 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLODGE: Level-of-Detail Large-Scale Gaussian Splatting with Efficient Rendering
May 29, 2025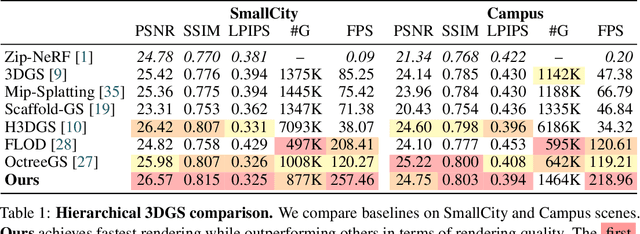
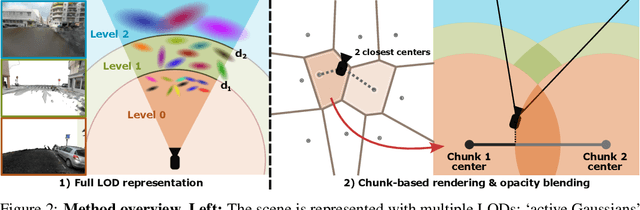
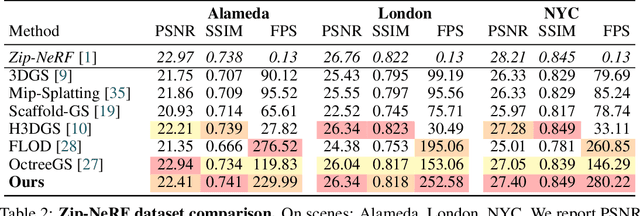
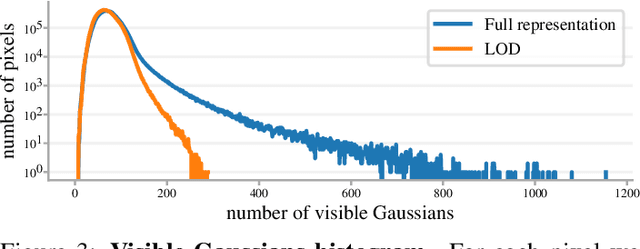
In this work, we present a novel level-of-detail (LOD) method for 3D Gaussian Splatting that enables real-time rendering of large-scale scenes on memory-constrained devices. Our approach introduces a hierarchical LOD representation that iteratively selects optimal subsets of Gaussians based on camera distance, thus largely reducing both rendering time and GPU memory usage. We construct each LOD level by applying a depth-aware 3D smoothing filter, followed by importance-based pruning and fine-tuning to maintain visual fidelity. To further reduce memory overhead, we partition the scene into spatial chunks and dynamically load only relevant Gaussians during rendering, employing an opacity-blending mechanism to avoid visual artifacts at chunk boundaries. Our method achieves state-of-the-art performance on both outdoor (Hierarchical 3DGS) and indoor (Zip-NeRF) datasets, delivering high-quality renderings with reduced latency and memory requirements.
Gaussian Garments: Reconstructing Simulation-Ready Clothing with Photorealistic Appearance from Multi-View Video
Sep 12, 2024We introduce Gaussian Garments, a novel approach for reconstructing realistic simulation-ready garment assets from multi-view videos. Our method represents garments with a combination of a 3D mesh and a Gaussian texture that encodes both the color and high-frequency surface details. This representation enables accurate registration of garment geometries to multi-view videos and helps disentangle albedo textures from lighting effects. Furthermore, we demonstrate how a pre-trained graph neural network (GNN) can be fine-tuned to replicate the real behavior of each garment. The reconstructed Gaussian Garments can be automatically combined into multi-garment outfits and animated with the fine-tuned GNN.
TextMesh: Generation of Realistic 3D Meshes From Text Prompts
Apr 24, 2023



The ability to generate highly realistic 2D images from mere text prompts has recently made huge progress in terms of speed and quality, thanks to the advent of image diffusion models. Naturally, the question arises if this can be also achieved in the generation of 3D content from such text prompts. To this end, a new line of methods recently emerged trying to harness diffusion models, trained on 2D images, for supervision of 3D model generation using view dependent prompts. While achieving impressive results, these methods, however, have two major drawbacks. First, rather than commonly used 3D meshes, they instead generate neural radiance fields (NeRFs), making them impractical for most real applications. Second, these approaches tend to produce over-saturated models, giving the output a cartoonish looking effect. Therefore, in this work we propose a novel method for generation of highly realistic-looking 3D meshes. To this end, we extend NeRF to employ an SDF backbone, leading to improved 3D mesh extraction. In addition, we propose a novel way to finetune the mesh texture, removing the effect of high saturation and improving the details of the output 3D mesh.