 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlannerRFT: Reinforcing Diffusion Planners through Closed-Loop and Sample-Efficient Fine-Tuning
Jan 19, 2026Diffusion-based planners have emerged as a promising approach for human-like trajectory generation in autonomous driving. Recent works incorporate reinforcement fine-tuning to enhance the robustness of diffusion planners through reward-oriented optimization in a generation-evaluation loop. However, they struggle to generate multi-modal, scenario-adaptive trajectories, hindering the exploitation efficiency of informative rewards during fine-tuning. To resolve this, we propose PlannerRFT, a sample-efficient reinforcement fine-tuning framework for diffusion-based planners. PlannerRFT adopts a dual-branch optimization that simultaneously refines the trajectory distribution and adaptively guides the denoising process toward more promising exploration, without altering the original inference pipeline. To support parallel learning at scale, we develop nuMax, an optimized simulator that achieves 10 times faster rollout compared to native nuPlan. Extensive experiments shows that PlannerRFT yields state-of-the-art performance with distinct behaviors emerging during the learning process.
Reinforced Refinement with Self-Aware Expansion for End-to-End Autonomous Driving
Jun 11, 2025



End-to-end autonomous driving has emerged as a promising paradigm for directly mapping sensor inputs to planning maneuvers using learning-based modular integrations. However, existing imitation learning (IL)-based models suffer from generalization to hard cases, and a lack of corrective feedback loop under post-deployment. While reinforcement learning (RL) offers a potential solution to tackle hard cases with optimality, it is often hindered by overfitting to specific driving cases, resulting in catastrophic forgetting of generalizable knowledge and sample inefficiency. To overcome these challenges, we propose Reinforced Refinement with Self-aware Expansion (R2SE), a novel learning pipeline that constantly refines hard domain while keeping generalizable driving policy for model-agnostic end-to-end driving systems. Through reinforcement fine-tuning and policy expansion that facilitates continuous improvement, R2SE features three key components: 1) Generalist Pretraining with hard-case allocation trains a generalist imitation learning (IL) driving system while dynamically identifying failure-prone cases for targeted refinement; 2) Residual Reinforced Specialist Fine-tuning optimizes residual corrections using reinforcement learning (RL) to improve performance in hard case domain while preserving global driving knowledge; 3) Self-aware Adapter Expansion dynamically integrates specialist policies back into the generalist model, enhancing continuous performance improvement. Experimental results in closed-loop simulation and real-world datasets demonstrate improvements in generalization, safety, and long-horizon policy robustness over state-of-the-art E2E systems, highlighting the effectiveness of reinforce refinement for scalable autonomous driving.
Pseudo-Simulation for Autonomous Driving
Jun 04, 2025Existing evaluation paradigms for Autonomous Vehicles (AVs) face critical limitations. Real-world evaluation is often challenging due to safety concerns and a lack of reproducibility, whereas closed-loop simulation can face insufficient realism or high computational costs. Open-loop evaluation, while being efficient and data-driven, relies on metrics that generally overlook compounding errors. In this paper, we propose pseudo-simulation, a novel paradigm that addresses these limitations. Pseudo-simulation operates on real datasets, similar to open-loop evaluation, but augments them with synthetic observations generated prior to evaluation using 3D Gaussian Splatting. Our key idea is to approximate potential future states the AV might encounter by generating a diverse set of observations that vary in position, heading, and speed. Our method then assigns a higher importance to synthetic observations that best match the AV's likely behavior using a novel proximity-based weighting scheme. This enables evaluating error recovery and the mitigation of causal confusion, as in closed-loop benchmarks, without requiring sequential interactive simulation. We show that pseudo-simulation is better correlated with closed-loop simulations (R^2=0.8) than the best existing open-loop approach (R^2=0.7). We also establish a public leaderboard for the community to benchmark new methodologies with pseudo-simulation. Our code is available at https://github.com/autonomousvision/navsim.
Quantitative Representation of Scenario Difficulty for Autonomous Driving Based on Adversarial Policy Search
Aug 26, 2024Adversarial scenario generation is crucial for autonomous driving testing because it can efficiently simulate various challenge and complex traffic conditions. However, it is difficult to control current existing methods to generate desired scenarios, such as the ones with different conflict levels. Therefore, this paper proposes a data-driven quantitative method to represent scenario difficulty. Compared with rule-based discrete scenario difficulty representation method, the proposed algorithm can achieve continuous difficulty representation. Specifically, the environment agent is introduced, and a reinforcement learning method combined with mechanism knowledge is constructed for policy search to obtain an agent with adversarial behavior. The model parameters of the environment agent at different stages in the training process are extracted to construct a policy group, and then the agents with different adversarial intensity are obtained, which are used to realize data generation in different difficulty scenarios through the simulation environment. Finally, a data-driven scenario difficulty quantitative representation model is constructed, which is used to output the environment agent policy under different difficulties. The result analysis shows that the proposed algorithm can generate reasonable and interpretable scenarios with high discrimination, and can provide quantifiable difficulty representation without any expert logic rule design. The video link is https://www.youtube.com/watch?v=GceGdqAm9Ys.
A Safety-Oriented Self-Learning Algorithm for Autonomous Driving: Evolution Starting from a Basic Model
Aug 22, 2024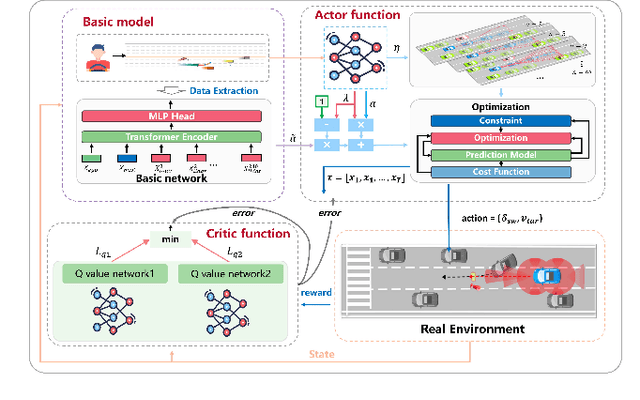
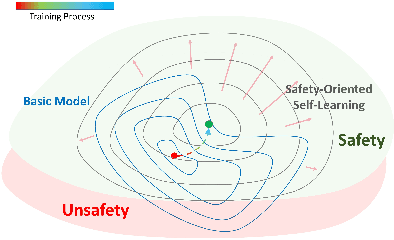
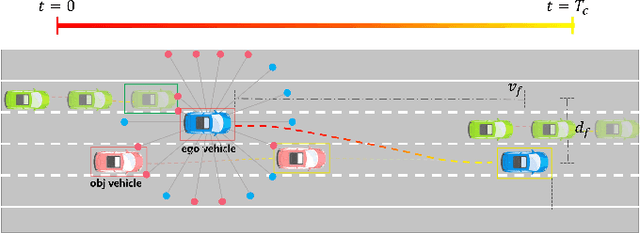
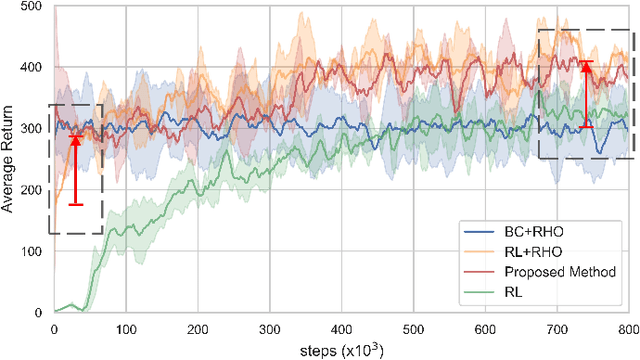
Autonomous driving vehicles with self-learning capabilities are expected to evolve in complex environments to improve their ability to cope with different scenarios. However, most self-learning algorithms suffer from low learning efficiency and lacking safety, which limits their applications. This paper proposes a safety-oriented self-learning algorithm for autonomous driving, which focuses on how to achieve evolution from a basic model. Specifically, a basic model based on the transformer encoder is designed to extract and output policy features from a small number of demonstration trajectories. To improve the learning efficiency, a policy mixed approach is developed. The basic model provides initial values to improve exploration efficiency, and the self-learning algorithm enhances the adaptability and generalization of the model, enabling continuous improvement without external intervention. Finally, an actor approximator based on receding horizon optimization is designed considering the constraints of the environmental input to ensure safety. The proposed method is verified in a challenging mixed traffic environment with pedestrians and vehicles. Simulation and real-vehicle test results show that the proposed method can safely and efficiently learn appropriate autonomous driving behaviors. Compared reinforcement learning and behavior cloning methods, it can achieve comprehensive improvement in learning efficiency and performance under the premise of ensuring safety.