbalanced semantics distribution. In this work, we propose DOS (Distilling Observable Softmaps), a novel SSL framework that self-distills semantic relevance softmaps only at observable (unmasked) points. This strategy prevents information leakage from masked regions and provides richer supervision than discrete token-to-prototype assignments. To address the challenge of unbalanced semantics in an unsupervised setting, we introduce Zipfian prototypes and incorporate them using a modified Sinkhorn-Knopp algorithm, Zipf-Sinkhorn, which enforces a power-law prior over prototype usage and modulates the sharpness of the target softmap during training. DOS outperforms current state-of-the-art methods on semantic segmentation and 3D object detection across multiple benchmarks, including nuScenes, Waymo, SemanticKITTI, ScanNet, and ScanNet200, without relying on extra data or annotations. Our results demonstrate that observable-point softmaps distillation offers a scalable and effective paradigm for learning robust 3D representations.
Pseudo-Simulation for Autonomous Driving
Jun 04, 2025Existing evaluation paradigms for Autonomous Vehicles (AVs) face critical limitations. Real-world evaluation is often challenging due to safety concerns and a lack of reproducibility, whereas closed-loop simulation can face insufficient realism or high computational costs. Open-loop evaluation, while being efficient and data-driven, relies on metrics that generally overlook compounding errors. In this paper, we propose pseudo-simulation, a novel paradigm that addresses these limitations. Pseudo-simulation operates on real datasets, similar to open-loop evaluation, but augments them with synthetic observations generated prior to evaluation using 3D Gaussian Splatting. Our key idea is to approximate potential future states the AV might encounter by generating a diverse set of observations that vary in position, heading, and speed. Our method then assigns a higher importance to synthetic observations that best match the AV's likely behavior using a novel proximity-based weighting scheme. This enables evaluating error recovery and the mitigation of causal confusion, as in closed-loop benchmarks, without requiring sequential interactive simulation. We show that pseudo-simulation is better correlated with closed-loop simulations (R^2=0.8) than the best existing open-loop approach (R^2=0.7). We also establish a public leaderboard for the community to benchmark new methodologies with pseudo-simulation. Our code is available at https://github.com/autonomousvision/navsim.
Decentralized and Asymmetric Multi-Agent Learning in Construction Sites
Sep 16, 2024



Multi-agent collaboration involves multiple participants working together in a shared environment to achieve a common goal. These agents share information, divide tasks, and synchronize their actions. Key aspects of multi agent collaboration include coordination, communication, task allocation, cooperation, adaptation, and decentralization. On construction sites, surface grading is the process of leveling sand piles to increase a specific area's height. In this scenario, a bulldozer grades while a dumper allocates sand piles. Our work aims to utilize a multi-agent approach to enable these vehicles to collaborate effectively. To this end, we propose a decentralized and asymmetric multi-agent learning approach for construction sites (DAMALCS). We formulate DAMALCS to reduce expected collisions for operating vehicles. Therefore, we develop two heuristic experts capable of achieving their joint goal optimally by applying an innovative prioritization method. In this approach, the bulldozer's movements take precedence over the dumper's operations, enabling the bulldozer to clear the path for the dumper and ensure continuous operation of both vehicles. Since heuristics alone are insufficient in real-world scenarios, we utilize them to train AI agents, which proves to be highly effective. We simultaneously train the bulldozer and dumper agents to operate within the same environment, aiming to avoid collisions and optimize performance in terms of time efficiency and sand volume handling. Our trained agents and heuristics are evaluated in both simulation and real-world lab experiments, testing them under various conditions, such as visual noise and localization errors. The results demonstrate that our approach significantly reduces collision rates for these vehicles.
AG2U -- Autonomous Grading Under Uncertainties
Aug 04, 2022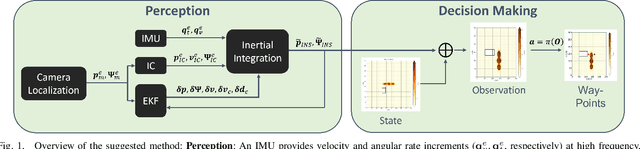
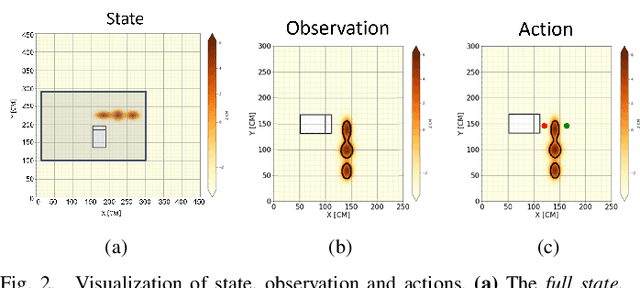
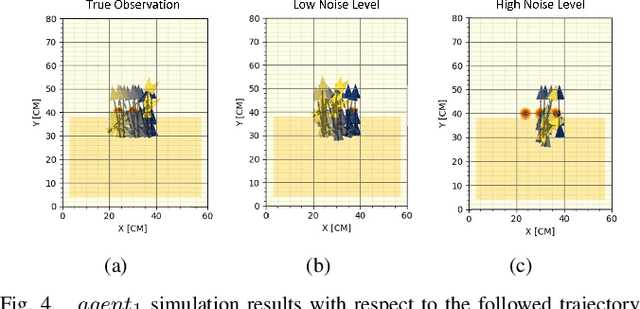
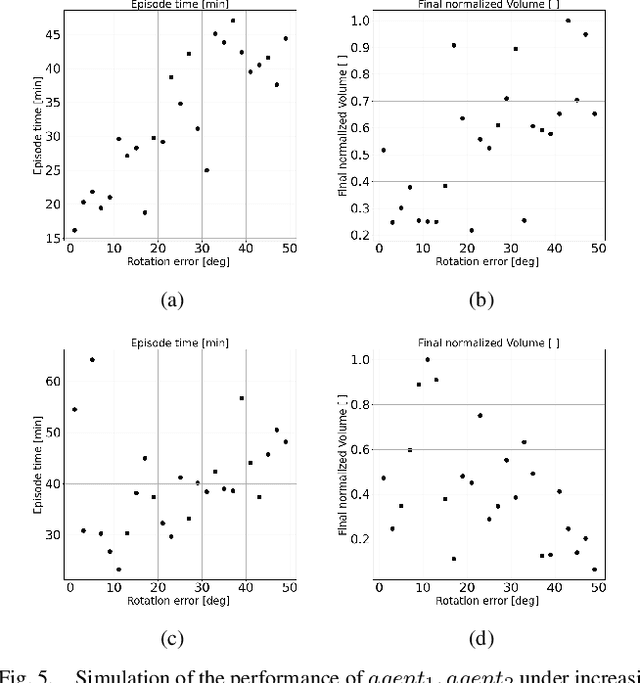
Surface grading, the process of leveling an uneven area containing pre-dumped sand piles, is an important task in the construction site pipeline. This labour-intensive process is often carried out by a dozer, a key machinery tool at any construction site. Current attempts to automate surface grading assume perfect localization. However, in real-world scenarios, this assumption fails, as agents are presented with imperfect perception, which leads to degraded performance. In this work, we address the problem of autonomous grading under uncertainties. First, we implement a simulation and a scaled real-world prototype environment to enable rapid policy exploration and evaluation in this setting. Second, we formalize the problem as a partially observable markov decision process and train an agent capable of handling such uncertainties. We show, through rigorous experiments, that an agent trained under perfect localization will suffer degraded performance when presented with localization uncertainties. However, an agent trained using our method will develop a more robust policy for addressing such errors and, consequently, exhibit a better grading performance.
DUQIM-Net: Probabilistic Object Hierarchy Representation for Multi-View Manipulation
Jul 19, 2022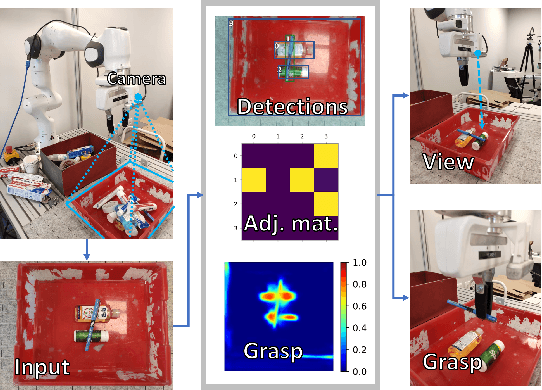
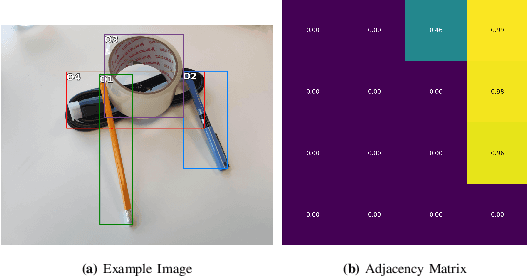
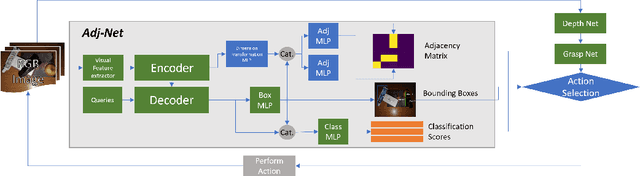
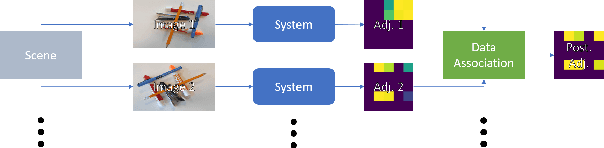
Object manipulation in cluttered scenes is a difficult and important problem in robotics. To efficiently manipulate objects, it is crucial to understand their surroundings, especially in cases where multiple objects are stacked one on top of the other, preventing effective grasping. We here present DUQIM-Net, a decision-making approach for object manipulation in a setting of stacked objects. In DUQIM-Net, the hierarchical stacking relationship is assessed using Adj-Net, a model that leverages existing Transformer Encoder-Decoder object detectors by adding an adjacency head. The output of this head probabilistically infers the underlying hierarchical structure of the objects in the scene. We utilize the properties of the adjacency matrix in DUQIM-Net to perform decision making and assist with object-grasping tasks. Our experimental results show that Adj-Net surpasses the state-of-the-art in object-relationship inference on the Visual Manipulation Relationship Dataset (VMRD), and that DUQIM-Net outperforms comparable approaches in bin clearing tasks.
Towards Autonomous Grading In The Real World
Jun 13, 2022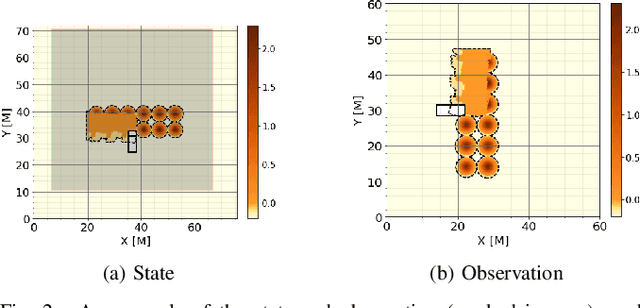
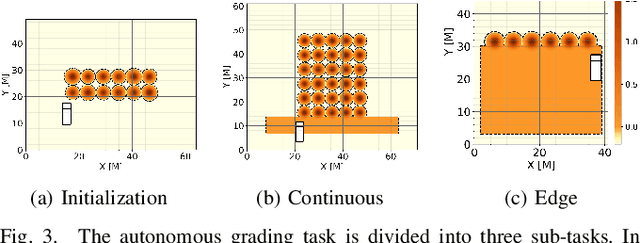
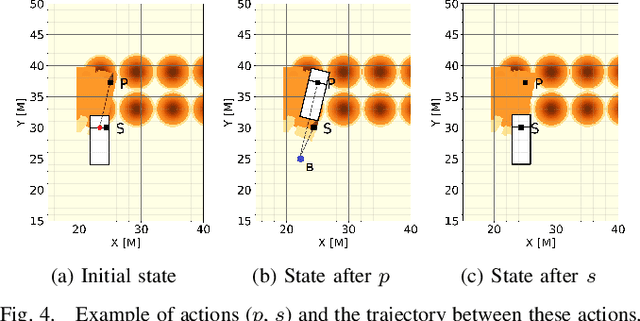
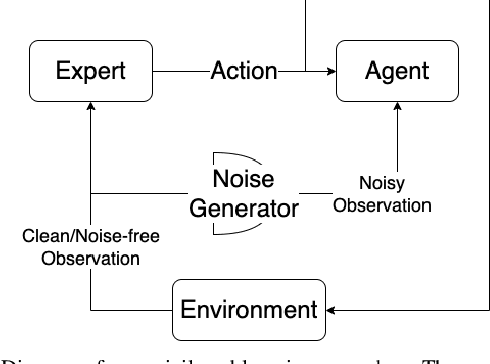
In this work, we aim to tackle the problem of autonomous grading, where a dozer is required to flatten an uneven area. In addition, we explore methods for bridging the gap between a simulated environment and real scenarios. We design both a realistic physical simulation and a scaled real prototype environment mimicking the real dozer dynamics and sensory information. We establish heuristics and learning strategies in order to solve the problem. Through extensive experimentation, we show that although heuristics are capable of tackling the problem in a clean and noise-free simulated environment, they fail catastrophically when facing real world scenarios. As the heuristics are capable of successfully solving the task in the simulated environment, we show they can be leveraged to guide a learning agent which can generalize and solve the task both in simulation and in a scaled prototype environment.