 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWorldMemArena: Evaluating Multimodal Agent Memory Through Action-World Interaction
May 28, 2026Multimodal large language models are increasingly deployed as long-horizon agents, where memory must do more than recall: it must track an evolving world, revise what has gone stale, and surface the right evidence at decision time. Existing benchmarks measure recall over static dialogue, collapse memory into a single end-of-task accuracy, and reduce visual observations to captions, leaving us unable to localize failures to writing, maintenance, retrieval, or use. The rise of agent harnesses that author their own memory sharpens this gap, since we have no principled way to compare hand-designed pipelines with self-managing alternatives. To close these gaps, we formulate multimodal agent memory as an Action-World Interaction Loop with an observable four-stage lifecycle, and instantiate it in WorldMemArena: 400 multi-session multimodal tasks spanning Lifelong Evolution (evolving personal and task states) and Agentic Execution (memory from real observations, actions, and feedback), annotated with gold memory points, updates, distractors, and evidence chains for stage-level diagnosis. This enables the first head-to-head comparison of long-context, manually designed (RAG and external memory systems), and harness-based memory agents. Results show that: (1) better memory writing and storage do not guarantee better performance; (2) multimodal memory still struggles to fully use visual evidence; (3) systems are unstable across domains and degrade on realistic agentic trajectories; and (4) harness memory is more flexible but remains costly and less reliable.
Auditing Agent Harness Safety
May 14, 2026LLM agents increasingly run inside execution harnesses that dispatch tools, allocate resources, and route messages between specialized components. However, a harness can return a correct, benign answer over a trajectory that accesses unauthorized resources or leaks context to the wrong agent. Output-level evaluation cannot see these failures, yet most safety benchmarks score only final outputs or terminal states, even though many violations occur mid-trajectory rather than at termination. The central question is whether the harness respects user intent, permission boundaries, and information-flow constraints throughout execution. To address this gap, we propose HarnessAudit, a framework that audits full execution trajectories across boundary compliance, execution fidelity, and system stability, with a focus on multi-agent harnesses where these risks are most pronounced. We further introduce HarnessAudit-Bench, a benchmark of 210 tasks across eight real-world domains, instantiated in both single-agent and multi-agent configurations with embedded safety constraints. Evaluating ten harness configurations across frontier models and three multi-agent frameworks, we find that: (i) task completion is misaligned with safe execution, and violations accumulate with trajectory length; (ii) safety risks vary across domains, task types, and agent roles; (iii) most violations concentrate in resource access and inter-agent information transfer; and (iv) multi-agent collaboration expands the safety risk surface, while harness design sets the upper bound of safe deployment.
Burst Image Quality Assessment: A New Benchmark and Unified Framework for Multiple Downstream Tasks
Nov 11, 2025



In recent years, the development of burst imaging technology has improved the capture and processing capabilities of visual data, enabling a wide range of applications. However, the redundancy in burst images leads to the increased storage and transmission demands, as well as reduced efficiency of downstream tasks. To address this, we propose a new task of Burst Image Quality Assessment (BuIQA), to evaluate the task-driven quality of each frame within a burst sequence, providing reasonable cues for burst image selection. Specifically, we establish the first benchmark dataset for BuIQA, consisting of $7,346$ burst sequences with $45,827$ images and $191,572$ annotated quality scores for multiple downstream scenarios. Inspired by the data analysis, a unified BuIQA framework is proposed to achieve an efficient adaption for BuIQA under diverse downstream scenarios. Specifically, a task-driven prompt generation network is developed with heterogeneous knowledge distillation, to learn the priors of the downstream task. Then, the task-aware quality assessment network is introduced to assess the burst image quality based on the task prompt. Extensive experiments across 10 downstream scenarios demonstrate the impressive BuIQA performance of the proposed approach, outperforming the state-of-the-art. Furthermore, it can achieve $0.33$ dB PSNR improvement in the downstream tasks of denoising and super-resolution, by applying our approach to select the high-quality burst frames.
Mitigating Hallucinations via Inter-Layer Consistency Aggregation in Large Vision-Language Models
May 18, 2025Despite the impressive capabilities of Large Vision-Language Models (LVLMs), they remain susceptible to hallucinations-generating content that is inconsistent with the input image. Existing training-free hallucination mitigation methods often suffer from unstable performance and high sensitivity to hyperparameter settings, limiting their practicality and broader adoption. In this paper, we propose a novel decoding mechanism, Decoding with Inter-layer Consistency via Layer Aggregation (DCLA), which requires no retraining, fine-tuning, or access to external knowledge bases. Specifically, our approach constructs a dynamic semantic reference by aggregating representations from previous layers, and corrects semantically deviated layers to enforce inter-layer consistency. The method allows DCLA to robustly mitigate hallucinations across multiple LVLMs. Experiments on hallucination benchmarks such as MME and POPE demonstrate that DCLA effectively reduces hallucinations while enhancing the reliability and performance of LVLMs.
STAR: Stage-Wise Attention-Guided Token Reduction for Efficient Large Vision-Language Models Inference
May 18, 2025Although large vision-language models (LVLMs) leverage rich visual token representations to achieve strong performance on multimodal tasks, these tokens also introduce significant computational overhead during inference. Existing training-free token pruning methods typically adopt a single-stage strategy, focusing either on visual self-attention or visual-textual cross-attention. However, such localized perspectives often overlook the broader information flow across the model, leading to substantial performance degradation, especially under high pruning ratios. In this work, we propose STAR (Stage-wise Attention-guided token Reduction), a training-free, plug-and-play framework that approaches token pruning from a global perspective. Instead of pruning at a single point, STAR performs attention-guided reduction in two complementary stages: an early-stage pruning based on visual self-attention to remove redundant low-level features, and a later-stage pruning guided by cross-modal attention to discard task-irrelevant tokens. This holistic approach allows STAR to significantly reduce computational cost while better preserving task-critical information. Extensive experiments across multiple LVLM architectures and benchmarks show that STAR achieves strong acceleration while maintaining comparable, and in some cases even improved performance.
Uncertainty Guided Adaptive Warping for Robust and Efficient Stereo Matching
Jul 26, 2023Correlation based stereo matching has achieved outstanding performance, which pursues cost volume between two feature maps. Unfortunately, current methods with a fixed model do not work uniformly well across various datasets, greatly limiting their real-world applicability. To tackle this issue, this paper proposes a new perspective to dynamically calculate correlation for robust stereo matching. A novel Uncertainty Guided Adaptive Correlation (UGAC) module is introduced to robustly adapt the same model for different scenarios. Specifically, a variance-based uncertainty estimation is employed to adaptively adjust the sampling area during warping operation. Additionally, we improve the traditional non-parametric warping with learnable parameters, such that the position-specific weights can be learned. We show that by empowering the recurrent network with the UGAC module, stereo matching can be exploited more robustly and effectively. Extensive experiments demonstrate that our method achieves state-of-the-art performance over the ETH3D, KITTI, and Middlebury datasets when employing the same fixed model over these datasets without any retraining procedure. To target real-time applications, we further design a lightweight model based on UGAC, which also outperforms other methods over KITTI benchmarks with only 0.6 M parameters.
DAQE: Enhancing the Quality of Compressed Images by Finding the Secret of Defocus
Nov 20, 2022



Image defocus is inherent in the physics of image formation caused by the optical aberration of lenses, providing plentiful information on image quality. Unfortunately, the existing quality enhancement approaches for compressed images neglect the inherent characteristic of defocus, resulting in inferior performance. This paper finds that in compressed images, the significantly defocused regions are with better compression quality and two regions with different defocus values possess diverse texture patterns. These findings motivate our defocus-aware quality enhancement (DAQE) approach. Specifically, we propose a novel dynamic region-based deep learning architecture of the DAQE approach, which considers the region-wise defocus difference of compressed images in two aspects. (1) The DAQE approach employs fewer computational resources to enhance the quality of significantly defocused regions, while more resources on enhancing the quality of other regions; (2) The DAQE approach learns to separately enhance diverse texture patterns for the regions with different defocus values, such that texture-wise one-on-one enhancement can be achieved. Extensive experiments validate the superiority of our DAQE approach in terms of quality enhancement and resource-saving, compared with other state-of-the-art approaches.
Blind VQA on 360° Video via Progressively Learning from Pixels, Frames and Video
Nov 18, 2021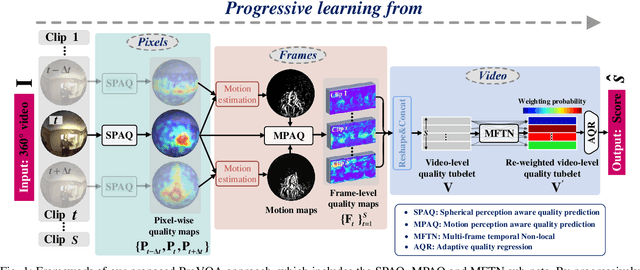
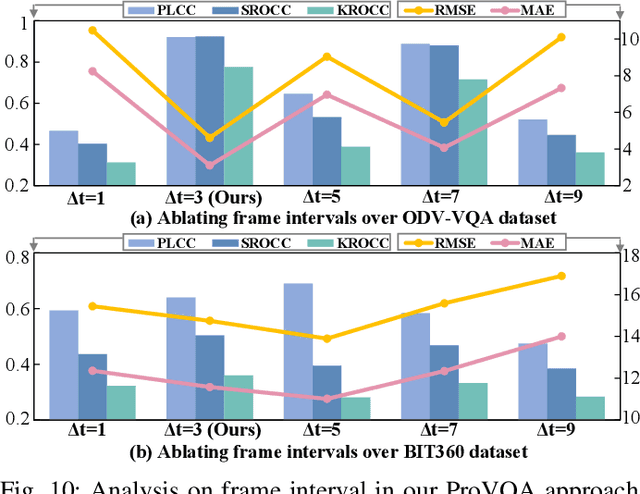
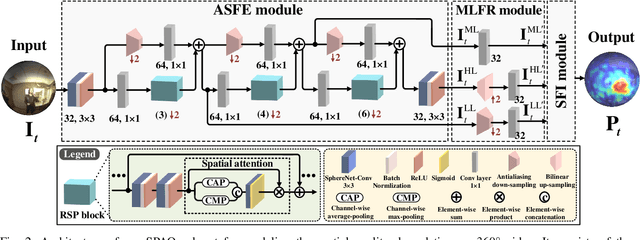
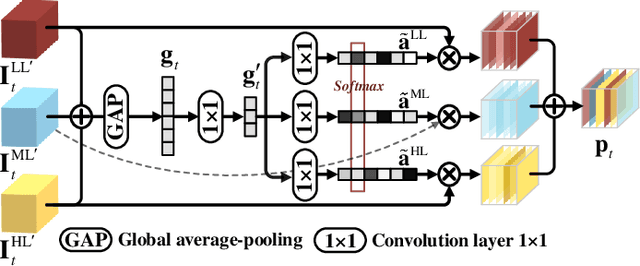
Blind visual quality assessment (BVQA) on 360{\textdegree} video plays a key role in optimizing immersive multimedia systems. When assessing the quality of 360{\textdegree} video, human tends to perceive its quality degradation from the viewport-based spatial distortion of each spherical frame to motion artifact across adjacent frames, ending with the video-level quality score, i.e., a progressive quality assessment paradigm. However, the existing BVQA approaches for 360{\textdegree} video neglect this paradigm. In this paper, we take into account the progressive paradigm of human perception towards spherical video quality, and thus propose a novel BVQA approach (namely ProVQA) for 360{\textdegree} video via progressively learning from pixels, frames and video. Corresponding to the progressive learning of pixels, frames and video, three sub-nets are designed in our ProVQA approach, i.e., the spherical perception aware quality prediction (SPAQ), motion perception aware quality prediction (MPAQ) and multi-frame temporal non-local (MFTN) sub-nets. The SPAQ sub-net first models the spatial quality degradation based on spherical perception mechanism of human. Then, by exploiting motion cues across adjacent frames, the MPAQ sub-net properly incorporates motion contextual information for quality assessment on 360{\textdegree} video. Finally, the MFTN sub-net aggregates multi-frame quality degradation to yield the final quality score, via exploring long-term quality correlation from multiple frames. The experiments validate that our approach significantly advances the state-of-the-art BVQA performance on 360{\textdegree} video over two datasets, the code of which has been public in \url{https://github.com/yanglixiaoshen/ProVQA.}