 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiagramRAG: A Lightweight Framework to Retrieve Scientific Diagram for Figure Generation
May 27, 2026Scientific diagrams are essential for communicating complex methodologies in academic papers. A natural way for researchers to specify such diagrams is through rough sketches, where text labels, connectors, and spatial arrangements express early semantic and topological intentions. However, sketches are usually incomplete, making them insufficient for directly producing publication-quality diagrams. Existing sketch-based generation methods mainly reconstruct the sketch itself, while recent text-driven diagram generation frameworks rely on textual semantics and do not fully exploit the topological structure contained in sketches. In this paper, we introduce DiagramRAG, a lightweight retrieval-augmented framework for sketch-based scientific diagram completion. Given a user sketch, DiagramRAG retrieves reference diagrams that are both semantically relevant to the sketch content and topologically compatible with its structure, and uses them to guide downstream diagram generation. To enable efficient structure-aware retrieval, we represent diagrams as knowledge graphs, synthesize sketch variants at different simplification levels, and train an embedding model to align sketches with compatible diagrams in a shared space. The retrieved references further provide content, topology, and visual priors for completing and rendering the final diagram. Experiments show that DiagramRAG achieves F1-scores of 0.848 and 0.802 on DiagramBank and FigureBench, respectively, and improves generation quality with the best VLM-as-a-Judge score of 7.170, while reducing inference latency to 35.48 seconds per sample. Our code and data are available at https://anonymous.4open.science/r/DiagramRAG-A262 and https://huggingface.co/datasets/anonymous-review-a262/DiagramSketch.
Not All Instances Are Equally Valuable: Towards Influence-Weighted Dataset Distillation
Oct 31, 2025Dataset distillation condenses large datasets into synthetic subsets, achieving performance comparable to training on the full dataset while substantially reducing storage and computation costs. Most existing dataset distillation methods assume that all real instances contribute equally to the process. In practice, real-world datasets contain both informative and redundant or even harmful instances, and directly distilling the full dataset without considering data quality can degrade model performance. In this work, we present Influence-Weighted Distillation IWD, a principled framework that leverages influence functions to explicitly account for data quality in the distillation process. IWD assigns adaptive weights to each instance based on its estimated impact on the distillation objective, prioritizing beneficial data while downweighting less useful or harmful ones. Owing to its modular design, IWD can be seamlessly integrated into diverse dataset distillation frameworks. Our empirical results suggest that integrating IWD tends to improve the quality of distilled datasets and enhance model performance, with accuracy gains of up to 7.8%.
Not All Documents Are What You Need for Extracting Instruction Tuning Data
May 18, 2025Instruction tuning improves the performance of large language models (LLMs), but it heavily relies on high-quality training data. Recently, LLMs have been used to synthesize instruction data using seed question-answer (QA) pairs. However, these synthesized instructions often lack diversity and tend to be similar to the input seeds, limiting their applicability in real-world scenarios. To address this, we propose extracting instruction tuning data from web corpora that contain rich and diverse knowledge. A naive solution is to retrieve domain-specific documents and extract all QA pairs from them, but this faces two key challenges: (1) extracting all QA pairs using LLMs is prohibitively expensive, and (2) many extracted QA pairs may be irrelevant to the downstream tasks, potentially degrading model performance. To tackle these issues, we introduce EQUAL, an effective and scalable data extraction framework that iteratively alternates between document selection and high-quality QA pair extraction to enhance instruction tuning. EQUAL first clusters the document corpus based on embeddings derived from contrastive learning, then uses a multi-armed bandit strategy to efficiently identify clusters that are likely to contain valuable QA pairs. This iterative approach significantly reduces computational cost while boosting model performance. Experiments on AutoMathText and StackOverflow across four downstream tasks show that EQUAL reduces computational costs by 5-10x and improves accuracy by 2.5 percent on LLaMA-3.1-8B and Mistral-7B
LEAD: Iterative Data Selection for Efficient LLM Instruction Tuning
May 12, 2025Instruction tuning has emerged as a critical paradigm for improving the capabilities and alignment of large language models (LLMs). However, existing iterative model-aware data selection methods incur significant computational overhead, as they rely on repeatedly performing full-dataset model inference to estimate sample utility for subsequent training iterations, creating a fundamental efficiency bottleneck. In this paper, we propose LEAD, an efficient iterative data selection framework that accurately estimates sample utility entirely within the standard training loop, eliminating the need for costly additional model inference. At its core, LEAD introduces Instance-Level Dynamic Uncertainty (IDU), a theoretically grounded utility function combining instantaneous training loss, gradient-based approximation of loss changes, and exponential smoothing of historical loss signals. To further scale efficiently to large datasets, LEAD employs a two-stage, coarse-to-fine selection strategy, adaptively prioritizing informative clusters through a multi-armed bandit mechanism, followed by precise fine-grained selection of high-utility samples using IDU. Extensive experiments across four diverse benchmarks show that LEAD significantly outperforms state-of-the-art methods, improving average model performance by 6.1%-10.8% while using only 2.5% of the training data and reducing overall training time by 5-10x.
Handling Label Noise via Instance-Level Difficulty Modeling and Dynamic Optimization
May 01, 2025



Recent studies indicate that deep neural networks degrade in generalization performance under noisy supervision. Existing methods focus on isolating clean subsets or correcting noisy labels, facing limitations such as high computational costs, heavy hyperparameter tuning process, and coarse-grained optimization. To address these challenges, we propose a novel two-stage noisy learning framework that enables instance-level optimization through a dynamically weighted loss function, avoiding hyperparameter tuning. To obtain stable and accurate information about noise modeling, we introduce a simple yet effective metric, termed wrong event, which dynamically models the cleanliness and difficulty of individual samples while maintaining computational costs. Our framework first collects wrong event information and builds a strong base model. Then we perform noise-robust training on the base model, using a probabilistic model to handle the wrong event information of samples. Experiments on five synthetic and real-world LNL benchmarks demonstrate our method surpasses state-of-the-art methods in performance, achieves a nearly 75% reduction in computational time and improves model scalability.
Harnessing Diversity for Important Data Selection in Pretraining Large Language Models
Sep 25, 2024


Data selection is of great significance in pre-training large language models, given the variation in quality within the large-scale available training corpora. To achieve this, researchers are currently investigating the use of data influence to measure the importance of data instances, $i.e.,$ a high influence score indicates that incorporating this instance to the training set is likely to enhance the model performance. Consequently, they select the top-$k$ instances with the highest scores. However, this approach has several limitations. (1) Computing the influence of all available data is time-consuming. (2) The selected data instances are not diverse enough, which may hinder the pre-trained model's ability to generalize effectively to various downstream tasks. In this paper, we introduce \texttt{Quad}, a data selection approach that considers both quality and diversity by using data influence to achieve state-of-the-art pre-training results. In particular, noting that attention layers capture extensive semantic details, we have adapted the accelerated $iHVP$ computation methods for attention layers, enhancing our ability to evaluate the influence of data, $i.e.,$ its quality. For the diversity, \texttt{Quad} clusters the dataset into similar data instances within each cluster and diverse instances across different clusters. For each cluster, if we opt to select data from it, we take some samples to evaluate the influence to prevent processing all instances. To determine which clusters to select, we utilize the classic Multi-Armed Bandit method, treating each cluster as an arm. This approach favors clusters with highly influential instances (ensuring high quality) or clusters that have been selected less frequently (ensuring diversity), thereby well balancing between quality and diversity.
Cost-Effective In-Context Learning for Entity Resolution: A Design Space Exploration
Dec 07, 2023Entity resolution (ER) is an important data integration task with a wide spectrum of applications. The state-of-the-art solutions on ER rely on pre-trained language models (PLMs), which require fine-tuning on a lot of labeled matching/non-matching entity pairs. Recently, large languages models (LLMs), such as GPT-4, have shown the ability to perform many tasks without tuning model parameters, which is known as in-context learning (ICL) that facilitates effective learning from a few labeled input context demonstrations. However, existing ICL approaches to ER typically necessitate providing a task description and a set of demonstrations for each entity pair and thus have limitations on the monetary cost of interfacing LLMs. To address the problem, in this paper, we provide a comprehensive study to investigate how to develop a cost-effective batch prompting approach to ER. We introduce a framework BATCHER consisting of demonstration selection and question batching and explore different design choices that support batch prompting for ER. We also devise a covering-based demonstration selection strategy that achieves an effective balance between matching accuracy and monetary cost. We conduct a thorough evaluation to explore the design space and evaluate our proposed strategies. Through extensive experiments, we find that batch prompting is very cost-effective for ER, compared with not only PLM-based methods fine-tuned with extensive labeled data but also LLM-based methods with manually designed prompting. We also provide guidance for selecting appropriate design choices for batch prompting.
Crowd-Powered Data Mining
Oct 19, 2018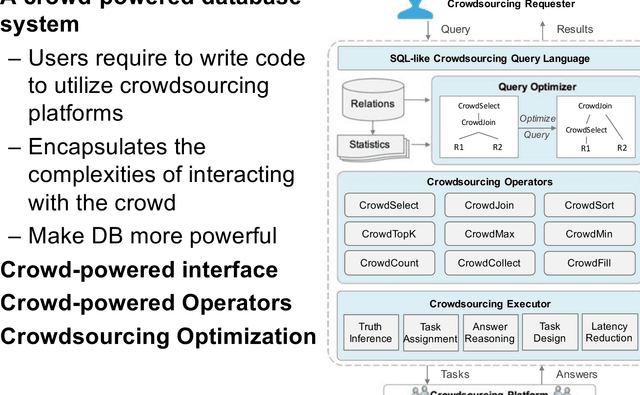
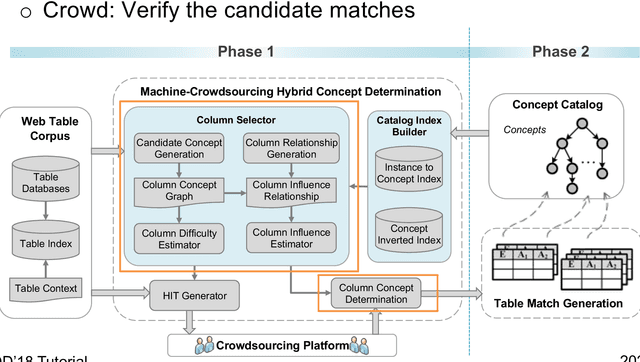
Many data mining tasks cannot be completely addressed by auto- mated processes, such as sentiment analysis and image classification. Crowdsourcing is an effective way to harness the human cognitive ability to process these machine-hard tasks. Thanks to public crowdsourcing platforms, e.g., Amazon Mechanical Turk and Crowd- Flower, we can easily involve hundreds of thousands of ordinary workers (i.e., the crowd) to address these machine-hard tasks. In this tutorial, we will survey and synthesize a wide spectrum of existing studies on crowd-powered data mining. We first give an overview of crowdsourcing, and then summarize the fundamental techniques, including quality control, cost control, and latency control, which must be considered in crowdsourced data mining. Next we review crowd-powered data mining operations, including classification, clustering, pattern mining, machine learning using the crowd (including deep learning, transfer learning and semi-supervised learning) and knowledge discovery. Finally, we provide the emerging challenges in crowdsourced data mining.