 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThink Deep, Not Just Long: Measuring LLM Reasoning Effort via Deep-Thinking Tokens
Feb 13, 2026Large language models (LLMs) have demonstrated impressive reasoning capabilities by scaling test-time compute via long Chain-of-Thought (CoT). However, recent findings suggest that raw token counts are unreliable proxies for reasoning quality: increased generation length does not consistently correlate with accuracy and may instead signal "overthinking," leading to performance degradation. In this work, we quantify inference-time effort by identifying deep-thinking tokens -- tokens where internal predictions undergo significant revisions in deeper model layers prior to convergence. Across four challenging mathematical and scientific benchmarks (AIME 24/25, HMMT 25, and GPQA-diamond) and a diverse set of reasoning-focused models (GPT-OSS, DeepSeek-R1, and Qwen3), we show that deep-thinking ratio (the proportion of deep-thinking tokens in a generated sequence) exhibits a robust and consistently positive correlation with accuracy, substantially outperforming both length-based and confidence-based baselines. Leveraging this insight, we introduce Think@n, a test-time scaling strategy that prioritizes samples with high deep-thinking ratios. We demonstrate that Think@n matches or exceeds standard self-consistency performance while significantly reducing inference costs by enabling the early rejection of unpromising generations based on short prefixes.
LLM Cascade with Multi-Objective Optimal Consideration
Oct 10, 2024



Large Language Models (LLMs) have demonstrated exceptional capabilities in understanding and generating natural language. However, their high deployment costs often pose a barrier to practical applications, especially. Cascading local and server models offers a promising solution to this challenge. While existing studies on LLM cascades have primarily focused on the performance-cost trade-off, real-world scenarios often involve more complex requirements. This paper introduces a novel LLM Cascade strategy with Multi-Objective Optimization, enabling LLM cascades to consider additional objectives (e.g., privacy) and better align with the specific demands of real-world applications while maintaining their original cascading abilities. Extensive experiments on three benchmarks validate the effectiveness and superiority of our approach.
Non-intrusive Nonlinear Model Reduction via Machine Learning Approximations to Low-dimensional Operators
Jun 17, 2021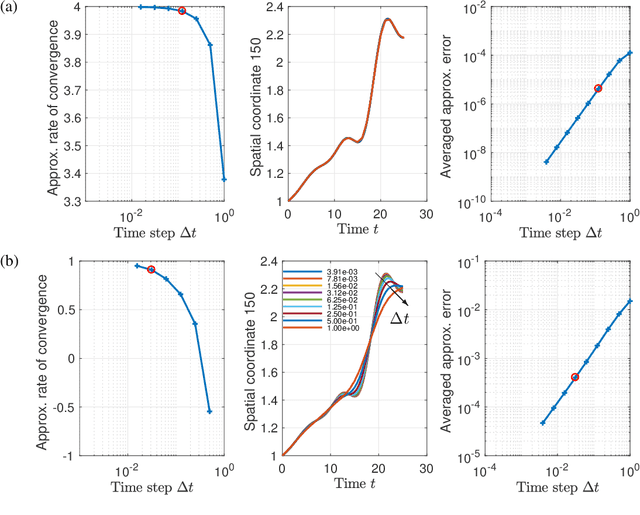
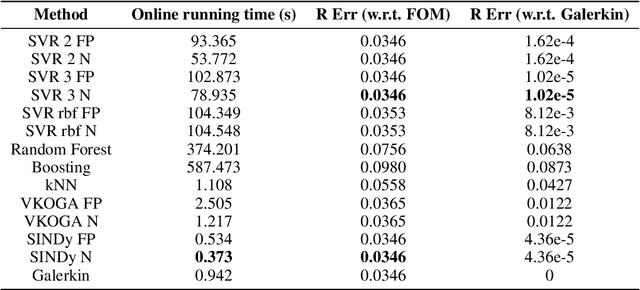
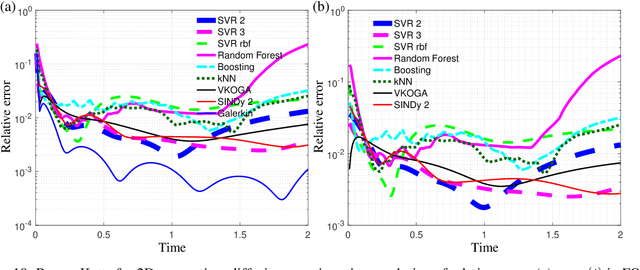
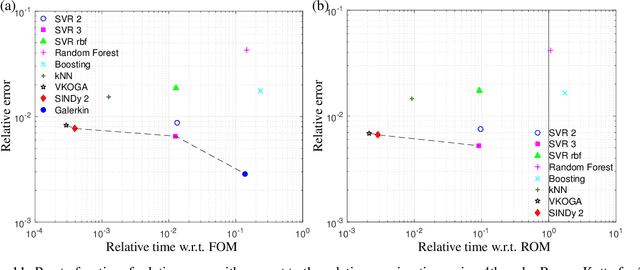
Although projection-based reduced-order models (ROMs) for parameterized nonlinear dynamical systems have demonstrated exciting results across a range of applications, their broad adoption has been limited by their intrusivity: implementing such a reduced-order model typically requires significant modifications to the underlying simulation code. To address this, we propose a method that enables traditionally intrusive reduced-order models to be accurately approximated in a non-intrusive manner. Specifically, the approach approximates the low-dimensional operators associated with projection-based reduced-order models (ROMs) using modern machine-learning regression techniques. The only requirement of the simulation code is the ability to export the velocity given the state and parameters as this functionality is used to train the approximated low-dimensional operators. In addition to enabling nonintrusivity, we demonstrate that the approach also leads to very low computational complexity, achieving up to $1000\times$ reduction in run time. We demonstrate the effectiveness of the proposed technique on two types of PDEs.