 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGood Token Hunting: A Hitchhiker's Guide to Token Selection for Visual Geometry Transformers
May 22, 2026Visual geometry transformers have become powerful architectures for multi-view 3D reconstruction, enabling joint prediction of multiple 3D attributes in a feed-forward manner. However, their computational cost grows quadratically with the input sequence length due to the global attention layers inside these models. This limits both their scalability and efficiency. In this work, we address this challenge with a simple yet general strategy: restricting the number of key/value tokens that each query interacts with during global attention. To achieve effective token selection, we introduce a two-stage framework. First, an inter-frame selection step operates at the frame level to identify frames that should be preserved. Second, an intra-frame selection step further discards more redundant tokens within the selected frames. Our analysis highlights the advantage of a diversity-based strategy for inter-frame selection, which ensures broad coverage of the scene. For intra-frame selection, we show that layer-aware sparsification is necessary, with the selection process guided by the entropy of the global attention pattern. Our approach offers a superior speed-accuracy trade-off compared to existing solutions. Extensive experiments show that it accelerates visual geometry transformers by over 85% for scenes with 500 images while maintaining, or even improving, baseline performance, which hints that how our token selection strategy can play a crucial role in future applications of visual geometry transformers. Our project website is available at https://zsh2000.github.io/good-token-hunting.github.io.
AnyUp: Universal Feature Upsampling
Oct 14, 2025



We introduce AnyUp, a method for feature upsampling that can be applied to any vision feature at any resolution, without encoder-specific training. Existing learning-based upsamplers for features like DINO or CLIP need to be re-trained for every feature extractor and thus do not generalize to different feature types at inference time. In this work, we propose an inference-time feature-agnostic upsampling architecture to alleviate this limitation and improve upsampling quality. In our experiments, AnyUp sets a new state of the art for upsampled features, generalizes to different feature types, and preserves feature semantics while being efficient and easy to apply to a wide range of downstream tasks.
Masks make discriminative models great again!
Jul 01, 2025We present Image2GS, a novel approach that addresses the challenging problem of reconstructing photorealistic 3D scenes from a single image by focusing specifically on the image-to-3D lifting component of the reconstruction process. By decoupling the lifting problem (converting an image to a 3D model representing what is visible) from the completion problem (hallucinating content not present in the input), we create a more deterministic task suitable for discriminative models. Our method employs visibility masks derived from optimized 3D Gaussian splats to exclude areas not visible from the source view during training. This masked training strategy significantly improves reconstruction quality in visible regions compared to strong baselines. Notably, despite being trained only on masked regions, Image2GS remains competitive with state-of-the-art discriminative models trained on full target images when evaluated on complete scenes. Our findings highlight the fundamental struggle discriminative models face when fitting unseen regions and demonstrate the advantages of addressing image-to-3D lifting as a distinct problem with specialized techniques.
LODGE: Level-of-Detail Large-Scale Gaussian Splatting with Efficient Rendering
May 29, 2025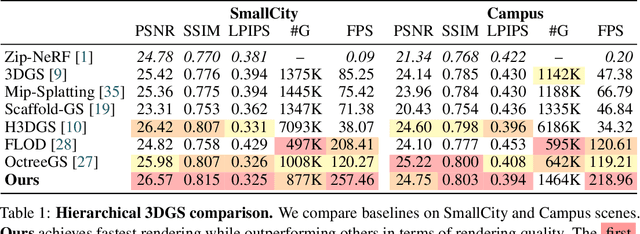
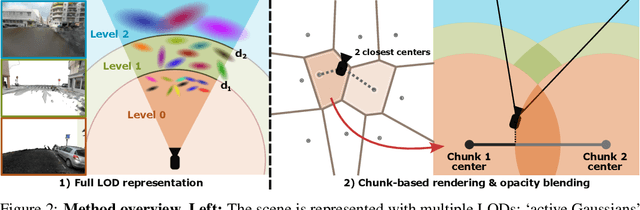
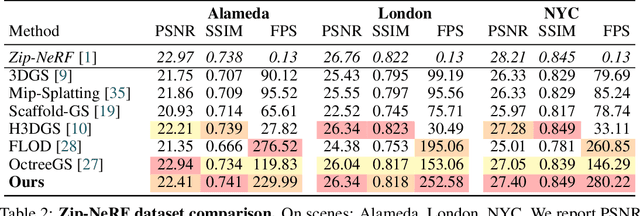
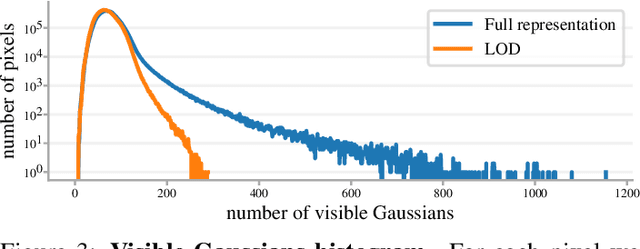
In this work, we present a novel level-of-detail (LOD) method for 3D Gaussian Splatting that enables real-time rendering of large-scale scenes on memory-constrained devices. Our approach introduces a hierarchical LOD representation that iteratively selects optimal subsets of Gaussians based on camera distance, thus largely reducing both rendering time and GPU memory usage. We construct each LOD level by applying a depth-aware 3D smoothing filter, followed by importance-based pruning and fine-tuning to maintain visual fidelity. To further reduce memory overhead, we partition the scene into spatial chunks and dynamically load only relevant Gaussians during rendering, employing an opacity-blending mechanism to avoid visual artifacts at chunk boundaries. Our method achieves state-of-the-art performance on both outdoor (Hierarchical 3DGS) and indoor (Zip-NeRF) datasets, delivering high-quality renderings with reduced latency and memory requirements.
Text To 3D Object Generation For Scalable Room Assembly
Apr 12, 2025



Modern machine learning models for scene understanding, such as depth estimation and object tracking, rely on large, high-quality datasets that mimic real-world deployment scenarios. To address data scarcity, we propose an end-to-end system for synthetic data generation for scalable, high-quality, and customizable 3D indoor scenes. By integrating and adapting text-to-image and multi-view diffusion models with Neural Radiance Field-based meshing, this system generates highfidelity 3D object assets from text prompts and incorporates them into pre-defined floor plans using a rendering tool. By introducing novel loss functions and training strategies into existing methods, the system supports on-demand scene generation, aiming to alleviate the scarcity of current available data, generally manually crafted by artists. This system advances the role of synthetic data in addressing machine learning training limitations, enabling more robust and generalizable models for real-world applications.
P2P-Bridge: Diffusion Bridges for 3D Point Cloud Denoising
Aug 29, 2024



In this work, we tackle the task of point cloud denoising through a novel framework that adapts Diffusion Schr\"odinger bridges to points clouds. Unlike previous approaches that predict point-wise displacements from point features or learned noise distributions, our method learns an optimal transport plan between paired point clouds. Experiments on object datasets like PU-Net and real-world datasets such as ScanNet++ and ARKitScenes show that P2P-Bridge achieves significant improvements over existing methods. While our approach demonstrates strong results using only point coordinates, we also show that incorporating additional features, such as color information or point-wise DINOv2 features, further enhances the performance. Code and pretrained models are available at https://p2p-bridge.github.io.
RadSplat: Radiance Field-Informed Gaussian Splatting for Robust Real-Time Rendering with 900+ FPS
Mar 20, 2024



Recent advances in view synthesis and real-time rendering have achieved photorealistic quality at impressive rendering speeds. While Radiance Field-based methods achieve state-of-the-art quality in challenging scenarios such as in-the-wild captures and large-scale scenes, they often suffer from excessively high compute requirements linked to volumetric rendering. Gaussian Splatting-based methods, on the other hand, rely on rasterization and naturally achieve real-time rendering but suffer from brittle optimization heuristics that underperform on more challenging scenes. In this work, we present RadSplat, a lightweight method for robust real-time rendering of complex scenes. Our main contributions are threefold. First, we use radiance fields as a prior and supervision signal for optimizing point-based scene representations, leading to improved quality and more robust optimization. Next, we develop a novel pruning technique reducing the overall point count while maintaining high quality, leading to smaller and more compact scene representations with faster inference speeds. Finally, we propose a novel test-time filtering approach that further accelerates rendering and allows to scale to larger, house-sized scenes. We find that our method enables state-of-the-art synthesis of complex captures at 900+ FPS.
UniSDF: Unifying Neural Representations for High-Fidelity 3D Reconstruction of Complex Scenes with Reflections
Dec 20, 2023Neural 3D scene representations have shown great potential for 3D reconstruction from 2D images. However, reconstructing real-world captures of complex scenes still remains a challenge. Existing generic 3D reconstruction methods often struggle to represent fine geometric details and do not adequately model reflective surfaces of large-scale scenes. Techniques that explicitly focus on reflective surfaces can model complex and detailed reflections by exploiting better reflection parameterizations. However, we observe that these methods are often not robust in real unbounded scenarios where non-reflective as well as reflective components are present. In this work, we propose UniSDF, a general purpose 3D reconstruction method that can reconstruct large complex scenes with reflections. We investigate both view-based as well as reflection-based color prediction parameterization techniques and find that explicitly blending these representations in 3D space enables reconstruction of surfaces that are more geometrically accurate, especially for reflective surfaces. We further combine this representation with a multi-resolution grid backbone that is trained in a coarse-to-fine manner, enabling faster reconstructions than prior methods. Extensive experiments on object-level datasets DTU, Shiny Blender as well as unbounded datasets Mip-NeRF 360 and Ref-NeRF real demonstrate that our method is able to robustly reconstruct complex large-scale scenes with fine details and reflective surfaces. Please see our project page at https://fangjinhuawang.github.io/UniSDF.
SparseFusion: Fusing Multi-Modal Sparse Representations for Multi-Sensor 3D Object Detection
Apr 27, 2023By identifying four important components of existing LiDAR-camera 3D object detection methods (LiDAR and camera candidates, transformation, and fusion outputs), we observe that all existing methods either find dense candidates or yield dense representations of scenes. However, given that objects occupy only a small part of a scene, finding dense candidates and generating dense representations is noisy and inefficient. We propose SparseFusion, a novel multi-sensor 3D detection method that exclusively uses sparse candidates and sparse representations. Specifically, SparseFusion utilizes the outputs of parallel detectors in the LiDAR and camera modalities as sparse candidates for fusion. We transform the camera candidates into the LiDAR coordinate space by disentangling the object representations. Then, we can fuse the multi-modality candidates in a unified 3D space by a lightweight self-attention module. To mitigate negative transfer between modalities, we propose novel semantic and geometric cross-modality transfer modules that are applied prior to the modality-specific detectors. SparseFusion achieves state-of-the-art performance on the nuScenes benchmark while also running at the fastest speed, even outperforming methods with stronger backbones. We perform extensive experiments to demonstrate the effectiveness and efficiency of our modules and overall method pipeline. Our code will be made publicly available at https://github.com/yichen928/SparseFusion.
NeRFMeshing: Distilling Neural Radiance Fields into Geometrically-Accurate 3D Meshes
Mar 16, 2023



With the introduction of Neural Radiance Fields (NeRFs), novel view synthesis has recently made a big leap forward. At the core, NeRF proposes that each 3D point can emit radiance, allowing to conduct view synthesis using differentiable volumetric rendering. While neural radiance fields can accurately represent 3D scenes for computing the image rendering, 3D meshes are still the main scene representation supported by most computer graphics and simulation pipelines, enabling tasks such as real time rendering and physics-based simulations. Obtaining 3D meshes from neural radiance fields still remains an open challenge since NeRFs are optimized for view synthesis, not enforcing an accurate underlying geometry on the radiance field. We thus propose a novel compact and flexible architecture that enables easy 3D surface reconstruction from any NeRF-driven approach. Upon having trained the radiance field, we distill the volumetric 3D representation into a Signed Surface Approximation Network, allowing easy extraction of the 3D mesh and appearance. Our final 3D mesh is physically accurate and can be rendered in real time on an array of devices.