 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNot All Documents Are What You Need for Extracting Instruction Tuning Data
May 18, 2025Instruction tuning improves the performance of large language models (LLMs), but it heavily relies on high-quality training data. Recently, LLMs have been used to synthesize instruction data using seed question-answer (QA) pairs. However, these synthesized instructions often lack diversity and tend to be similar to the input seeds, limiting their applicability in real-world scenarios. To address this, we propose extracting instruction tuning data from web corpora that contain rich and diverse knowledge. A naive solution is to retrieve domain-specific documents and extract all QA pairs from them, but this faces two key challenges: (1) extracting all QA pairs using LLMs is prohibitively expensive, and (2) many extracted QA pairs may be irrelevant to the downstream tasks, potentially degrading model performance. To tackle these issues, we introduce EQUAL, an effective and scalable data extraction framework that iteratively alternates between document selection and high-quality QA pair extraction to enhance instruction tuning. EQUAL first clusters the document corpus based on embeddings derived from contrastive learning, then uses a multi-armed bandit strategy to efficiently identify clusters that are likely to contain valuable QA pairs. This iterative approach significantly reduces computational cost while boosting model performance. Experiments on AutoMathText and StackOverflow across four downstream tasks show that EQUAL reduces computational costs by 5-10x and improves accuracy by 2.5 percent on LLaMA-3.1-8B and Mistral-7B
A Semi-Synthetic Dataset Generation Framework for Causal Inference in Recommender Systems
Feb 23, 2022
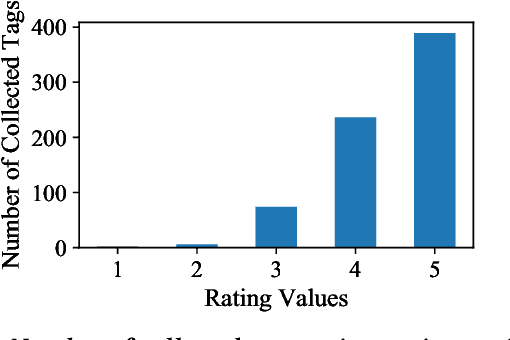
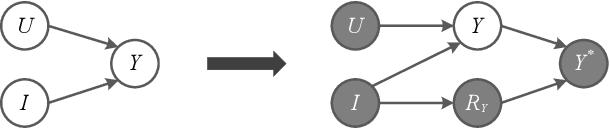
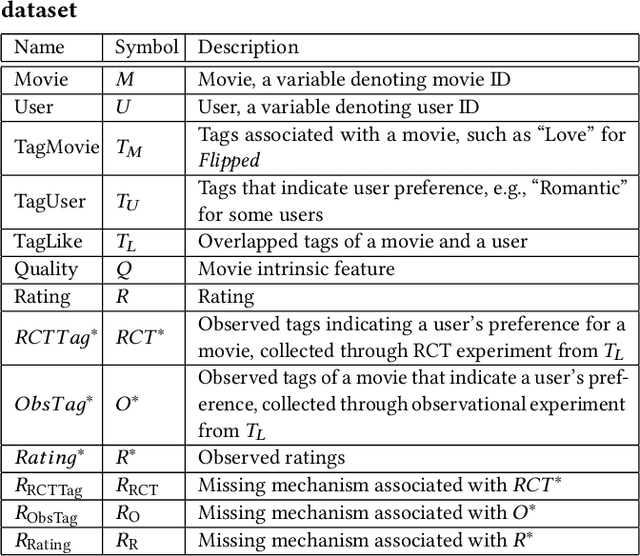
Accurate recommendation and reliable explanation are two key issues for modern recommender systems. However, most recommendation benchmarks only concern the prediction of user-item ratings while omitting the underlying causes behind the ratings. For example, the widely-used Yahoo!R3 dataset contains little information on the causes of the user-movie ratings. A solution could be to conduct surveys and require the users to provide such information. In practice, the user surveys can hardly avoid compliance issues and sparse user responses, which greatly hinders the exploration of causality-based recommendation. To better support the studies of causal inference and further explanations in recommender systems, we propose a novel semi-synthetic data generation framework for recommender systems where causal graphical models with missingness are employed to describe the causal mechanism of practical recommendation scenarios. To illustrate the use of our framework, we construct a semi-synthetic dataset with Causal Tags And Ratings (CTAR), based on the movies as well as their descriptive tags and rating information collected from a famous movie rating website. Using the collected data and the causal graph, the user-item-ratings and their corresponding user-item-tags are automatically generated, which provides the reasons (selected tags) why the user rates the items. Descriptive statistics and baseline results regarding the CTAR dataset are also reported. The proposed data generation framework is not limited to recommendation, and the released APIs can be used to generate customized datasets for other research tasks.
Causal Analysis Framework for Recommendation
Jan 18, 2022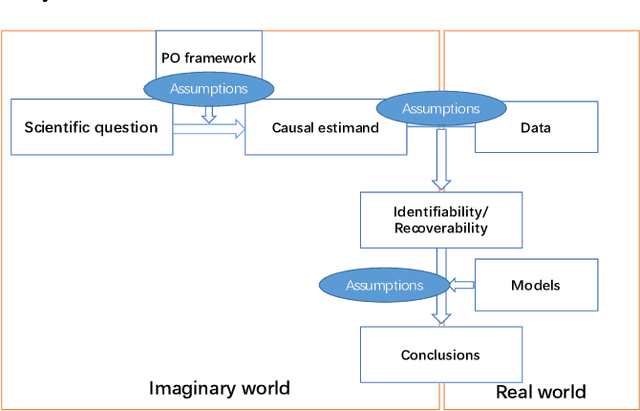
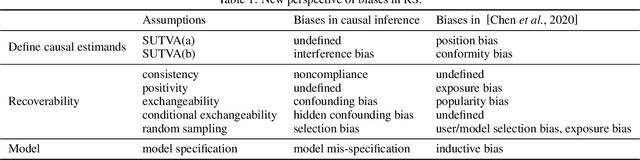
Recently, recommendation based on causal inference has gained much attention in the industrial community. The introduction of causal techniques into recommender systems (RS) has brought great development to this field and has gradually become a trend. However, a unified causal analysis framework has not been established yet. On one hand, the existing causal methods in RS lack a clear causal and mathematical formalization on the scientific questions of interest. Many confusions need to be clarified: what exactly is being estimated, for what purpose, in which scenario, by which technique, and under what plausible assumptions. On the other hand, technically speaking, the existence of various biases is the main obstacle to drawing causal conclusions from observed data. Yet, formal definitions of the biases in RS are still not clear. Both of the limitations greatly hinder the development of RS. In this paper, we attempt to give a causal analysis framework to accommodate different scenarios in RS, thereby providing a principled and rigorous operational guideline for causal recommendation. We first propose a step-by-step guideline on how to clarify and investigate problems in RS using causal concepts. Then, we provide a new taxonomy and give a formal definition of various biases in RS from the perspective of violating what assumptions are adopted in standard causal analysis. Finally, we find that many problems in RS can be well formalized into a few scenarios using the proposed causal analysis framework.