 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFLAT: Feedforward Latent Triangle Splatting for Geometrically Accurate Scene Generation
Jun 23, 2026Generating explorable 3D scenes from a single image requires strong generative priors and accurate geometric representations suitable for downstream use. Current video diffusion models offer high-quality generation and implicitly encode multi-view geometric structure in latent space. However, existing feedforward latent scene decoders typically output volumetric 3D Gaussians that lack a well-defined surface, limiting their use in simulation or standard graphics pipelines. This motivates decoding surface-aligned primitives that are not only renderable but also closer to explicit geometric assets. We ask whether compressed video diffusion latents can be mapped directly to explicit surface primitives in a single pass. To this end, we introduce FLAT and, for the first time, show that triangle splats can be decoded directly from video diffusion latents. Compared with decoding 3D Gaussians, predicting flat primitives is notoriously more challenging due to high sensitivity to primitive orientations, oftentimes leading to poor gradient flow. FLAT solves with two key ingredients: a ray-centered rotation parameterization for triangle regression and a novel product window function that improves gradient flow during differentiable triangle rendering. On standard benchmarks, FLAT achieves significantly better geometric accuracy while maintaining competitive visual quality compared to state-of-the-art feedforward baselines. We further show that a lightweight test-time refinement step converts the predicted triangle soup into a fully opaque, game-engine-ready representation that supports real-time rendering. By evaluating 3DGS, 2DGS, and triangle splatting variants under an identical training setup, we provide the first systematic analysis of representation tradeoffs in feedforward scene generation. The project page is available at https://flat-splat.github.io
Stepper: Stepwise Immersive Scene Generation with Multiview Panoramas
Mar 30, 2026The synthesis of immersive 3D scenes from text is rapidly maturing, driven by novel video generative models and feed-forward 3D reconstruction, with vast potential in AR/VR and world modeling. While panoramic images have proven effective for scene initialization, existing approaches suffer from a trade-off between visual fidelity and explorability: autoregressive expansion suffers from context drift, while panoramic video generation is limited to low resolution. We present Stepper, a unified framework for text-driven immersive 3D scene synthesis that circumvents these limitations via stepwise panoramic scene expansion. Stepper leverages a novel multi-view 360° diffusion model that enables consistent, high-resolution expansion, coupled with a geometry reconstruction pipeline that enforces geometric coherence. Trained on a new large-scale, multi-view panorama dataset, Stepper achieves state-of-the-art fidelity and structural consistency, outperforming prior approaches, thereby setting a new standard for immersive scene generation.
Epipolar Geometry Improves Video Generation Models
Oct 24, 2025Video generation models have progressed tremendously through large latent diffusion transformers trained with rectified flow techniques. Yet these models still struggle with geometric inconsistencies, unstable motion, and visual artifacts that break the illusion of realistic 3D scenes. 3D-consistent video generation could significantly impact numerous downstream applications in generation and reconstruction tasks. We explore how epipolar geometry constraints improve modern video diffusion models. Despite massive training data, these models fail to capture fundamental geometric principles underlying visual content. We align diffusion models using pairwise epipolar geometry constraints via preference-based optimization, directly addressing unstable camera trajectories and geometric artifacts through mathematically principled geometric enforcement. Our approach efficiently enforces geometric principles without requiring end-to-end differentiability. Evaluation demonstrates that classical geometric constraints provide more stable optimization signals than modern learned metrics, which produce noisy targets that compromise alignment quality. Training on static scenes with dynamic cameras ensures high-quality measurements while the model generalizes effectively to diverse dynamic content. By bridging data-driven deep learning with classical geometric computer vision, we present a practical method for generating spatially consistent videos without compromising visual quality.
LODGE: Level-of-Detail Large-Scale Gaussian Splatting with Efficient Rendering
May 29, 2025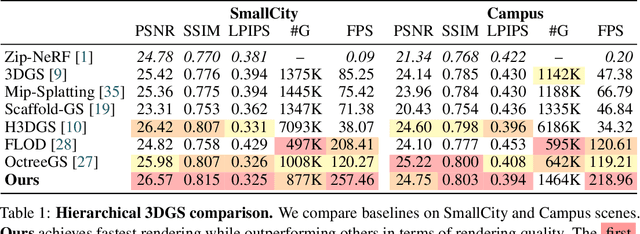
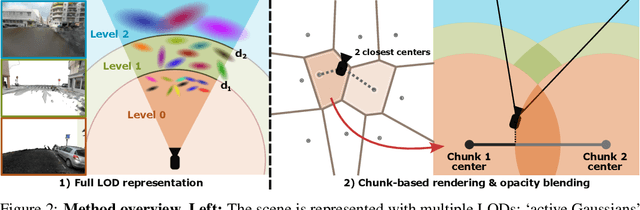
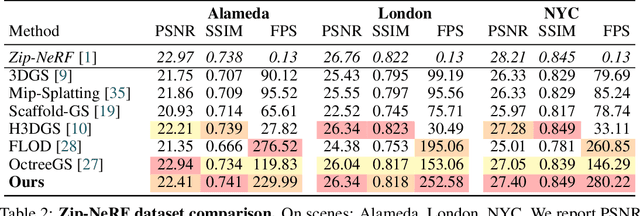
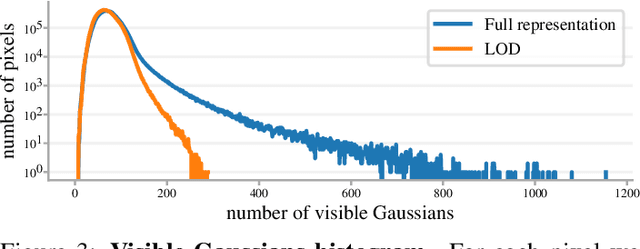
In this work, we present a novel level-of-detail (LOD) method for 3D Gaussian Splatting that enables real-time rendering of large-scale scenes on memory-constrained devices. Our approach introduces a hierarchical LOD representation that iteratively selects optimal subsets of Gaussians based on camera distance, thus largely reducing both rendering time and GPU memory usage. We construct each LOD level by applying a depth-aware 3D smoothing filter, followed by importance-based pruning and fine-tuning to maintain visual fidelity. To further reduce memory overhead, we partition the scene into spatial chunks and dynamically load only relevant Gaussians during rendering, employing an opacity-blending mechanism to avoid visual artifacts at chunk boundaries. Our method achieves state-of-the-art performance on both outdoor (Hierarchical 3DGS) and indoor (Zip-NeRF) datasets, delivering high-quality renderings with reduced latency and memory requirements.
CubeDiff: Repurposing Diffusion-Based Image Models for Panorama Generation
Jan 28, 2025We introduce a novel method for generating 360{\deg} panoramas from text prompts or images. Our approach leverages recent advances in 3D generation by employing multi-view diffusion models to jointly synthesize the six faces of a cubemap. Unlike previous methods that rely on processing equirectangular projections or autoregressive generation, our method treats each face as a standard perspective image, simplifying the generation process and enabling the use of existing multi-view diffusion models. We demonstrate that these models can be adapted to produce high-quality cubemaps without requiring correspondence-aware attention layers. Our model allows for fine-grained text control, generates high resolution panorama images and generalizes well beyond its training set, whilst achieving state-of-the-art results, both qualitatively and quantitatively. Project page: https://cubediff.github.io/
Mixed Diffusion for 3D Indoor Scene Synthesis
May 31, 2024



Realistic conditional 3D scene synthesis significantly enhances and accelerates the creation of virtual environments, which can also provide extensive training data for computer vision and robotics research among other applications. Diffusion models have shown great performance in related applications, e.g., making precise arrangements of unordered sets. However, these models have not been fully explored in floor-conditioned scene synthesis problems. We present MiDiffusion, a novel mixed discrete-continuous diffusion model architecture, designed to synthesize plausible 3D indoor scenes from given room types, floor plans, and potentially pre-existing objects. We represent a scene layout by a 2D floor plan and a set of objects, each defined by its category, location, size, and orientation. Our approach uniquely implements structured corruption across the mixed discrete semantic and continuous geometric domains, resulting in a better conditioned problem for the reverse denoising step. We evaluate our approach on the 3D-FRONT dataset. Our experimental results demonstrate that MiDiffusion substantially outperforms state-of-the-art autoregressive and diffusion models in floor-conditioned 3D scene synthesis. In addition, our models can handle partial object constraints via a corruption-and-masking strategy without task specific training. We show MiDiffusion maintains clear advantages over existing approaches in scene completion and furniture arrangement experiments.
OpenNeRF: Open Set 3D Neural Scene Segmentation with Pixel-Wise Features and Rendered Novel Views
Apr 04, 2024



Large visual-language models (VLMs), like CLIP, enable open-set image segmentation to segment arbitrary concepts from an image in a zero-shot manner. This goes beyond the traditional closed-set assumption, i.e., where models can only segment classes from a pre-defined training set. More recently, first works on open-set segmentation in 3D scenes have appeared in the literature. These methods are heavily influenced by closed-set 3D convolutional approaches that process point clouds or polygon meshes. However, these 3D scene representations do not align well with the image-based nature of the visual-language models. Indeed, point cloud and 3D meshes typically have a lower resolution than images and the reconstructed 3D scene geometry might not project well to the underlying 2D image sequences used to compute pixel-aligned CLIP features. To address these challenges, we propose OpenNeRF which naturally operates on posed images and directly encodes the VLM features within the NeRF. This is similar in spirit to LERF, however our work shows that using pixel-wise VLM features (instead of global CLIP features) results in an overall less complex architecture without the need for additional DINO regularization. Our OpenNeRF further leverages NeRF's ability to render novel views and extract open-set VLM features from areas that are not well observed in the initial posed images. For 3D point cloud segmentation on the Replica dataset, OpenNeRF outperforms recent open-vocabulary methods such as LERF and OpenScene by at least +4.9 mIoU.
* ICLR 2024, Project page: https://opennerf.github.io
KP-RED: Exploiting Semantic Keypoints for Joint 3D Shape Retrieval and Deformation
Mar 20, 2024



In this paper, we present KP-RED, a unified KeyPoint-driven REtrieval and Deformation framework that takes object scans as input and jointly retrieves and deforms the most geometrically similar CAD models from a pre-processed database to tightly match the target. Unlike existing dense matching based methods that typically struggle with noisy partial scans, we propose to leverage category-consistent sparse keypoints to naturally handle both full and partial object scans. Specifically, we first employ a lightweight retrieval module to establish a keypoint-based embedding space, measuring the similarity among objects by dynamically aggregating deformation-aware local-global features around extracted keypoints. Objects that are close in the embedding space are considered similar in geometry. Then we introduce the neural cage-based deformation module that estimates the influence vector of each keypoint upon cage vertices inside its local support region to control the deformation of the retrieved shape. Extensive experiments on the synthetic dataset PartNet and the real-world dataset Scan2CAD demonstrate that KP-RED surpasses existing state-of-the-art approaches by a large margin. Codes and trained models will be released in https://github.com/lolrudy/KP-RED.
RadSplat: Radiance Field-Informed Gaussian Splatting for Robust Real-Time Rendering with 900+ FPS
Mar 20, 2024



Recent advances in view synthesis and real-time rendering have achieved photorealistic quality at impressive rendering speeds. While Radiance Field-based methods achieve state-of-the-art quality in challenging scenarios such as in-the-wild captures and large-scale scenes, they often suffer from excessively high compute requirements linked to volumetric rendering. Gaussian Splatting-based methods, on the other hand, rely on rasterization and naturally achieve real-time rendering but suffer from brittle optimization heuristics that underperform on more challenging scenes. In this work, we present RadSplat, a lightweight method for robust real-time rendering of complex scenes. Our main contributions are threefold. First, we use radiance fields as a prior and supervision signal for optimizing point-based scene representations, leading to improved quality and more robust optimization. Next, we develop a novel pruning technique reducing the overall point count while maintaining high quality, leading to smaller and more compact scene representations with faster inference speeds. Finally, we propose a novel test-time filtering approach that further accelerates rendering and allows to scale to larger, house-sized scenes. We find that our method enables state-of-the-art synthesis of complex captures at 900+ FPS.
Denoising Diffusion via Image-Based Rendering
Feb 05, 2024



Generating 3D scenes is a challenging open problem, which requires synthesizing plausible content that is fully consistent in 3D space. While recent methods such as neural radiance fields excel at view synthesis and 3D reconstruction, they cannot synthesize plausible details in unobserved regions since they lack a generative capability. Conversely, existing generative methods are typically not capable of reconstructing detailed, large-scale scenes in the wild, as they use limited-capacity 3D scene representations, require aligned camera poses, or rely on additional regularizers. In this work, we introduce the first diffusion model able to perform fast, detailed reconstruction and generation of real-world 3D scenes. To achieve this, we make three contributions. First, we introduce a new neural scene representation, IB-planes, that can efficiently and accurately represent large 3D scenes, dynamically allocating more capacity as needed to capture details visible in each image. Second, we propose a denoising-diffusion framework to learn a prior over this novel 3D scene representation, using only 2D images without the need for any additional supervision signal such as masks or depths. This supports 3D reconstruction and generation in a unified architecture. Third, we develop a principled approach to avoid trivial 3D solutions when integrating the image-based rendering with the diffusion model, by dropping out representations of some images. We evaluate the model on several challenging datasets of real and synthetic images, and demonstrate superior results on generation, novel view synthesis and 3D reconstruction.