 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage Generators are Generalist Vision Learners
Apr 22, 2026Recent works show that image and video generators exhibit zero-shot visual understanding behaviors, in a way reminiscent of how LLMs develop emergent capabilities of language understanding and reasoning from generative pretraining. While it has long been conjectured that the ability to create visual content implies an ability to understand it, there has been limited evidence that generative vision models have developed strong understanding capabilities. In this work, we demonstrate that image generation training serves a role similar to LLM pretraining, and lets models learn powerful and general visual representations that enable SOTA performance on various vision tasks. We introduce Vision Banana, a generalist model built by instruction-tuning Nano Banana Pro (NBP) on a mixture of its original training data alongside a small amount of vision task data. By parameterizing the output space of vision tasks as RGB images, we seamlessly reframe perception as image generation. Our generalist model, Vision Banana, achieves SOTA results on a variety of vision tasks involving both 2D and 3D understanding, beating or rivaling zero-shot domain-specialists, including Segment Anything Model 3 on segmentation tasks, and the Depth Anything series on metric depth estimation. We show that these results can be achieved with lightweight instruction-tuning without sacrificing the base model's image generation capabilities. The superior results suggest that image generation pretraining is a generalist vision learner. It also shows that image generation serves as a unified and universal interface for vision tasks, similar to text generation's role in language understanding and reasoning. We could be witnessing a major paradigm shift for computer vision, where generative vision pretraining takes a central role in building Foundational Vision Models for both generation and understanding.
CityRAG: Stepping Into a City via Spatially-Grounded Video Generation
Apr 21, 2026We address the problem of generating a 3D-consistent, navigable environment that is spatially grounded: a simulation of a real location. Existing video generative models can produce a plausible sequence that is consistent with a text (T2V) or image (I2V) prompt. However, the capability to reconstruct the real world under arbitrary weather conditions and dynamic object configurations is essential for downstream applications including autonomous driving and robotics simulation. To this end, we present CityRAG, a video generative model that leverages large corpora of geo-registered data as context to ground generation to the physical scene, while maintaining learned priors for complex motion and appearance changes. CityRAG relies on temporally unaligned training data, which teaches the model to semantically disentangle the underlying scene from its transient attributes. Our experiments demonstrate that CityRAG can generate coherent minutes-long, physically grounded video sequences, maintain weather and lighting conditions over thousands of frames, achieve loop closure, and navigate complex trajectories to reconstruct real-world geography.
Visual Chronicles: Using Multimodal LLMs to Analyze Massive Collections of Images
Apr 14, 2025



We present a system using Multimodal LLMs (MLLMs) to analyze a large database with tens of millions of images captured at different times, with the aim of discovering patterns in temporal changes. Specifically, we aim to capture frequent co-occurring changes ("trends") across a city over a certain period. Unlike previous visual analyses, our analysis answers open-ended queries (e.g., "what are the frequent types of changes in the city?") without any predetermined target subjects or training labels. These properties cast prior learning-based or unsupervised visual analysis tools unsuitable. We identify MLLMs as a novel tool for their open-ended semantic understanding capabilities. Yet, our datasets are four orders of magnitude too large for an MLLM to ingest as context. So we introduce a bottom-up procedure that decomposes the massive visual analysis problem into more tractable sub-problems. We carefully design MLLM-based solutions to each sub-problem. During experiments and ablation studies with our system, we find it significantly outperforms baselines and is able to discover interesting trends from images captured in large cities (e.g., "addition of outdoor dining,", "overpass was painted blue," etc.). See more results and interactive demos at https://boyangdeng.com/visual-chronicles.
SplatTalk: 3D VQA with Gaussian Splatting
Mar 08, 2025Language-guided 3D scene understanding is important for advancing applications in robotics, AR/VR, and human-computer interaction, enabling models to comprehend and interact with 3D environments through natural language. While 2D vision-language models (VLMs) have achieved remarkable success in 2D VQA tasks, progress in the 3D domain has been significantly slower due to the complexity of 3D data and the high cost of manual annotations. In this work, we introduce SplatTalk, a novel method that uses a generalizable 3D Gaussian Splatting (3DGS) framework to produce 3D tokens suitable for direct input into a pretrained LLM, enabling effective zero-shot 3D visual question answering (3D VQA) for scenes with only posed images. During experiments on multiple benchmarks, our approach outperforms both 3D models trained specifically for the task and previous 2D-LMM-based models utilizing only images (our setting), while achieving competitive performance with state-of-the-art 3D LMMs that additionally utilize 3D inputs.
Gaussian3Diff: 3D Gaussian Diffusion for 3D Full Head Synthesis and Editing
Dec 19, 2023



We present a novel framework for generating photorealistic 3D human head and subsequently manipulating and reposing them with remarkable flexibility. The proposed approach leverages an implicit function representation of 3D human heads, employing 3D Gaussians anchored on a parametric face model. To enhance representational capabilities and encode spatial information, we embed a lightweight tri-plane payload within each Gaussian rather than directly storing color and opacity. Additionally, we parameterize the Gaussians in a 2D UV space via a 3DMM, enabling effective utilization of the diffusion model for 3D head avatar generation. Our method facilitates the creation of diverse and realistic 3D human heads with fine-grained editing over facial features and expressions. Extensive experiments demonstrate the effectiveness of our method.
NIFTY: Neural Object Interaction Fields for Guided Human Motion Synthesis
Jul 14, 2023



We address the problem of generating realistic 3D motions of humans interacting with objects in a scene. Our key idea is to create a neural interaction field attached to a specific object, which outputs the distance to the valid interaction manifold given a human pose as input. This interaction field guides the sampling of an object-conditioned human motion diffusion model, so as to encourage plausible contacts and affordance semantics. To support interactions with scarcely available data, we propose an automated synthetic data pipeline. For this, we seed a pre-trained motion model, which has priors for the basics of human movement, with interaction-specific anchor poses extracted from limited motion capture data. Using our guided diffusion model trained on generated synthetic data, we synthesize realistic motions for sitting and lifting with several objects, outperforming alternative approaches in terms of motion quality and successful action completion. We call our framework NIFTY: Neural Interaction Fields for Trajectory sYnthesis.
Nerflets: Local Radiance Fields for Efficient Structure-Aware 3D Scene Representation from 2D Supervision
Mar 10, 2023We address efficient and structure-aware 3D scene representation from images. Nerflets are our key contribution -- a set of local neural radiance fields that together represent a scene. Each nerflet maintains its own spatial position, orientation, and extent, within which it contributes to panoptic, density, and radiance reconstructions. By leveraging only photometric and inferred panoptic image supervision, we can directly and jointly optimize the parameters of a set of nerflets so as to form a decomposed representation of the scene, where each object instance is represented by a group of nerflets. During experiments with indoor and outdoor environments, we find that nerflets: (1) fit and approximate the scene more efficiently than traditional global NeRFs, (2) allow the extraction of panoptic and photometric renderings from arbitrary views, and (3) enable tasks rare for NeRFs, such as 3D panoptic segmentation and interactive editing.
Polynomial Neural Fields for Subband Decomposition and Manipulation
Feb 09, 2023



Neural fields have emerged as a new paradigm for representing signals, thanks to their ability to do it compactly while being easy to optimize. In most applications, however, neural fields are treated like black boxes, which precludes many signal manipulation tasks. In this paper, we propose a new class of neural fields called polynomial neural fields (PNFs). The key advantage of a PNF is that it can represent a signal as a composition of a number of manipulable and interpretable components without losing the merits of neural fields representation. We develop a general theoretical framework to analyze and design PNFs. We use this framework to design Fourier PNFs, which match state-of-the-art performance in signal representation tasks that use neural fields. In addition, we empirically demonstrate that Fourier PNFs enable signal manipulation applications such as texture transfer and scale-space interpolation. Code is available at https://github.com/stevenygd/PNF.
OpenScene: 3D Scene Understanding with Open Vocabularies
Nov 28, 2022



Traditional 3D scene understanding approaches rely on labeled 3D datasets to train a model for a single task with supervision. We propose OpenScene, an alternative approach where a model predicts dense features for 3D scene points that are co-embedded with text and image pixels in CLIP feature space. This zero-shot approach enables task-agnostic training and open-vocabulary queries. For example, to perform SOTA zero-shot 3D semantic segmentation it first infers CLIP features for every 3D point and later classifies them based on similarities to embeddings of arbitrary class labels. More interestingly, it enables a suite of open-vocabulary scene understanding applications that have never been done before. For example, it allows a user to enter an arbitrary text query and then see a heat map indicating which parts of a scene match. Our approach is effective at identifying objects, materials, affordances, activities, and room types in complex 3D scenes, all using a single model trained without any labeled 3D data.
Panoptic Neural Fields: A Semantic Object-Aware Neural Scene Representation
May 09, 2022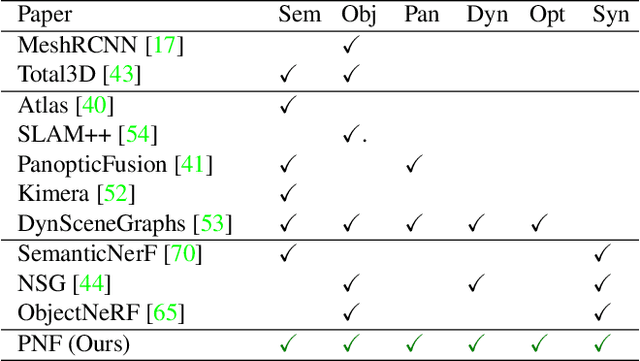
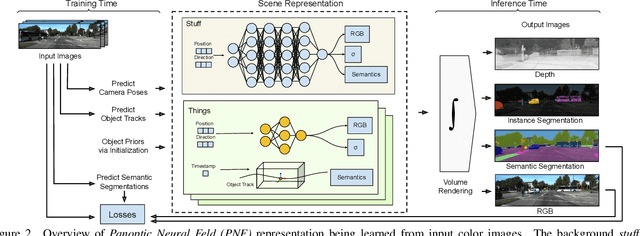
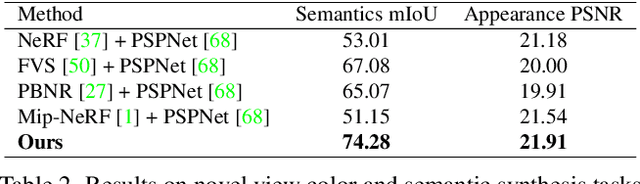
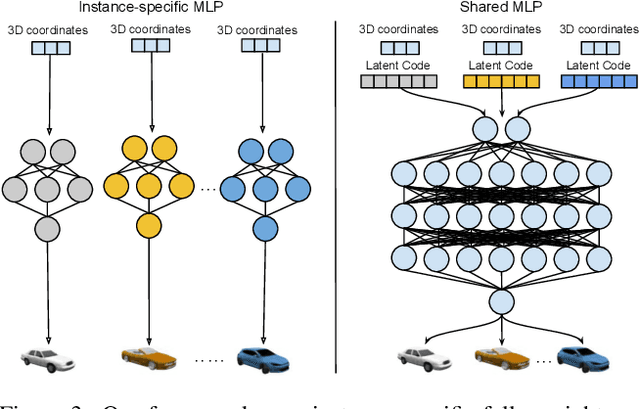
We present Panoptic Neural Fields (PNF), an object-aware neural scene representation that decomposes a scene into a set of objects (things) and background (stuff). Each object is represented by an oriented 3D bounding box and a multi-layer perceptron (MLP) that takes position, direction, and time and outputs density and radiance. The background stuff is represented by a similar MLP that additionally outputs semantic labels. Each object MLPs are instance-specific and thus can be smaller and faster than previous object-aware approaches, while still leveraging category-specific priors incorporated via meta-learned initialization. Our model builds a panoptic radiance field representation of any scene from just color images. We use off-the-shelf algorithms to predict camera poses, object tracks, and 2D image semantic segmentations. Then we jointly optimize the MLP weights and bounding box parameters using analysis-by-synthesis with self-supervision from color images and pseudo-supervision from predicted semantic segmentations. During experiments with real-world dynamic scenes, we find that our model can be used effectively for several tasks like novel view synthesis, 2D panoptic segmentation, 3D scene editing, and multiview depth prediction.