 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynaTok: Token-Based 4D Reconstruction from Partial Point Clouds
Jun 10, 2026We address 4D reconstruction from partial point cloud sequences, where depth-sensor observations are incomplete, unordered, and lack explicit temporal correspondences. This geometry-only setting is challenging due to missing observations and ambiguous dynamics. While recent progress has largely relied on image-based methods, existing point-based approaches typically focus on single objects, assume relatively complete inputs, or require explicit correspondences. To address these limitations, we propose DynaTok, a point-based framework for correspondence-free 4D reconstruction from partial point cloud sequences without images. DynaTok encodes frames into compact latent tokens, aggregates incomplete observations over time with a Transformer-based spatiotemporal encoder, and decouples geometry and motion through residual tokens in a unified model. A flow-matching decoder then reconstructs complete, temporally consistent 4D point-cloud sequences conditioned on the latent tokens. Experiments on object- and scene-level benchmarks demonstrate improved reconstruction quality and temporal coherence from partial point cloud observations. Project page: https://wrchen530.github.io/dynatok/.
OpenGaFF: Open-Vocabulary Gaussian Feature Field with Codebook Attention
May 07, 2026Understanding open-vocabulary 3D scenes with Gaussian-based representations remains challenging due to fragmented and spatially inconsistent semantic predictions across multi-view observations. In this paper, we present OpenGaFF, a novel framework for open-vocabulary 3D scene understanding built upon 3D Gaussian Splatting. At the core of our method is a Gaussian Feature Field that models semantics as a continuous function of Gaussian geometry and appearance. By explicitly conditioning semantic predictions on geometric structure, this formulation strengthens the coupling between geometry and semantics, leading to improved spatial coherence across similar structures in 3D space. To further enforce object-level semantic consistency, we introduce a structured codebook that serves as a set of shared semantic primitives. Furthermore, a codebook-guided attention mechanism is proposed to retrieve language features via similarity matching between query embeddings and learned codebook entries, enabling robust open-vocabulary reasoning while reducing intra-object feature variance. Extensive experiments on standard 2D and 3D open-vocabulary benchmarks demonstrate that our method consistently outperforms prior approaches, achieving improved segmentation quality, stronger 3D semantic consistency and a semantically interpretable codebook that provides insight into the learned representation.
GALA: Guided Attention with Language Alignment for Open Vocabulary Gaussian Splatting
Aug 21, 2025



3D scene reconstruction and understanding have gained increasing popularity, yet existing methods still struggle to capture fine-grained, language-aware 3D representations from 2D images. In this paper, we present GALA, a novel framework for open-vocabulary 3D scene understanding with 3D Gaussian Splatting (3DGS). GALA distills a scene-specific 3D instance feature field via self-supervised contrastive learning. To extend to generalized language feature fields, we introduce the core contribution of GALA, a cross-attention module with two learnable codebooks that encode view-independent semantic embeddings. This design not only ensures intra-instance feature similarity but also supports seamless 2D and 3D open-vocabulary queries. It reduces memory consumption by avoiding per-Gaussian high-dimensional feature learning. Extensive experiments on real-world datasets demonstrate GALA's remarkable open-vocabulary performance on both 2D and 3D.
Masks make discriminative models great again!
Jul 01, 2025We present Image2GS, a novel approach that addresses the challenging problem of reconstructing photorealistic 3D scenes from a single image by focusing specifically on the image-to-3D lifting component of the reconstruction process. By decoupling the lifting problem (converting an image to a 3D model representing what is visible) from the completion problem (hallucinating content not present in the input), we create a more deterministic task suitable for discriminative models. Our method employs visibility masks derived from optimized 3D Gaussian splats to exclude areas not visible from the source view during training. This masked training strategy significantly improves reconstruction quality in visible regions compared to strong baselines. Notably, despite being trained only on masked regions, Image2GS remains competitive with state-of-the-art discriminative models trained on full target images when evaluated on complete scenes. Our findings highlight the fundamental struggle discriminative models face when fitting unseen regions and demonstrate the advantages of addressing image-to-3D lifting as a distinct problem with specialized techniques.
LODGE: Level-of-Detail Large-Scale Gaussian Splatting with Efficient Rendering
May 29, 2025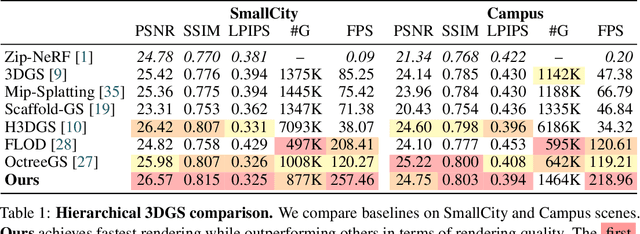
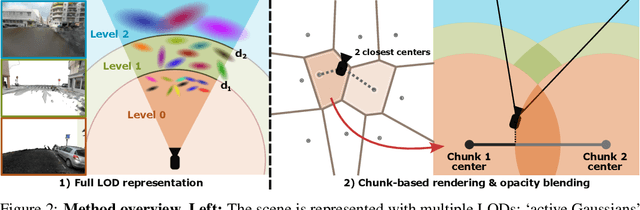
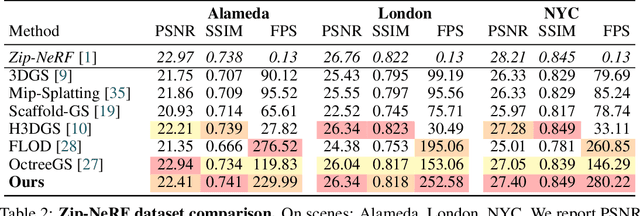
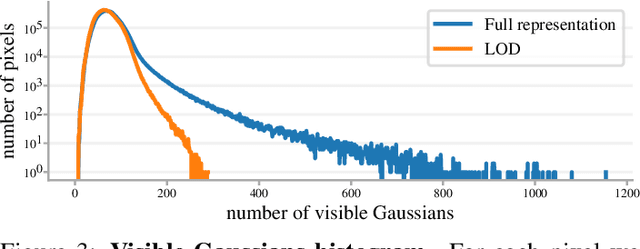
In this work, we present a novel level-of-detail (LOD) method for 3D Gaussian Splatting that enables real-time rendering of large-scale scenes on memory-constrained devices. Our approach introduces a hierarchical LOD representation that iteratively selects optimal subsets of Gaussians based on camera distance, thus largely reducing both rendering time and GPU memory usage. We construct each LOD level by applying a depth-aware 3D smoothing filter, followed by importance-based pruning and fine-tuning to maintain visual fidelity. To further reduce memory overhead, we partition the scene into spatial chunks and dynamically load only relevant Gaussians during rendering, employing an opacity-blending mechanism to avoid visual artifacts at chunk boundaries. Our method achieves state-of-the-art performance on both outdoor (Hierarchical 3DGS) and indoor (Zip-NeRF) datasets, delivering high-quality renderings with reduced latency and memory requirements.
SplatVoxel: History-Aware Novel View Streaming without Temporal Training
Mar 18, 2025We study the problem of novel view streaming from sparse-view videos, which aims to generate a continuous sequence of high-quality, temporally consistent novel views as new input frames arrive. However, existing novel view synthesis methods struggle with temporal coherence and visual fidelity, leading to flickering and inconsistency. To address these challenges, we introduce history-awareness, leveraging previous frames to reconstruct the scene and improve quality and stability. We propose a hybrid splat-voxel feed-forward scene reconstruction approach that combines Gaussian Splatting to propagate information over time, with a hierarchical voxel grid for temporal fusion. Gaussian primitives are efficiently warped over time using a motion graph that extends 2D tracking models to 3D motion, while a sparse voxel transformer integrates new temporal observations in an error-aware manner. Crucially, our method does not require training on multi-view video datasets, which are currently limited in size and diversity, and can be directly applied to sparse-view video streams in a history-aware manner at inference time. Our approach achieves state-of-the-art performance in both static and streaming scene reconstruction, effectively reducing temporal artifacts and visual artifacts while running at interactive rates (15 fps with 350ms delay) on a single H100 GPU. Project Page: https://19reborn.github.io/SplatVoxel/
SuperGSeg: Open-Vocabulary 3D Segmentation with Structured Super-Gaussians
Dec 13, 2024



3D Gaussian Splatting has recently gained traction for its efficient training and real-time rendering. While the vanilla Gaussian Splatting representation is mainly designed for view synthesis, more recent works investigated how to extend it with scene understanding and language features. However, existing methods lack a detailed comprehension of scenes, limiting their ability to segment and interpret complex structures. To this end, We introduce SuperGSeg, a novel approach that fosters cohesive, context-aware scene representation by disentangling segmentation and language field distillation. SuperGSeg first employs neural Gaussians to learn instance and hierarchical segmentation features from multi-view images with the aid of off-the-shelf 2D masks. These features are then leveraged to create a sparse set of what we call Super-Gaussians. Super-Gaussians facilitate the distillation of 2D language features into 3D space. Through Super-Gaussians, our method enables high-dimensional language feature rendering without extreme increases in GPU memory. Extensive experiments demonstrate that SuperGSeg outperforms prior works on both open-vocabulary object localization and semantic segmentation tasks.
Gaussians-to-Life: Text-Driven Animation of 3D Gaussian Splatting Scenes
Nov 28, 2024



State-of-the-art novel view synthesis methods achieve impressive results for multi-view captures of static 3D scenes. However, the reconstructed scenes still lack "liveliness," a key component for creating engaging 3D experiences. Recently, novel video diffusion models generate realistic videos with complex motion and enable animations of 2D images, however they cannot naively be used to animate 3D scenes as they lack multi-view consistency. To breathe life into the static world, we propose Gaussians2Life, a method for animating parts of high-quality 3D scenes in a Gaussian Splatting representation. Our key idea is to leverage powerful video diffusion models as the generative component of our model and to combine these with a robust technique to lift 2D videos into meaningful 3D motion. We find that, in contrast to prior work, this enables realistic animations of complex, pre-existing 3D scenes and further enables the animation of a large variety of object classes, while related work is mostly focused on prior-based character animation, or single 3D objects. Our model enables the creation of consistent, immersive 3D experiences for arbitrary scenes.
G2SDF: Surface Reconstruction from Explicit Gaussians with Implicit SDFs
Nov 25, 2024



State-of-the-art novel view synthesis methods such as 3D Gaussian Splatting (3DGS) achieve remarkable visual quality. While 3DGS and its variants can be rendered efficiently using rasterization, many tasks require access to the underlying 3D surface, which remains challenging to extract due to the sparse and explicit nature of this representation. In this paper, we introduce G2SDF, a novel approach that addresses this limitation by integrating a neural implicit Signed Distance Field (SDF) into the Gaussian Splatting framework. Our method links the opacity values of Gaussians with their distances to the surface, ensuring a closer alignment of Gaussians with the scene surface. To extend this approach to unbounded scenes at varying scales, we propose a normalization function that maps any range to a fixed interval. To further enhance reconstruction quality, we leverage an off-the-shelf depth estimator as pseudo ground truth during Gaussian Splatting optimization. By establishing a differentiable connection between the explicit Gaussians and the implicit SDF, our approach enables high-quality surface reconstruction and rendering. Experimental results on several real-world datasets demonstrate that G2SDF achieves superior reconstruction quality than prior works while maintaining the efficiency of 3DGS.
Evolutive Rendering Models
May 27, 2024



The landscape of computer graphics has undergone significant transformations with the recent advances of differentiable rendering models. These rendering models often rely on heuristic designs that may not fully align with the final rendering objectives. We address this gap by pioneering \textit{evolutive rendering models}, a methodology where rendering models possess the ability to evolve and adapt dynamically throughout the rendering process. In particular, we present a comprehensive learning framework that enables the optimization of three principal rendering elements, including the gauge transformations, the ray sampling mechanisms, and the primitive organization. Central to this framework is the development of differentiable versions of these rendering elements, allowing for effective gradient backpropagation from the final rendering objectives. A detailed analysis of gradient characteristics is performed to facilitate a stable and goal-oriented elements evolution. Our extensive experiments demonstrate the large potential of evolutive rendering models for enhancing the rendering performance across various domains, including static and dynamic scene representations, generative modeling, and texture mapping.