 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelfi: Self Improving Reconstruction Engine via 3D Geometric Feature Alignment
Dec 21, 2025Novel View Synthesis (NVS) has traditionally relied on models with explicit 3D inductive biases combined with known camera parameters from Structure-from-Motion (SfM) beforehand. Recent vision foundation models like VGGT take an orthogonal approach -- 3D knowledge is gained implicitly through training data and loss objectives, enabling feed-forward prediction of both camera parameters and 3D representations directly from a set of uncalibrated images. While flexible, VGGT features lack explicit multi-view geometric consistency, and we find that improving such 3D feature consistency benefits both NVS and pose estimation tasks. We introduce Selfi, a self-improving 3D reconstruction pipeline via feature alignment, transforming a VGGT backbone into a high-fidelity 3D reconstruction engine by leveraging its own outputs as pseudo-ground-truth. Specifically, we train a lightweight feature adapter using a reprojection-based consistency loss, which distills VGGT outputs into a new geometrically-aligned feature space that captures spatial proximity in 3D. This enables state-of-the-art performance in both NVS and camera pose estimation, demonstrating that feature alignment is a highly beneficial step for downstream 3D reasoning.
Quark: Real-time, High-resolution, and General Neural View Synthesis
Nov 25, 2024We present a novel neural algorithm for performing high-quality, high-resolution, real-time novel view synthesis. From a sparse set of input RGB images or videos streams, our network both reconstructs the 3D scene and renders novel views at 1080p resolution at 30fps on an NVIDIA A100. Our feed-forward network generalizes across a wide variety of datasets and scenes and produces state-of-the-art quality for a real-time method. Our quality approaches, and in some cases surpasses, the quality of some of the top offline methods. In order to achieve these results we use a novel combination of several key concepts, and tie them together into a cohesive and effective algorithm. We build on previous works that represent the scene using semi-transparent layers and use an iterative learned render-and-refine approach to improve those layers. Instead of flat layers, our method reconstructs layered depth maps (LDMs) that efficiently represent scenes with complex depth and occlusions. The iterative update steps are embedded in a multi-scale, UNet-style architecture to perform as much compute as possible at reduced resolution. Within each update step, to better aggregate the information from multiple input views, we use a specialized Transformer-based network component. This allows the majority of the per-input image processing to be performed in the input image space, as opposed to layer space, further increasing efficiency. Finally, due to the real-time nature of our reconstruction and rendering, we dynamically create and discard the internal 3D geometry for each frame, generating the LDM for each view. Taken together, this produces a novel and effective algorithm for view synthesis. Through extensive evaluation, we demonstrate that we achieve state-of-the-art quality at real-time rates. Project page: https://quark-3d.github.io/
Text2Immersion: Generative Immersive Scene with 3D Gaussians
Dec 14, 2023

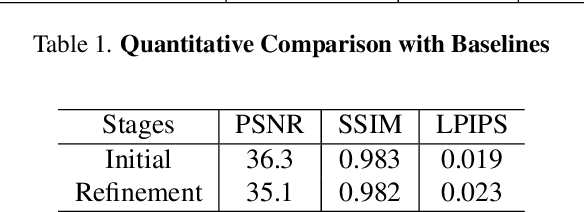

We introduce Text2Immersion, an elegant method for producing high-quality 3D immersive scenes from text prompts. Our proposed pipeline initiates by progressively generating a Gaussian cloud using pre-trained 2D diffusion and depth estimation models. This is followed by a refining stage on the Gaussian cloud, interpolating and refining it to enhance the details of the generated scene. Distinct from prevalent methods that focus on single object or indoor scenes, or employ zoom-out trajectories, our approach generates diverse scenes with various objects, even extending to the creation of imaginary scenes. Consequently, Text2Immersion can have wide-ranging implications for various applications such as virtual reality, game development, and automated content creation. Extensive evaluations demonstrate that our system surpasses other methods in rendering quality and diversity, further progressing towards text-driven 3D scene generation. We will make the source code publicly accessible at the project page.
Deep Learning Gauss-Manin Connections
Jul 27, 2020

The Gauss-Manin connection of a family of hypersurfaces governs the change of the period matrix along the family. This connection can be complicated even when the equations defining the family look simple. When this is the case, it is computationally expensive to compute the period matrices of varieties in the family via homotopy continuation. We train neural networks that can quickly and reliably guess the complexity of the Gauss-Manin connection of a pencil of hypersurfaces. As an application, we compute the periods of 96% of smooth quartic surfaces in projective 3-space whose defining equation is a sum of five monomials; from the periods of these quartic surfaces, we extract their Picard numbers and the endomorphism fields of their transcendental lattices.
A parameterless scale-space approach to find meaningful modes in histograms - Application to image and spectrum segmentation
Jan 13, 2014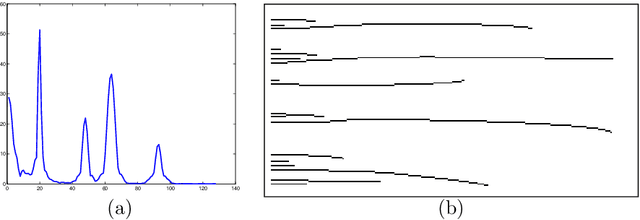
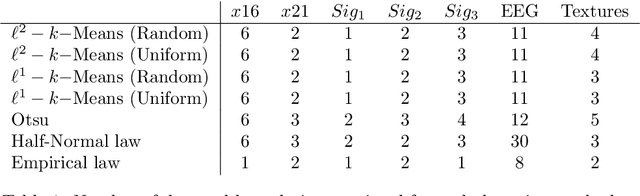
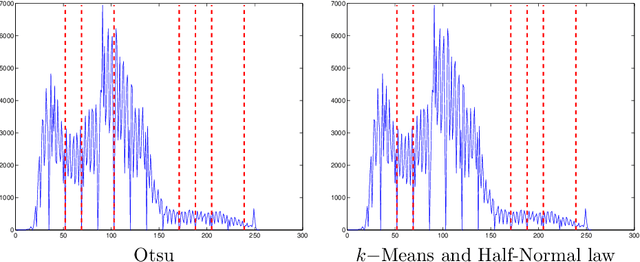
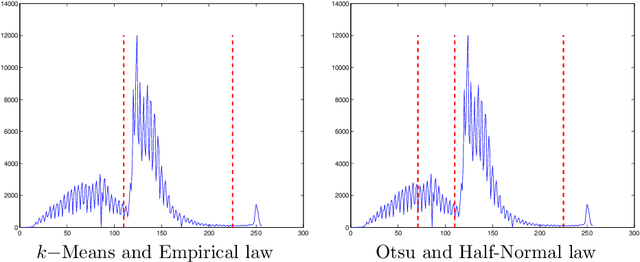
In this paper, we present an algorithm to automatically detect meaningful modes in a histogram. The proposed method is based on the behavior of local minima in a scale-space representation. We show that the detection of such meaningful modes is equivalent in a two classes clustering problem on the length of minima scale-space curves. The algorithm is easy to implement, fast, and does not require any parameters. We present several results on histogram and spectrum segmentation, grayscale image segmentation and color image reduction.