 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisCa: Accelerating Video Diffusion Transformers with Distillation-Compatible Learnable Feature Caching
Feb 05, 2026While diffusion models have achieved great success in the field of video generation, this progress is accompanied by a rapidly escalating computational burden. Among the existing acceleration methods, Feature Caching is popular due to its training-free property and considerable speedup performance, but it inevitably faces semantic and detail drop with further compression. Another widely adopted method, training-aware step-distillation, though successful in image generation, also faces drastic degradation in video generation with a few steps. Furthermore, the quality loss becomes more severe when simply applying training-free feature caching to the step-distilled models, due to the sparser sampling steps. This paper novelly introduces a distillation-compatible learnable feature caching mechanism for the first time. We employ a lightweight learnable neural predictor instead of traditional training-free heuristics for diffusion models, enabling a more accurate capture of the high-dimensional feature evolution process. Furthermore, we explore the challenges of highly compressed distillation on large-scale video models and propose a conservative Restricted MeanFlow approach to achieve more stable and lossless distillation. By undertaking these initiatives, we further push the acceleration boundaries to $11.8\times$ while preserving generation quality. Extensive experiments demonstrate the effectiveness of our method. The code is in the supplementary materials and will be publicly available.
High-Layer Attention Pruning with Rescaling
Jul 02, 2025Pruning is a highly effective approach for compressing large language models (LLMs), significantly reducing inference latency. However, conventional training-free structured pruning methods often employ a heuristic metric that indiscriminately removes some attention heads across all pruning layers, without considering their positions within the network architecture. In this work, we propose a novel pruning algorithm that strategically prunes attention heads in the model's higher layers. Since the removal of attention heads can alter the magnitude of token representations, we introduce an adaptive rescaling parameter that calibrates the representation scale post-pruning to counteract this effect. We conduct comprehensive experiments on a wide range of LLMs, including LLaMA3.1-8B, Mistral-7B-v0.3, Qwen2-7B, and Gemma2-9B. Our evaluation includes both generation and discriminative tasks across 27 datasets. The results consistently demonstrate that our method outperforms existing structured pruning methods. This improvement is particularly notable in generation tasks, where our approach significantly outperforms existing baselines.
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Dec 03, 2024



Recent advancements in video generation have significantly impacted daily life for both individuals and industries. However, the leading video generation models remain closed-source, resulting in a notable performance gap between industry capabilities and those available to the public. In this report, we introduce HunyuanVideo, an innovative open-source video foundation model that demonstrates performance in video generation comparable to, or even surpassing, that of leading closed-source models. HunyuanVideo encompasses a comprehensive framework that integrates several key elements, including data curation, advanced architectural design, progressive model scaling and training, and an efficient infrastructure tailored for large-scale model training and inference. As a result, we successfully trained a video generative model with over 13 billion parameters, making it the largest among all open-source models. We conducted extensive experiments and implemented a series of targeted designs to ensure high visual quality, motion dynamics, text-video alignment, and advanced filming techniques. According to evaluations by professionals, HunyuanVideo outperforms previous state-of-the-art models, including Runway Gen-3, Luma 1.6, and three top-performing Chinese video generative models. By releasing the code for the foundation model and its applications, we aim to bridge the gap between closed-source and open-source communities. This initiative will empower individuals within the community to experiment with their ideas, fostering a more dynamic and vibrant video generation ecosystem. The code is publicly available at https://github.com/Tencent/HunyuanVideo.
SDDBench: A Benchmark for Synthesizable Drug Design
Nov 13, 2024



A significant challenge in wet lab experiments with current drug design generative models is the trade-off between pharmacological properties and synthesizability. Molecules predicted to have highly desirable properties are often difficult to synthesize, while those that are easily synthesizable tend to exhibit less favorable properties. As a result, evaluating the synthesizability of molecules in general drug design scenarios remains a significant challenge in the field of drug discovery. The commonly used synthetic accessibility (SA) score aims to evaluate the ease of synthesizing generated molecules, but it falls short of guaranteeing that synthetic routes can actually be found. Inspired by recent advances in top-down synthetic route generation, we propose a new, data-driven metric to evaluate molecule synthesizability. Our approach directly assesses the feasibility of synthetic routes for a given molecule through our proposed round-trip score. This novel metric leverages the synergistic duality between retrosynthetic planners and reaction predictors, both of which are trained on extensive reaction datasets. To demonstrate the efficacy of our method, we conduct a comprehensive evaluation of round-trip scores alongside search success rate across a range of representative molecule generative models. Code is available at https://github.com/SongtaoLiu0823/SDDBench.
Graph Adversarial Diffusion Convolution
Jun 04, 2024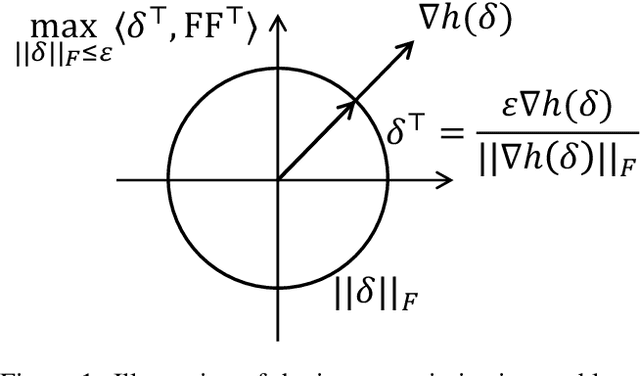
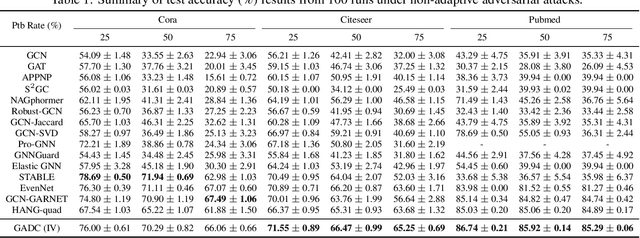
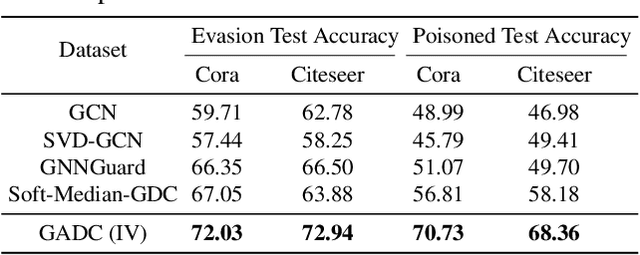
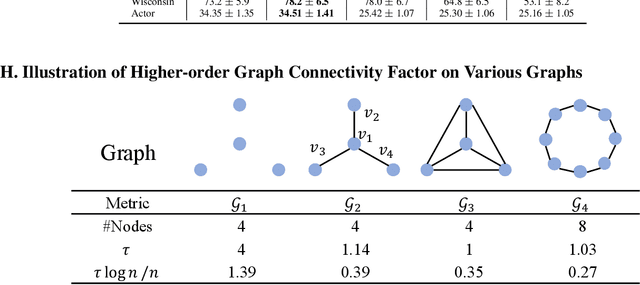
This paper introduces a min-max optimization formulation for the Graph Signal Denoising (GSD) problem. In this formulation, we first maximize the second term of GSD by introducing perturbations to the graph structure based on Laplacian distance and then minimize the overall loss of the GSD. By solving the min-max optimization problem, we derive a new variant of the Graph Diffusion Convolution (GDC) architecture, called Graph Adversarial Diffusion Convolution (GADC). GADC differs from GDC by incorporating an additional term that enhances robustness against adversarial attacks on the graph structure and noise in node features. Moreover, GADC improves the performance of GDC on heterophilic graphs. Extensive experiments demonstrate the effectiveness of GADC across various datasets. Code is available at https://github.com/SongtaoLiu0823/GADC.
Preference Optimization for Molecule Synthesis with Conditional Residual Energy-based Models
Jun 04, 2024



Molecule synthesis through machine learning is one of the fundamental problems in drug discovery. Current data-driven strategies employ one-step retrosynthesis models and search algorithms to predict synthetic routes in a top-bottom manner. Despite their effective performance, these strategies face limitations in the molecule synthetic route generation due to a greedy selection of the next molecule set without any lookahead. Furthermore, existing strategies cannot control the generation of synthetic routes based on possible criteria such as material costs, yields, and step count. In this work, we propose a general and principled framework via conditional residual energy-based models (EBMs), that focus on the quality of the entire synthetic route based on the specific criteria. By incorporating an additional energy-based function into our probabilistic model, our proposed algorithm can enhance the quality of the most probable synthetic routes (with higher probabilities) generated by various strategies in a plug-and-play fashion. Extensive experiments demonstrate that our framework can consistently boost performance across various strategies and outperforms previous state-of-the-art top-1 accuracy by a margin of 2.5%. Code is available at https://github.com/SongtaoLiu0823/CREBM.
Encoding Hierarchical Schema via Concept Flow for Multifaceted Ideology Detection
May 29, 2024



Multifaceted ideology detection (MID) aims to detect the ideological leanings of texts towards multiple facets. Previous studies on ideology detection mainly focus on one generic facet and ignore label semantics and explanatory descriptions of ideologies, which are a kind of instructive information and reveal the specific concepts of ideologies. In this paper, we develop a novel concept semantics-enhanced framework for the MID task. Specifically, we propose a bidirectional iterative concept flow (BICo) method to encode multifaceted ideologies. BICo enables the concepts to flow across levels of the schema tree and enriches concept representations with multi-granularity semantics. Furthermore, we explore concept attentive matching and concept-guided contrastive learning strategies to guide the model to capture ideology features with the learned concept semantics. Extensive experiments on the benchmark dataset show that our approach achieves state-of-the-art performance in MID, including in the cross-topic scenario.
Align-DETR: Improving DETR with Simple IoU-aware BCE loss
Apr 15, 2023



DETR has set up a simple end-to-end pipeline for object detection by formulating this task as a set prediction problem, showing promising potential. However, despite the significant progress in improving DETR, this paper identifies a problem of misalignment in the output distribution, which prevents the best-regressed samples from being assigned with high confidence, hindering the model's accuracy. We propose a metric, recall of best-regressed samples, to quantitively evaluate the misalignment problem. Observing its importance, we propose a novel Align-DETR that incorporates a localization precision-aware classification loss in optimization. The proposed loss, IA-BCE, guides the training of DETR to build a strong correlation between classification score and localization precision. We also adopt the mixed-matching strategy, to facilitate DETR-based detectors with faster training convergence while keeping an end-to-end scheme. Moreover, to overcome the dramatic decrease in sample quality induced by the sparsity of queries, we introduce a prime sample weighting mechanism to suppress the interference of unimportant samples. Extensive experiments are conducted with very competitive results reported. In particular, it delivers a 46 (+3.8)% AP on the DAB-DETR baseline with the ResNet-50 backbone and reaches a new SOTA performance of 50.2% AP in the 1x setting on the COCO validation set when employing the strong baseline DINO. Our code is available at https://github.com/FelixCaae/AlignDETR.
Dynamic Grained Encoder for Vision Transformers
Jan 10, 2023Transformers, the de-facto standard for language modeling, have been recently applied for vision tasks. This paper introduces sparse queries for vision transformers to exploit the intrinsic spatial redundancy of natural images and save computational costs. Specifically, we propose a Dynamic Grained Encoder for vision transformers, which can adaptively assign a suitable number of queries to each spatial region. Thus it achieves a fine-grained representation in discriminative regions while keeping high efficiency. Besides, the dynamic grained encoder is compatible with most vision transformer frameworks. Without bells and whistles, our encoder allows the state-of-the-art vision transformers to reduce computational complexity by 40%-60% while maintaining comparable performance on image classification. Extensive experiments on object detection and segmentation further demonstrate the generalizability of our approach. Code is available at https://github.com/StevenGrove/vtpack.
Generalizing Multiple Object Tracking to Unseen Domains by Introducing Natural Language Representation
Dec 03, 2022



Although existing multi-object tracking (MOT) algorithms have obtained competitive performance on various benchmarks, almost all of them train and validate models on the same domain. The domain generalization problem of MOT is hardly studied. To bridge this gap, we first draw the observation that the high-level information contained in natural language is domain invariant to different tracking domains. Based on this observation, we propose to introduce natural language representation into visual MOT models for boosting the domain generalization ability. However, it is infeasible to label every tracking target with a textual description. To tackle this problem, we design two modules, namely visual context prompting (VCP) and visual-language mixing (VLM). Specifically, VCP generates visual prompts based on the input frames. VLM joints the information in the generated visual prompts and the textual prompts from a pre-defined Trackbook to obtain instance-level pseudo textual description, which is domain invariant to different tracking scenes. Through training models on MOT17 and validating them on MOT20, we observe that the pseudo textual descriptions generated by our proposed modules improve the generalization performance of query-based trackers by large margins.