 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePET-DINO: Unifying Visual Cues into Grounding DINO with Prompt-Enriched Training
Apr 01, 2026Open-Set Object Detection (OSOD) enables recognition of novel categories beyond fixed classes but faces challenges in aligning text representations with complex visual concepts and the scarcity of image-text pairs for rare categories. This results in suboptimal performance in specialized domains or with complex objects. Recent visual-prompted methods partially address these issues but often involve complex multi-modal designs and multi-stage optimizations, prolonging the development cycle. Additionally, effective training strategies for data-driven OSOD models remain largely unexplored. To address these challenges, we propose PET-DINO, a universal detector supporting both text and visual prompts. Our Alignment-Friendly Visual Prompt Generation (AFVPG) module builds upon an advanced text-prompted detector, addressing the limitations of text representation guidance and reducing the development cycle. We introduce two prompt-enriched training strategies: Intra-Batch Parallel Prompting (IBP) at the iteration level and Dynamic Memory-Driven Prompting (DMD) at the overall training level. These strategies enable simultaneous modeling of multiple prompt routes, facilitating parallel alignment with diverse real-world usage scenarios. Comprehensive experiments demonstrate that PET-DINO exhibits competitive zero-shot object detection capabilities across various prompt-based detection protocols. These strengths can be attributed to inheritance-based philosophy and prompt-enriched training strategies, which play a critical role in building an effective generic object detector. Project page: https://fuweifuvtoo.github.io/pet-dino.
ORMOT: A Dataset and Framework for Omnidirectional Referring Multi-Object Tracking
Mar 05, 2026Multi-Object Tracking (MOT) is a fundamental task in computer vision, aiming to track targets across video frames. Existing MOT methods perform well in general visual scenes, but face significant challenges and limitations when extended to visual-language settings. To bridge this gap, the task of Referring Multi-Object Tracking (RMOT) has recently been proposed, which aims to track objects that correspond to language descriptions. However, current RMOT methods are primarily developed on datasets captured by conventional cameras, which suffer from limited field of view. This constraint often causes targets to move out of the frame, leading to fragmented tracking and loss of contextual information. In this work, we propose a novel task, called Omnidirectional Referring Multi-Object Tracking (ORMOT), which extends RMOT to omnidirectional imagery, aiming to overcome the field-of-view (FoV) limitation of conventional datasets and improve the model's ability to understand long-horizon language descriptions. To advance the ORMOT task, we construct ORSet, an Omnidirectional Referring Multi-Object Tracking dataset, which contains 27 diverse omnidirectional scenes, 848 language descriptions, and 3,401 annotated objects, providing rich visual, temporal, and language information. Furthermore, we propose ORTrack, a Large Vision-Language Model (LVLM)-driven framework tailored for Omnidirectional Referring Multi-Object Tracking. Extensive experiments on the ORSet dataset demonstrate the effectiveness of our ORTrack framework. The dataset and code will be open-sourced at https://github.com/chen-si-jia/ORMOT.
RT-RMOT: A Dataset and Framework for RGB-Thermal Referring Multi-Object Tracking
Feb 25, 2026Referring Multi-Object Tracking has attracted increasing attention due to its human-friendly interactive characteristics, yet it exhibits limitations in low-visibility conditions, such as nighttime, smoke, and other challenging scenarios. To overcome this limitation, we propose a new RGB-Thermal RMOT task, named RT-RMOT, which aims to fuse RGB appearance features with the illumination robustness of the thermal modality to enable all-day referring multi-object tracking. To promote research on RT-RMOT, we construct the first Referring Multi-Object Tracking dataset under RGB-Thermal modality, named RefRT. It contains 388 language descriptions, 1,250 tracked targets, and 166,147 Language-RGB-Thermal (L-RGB-T) triplets. Furthermore, we propose RTrack, a framework built upon a multimodal large language model (MLLM) that integrates RGB, thermal, and textual features. Since the initial framework still leaves room for improvement, we introduce a Group Sequence Policy Optimization (GSPO) strategy to further exploit the model's potential. To alleviate training instability during RL fine-tuning, we introduce a Clipped Advantage Scaling (CAS) strategy to suppress gradient explosion. In addition, we design Structured Output Reward and Comprehensive Detection Reward to balance exploration and exploitation, thereby improving the completeness and accuracy of target perception. Extensive experiments on the RefRT dataset demonstrate the effectiveness of the proposed RTrack framework.
VGGT-Motion: Motion-Aware Calibration-Free Monocular SLAM for Long-Range Consistency
Feb 05, 2026Despite recent progress in calibration-free monocular SLAM via 3D vision foundation models, scale drift remains severe on long sequences. Motion-agnostic partitioning breaks contextual coherence and causes zero-motion drift, while conventional geometric alignment is computationally expensive. To address these issues, we propose VGGT-Motion, a calibration-free SLAM system for efficient and robust global consistency over kilometer-scale trajectories. Specifically, we first propose a motion-aware submap construction mechanism that uses optical flow to guide adaptive partitioning, prune static redundancy, and encapsulate turns for stable local geometry. We then design an anchor-driven direct Sim(3) registration strategy. By exploiting context-balanced anchors, it achieves search-free, pixel-wise dense alignment and efficient loop closure without costly feature matching. Finally, a lightweight submap-level pose graph optimization enforces global consistency with linear complexity, enabling scalable long-range operation. Experiments show that VGGT-Motion markedly improves trajectory accuracy and efficiency, achieving state-of-the-art performance in zero-shot, long-range calibration-free monocular SLAM.
DRMOT: A Dataset and Framework for RGBD Referring Multi-Object Tracking
Feb 04, 2026Referring Multi-Object Tracking (RMOT) aims to track specific targets based on language descriptions and is vital for interactive AI systems such as robotics and autonomous driving. However, existing RMOT models rely solely on 2D RGB data, making it challenging to accurately detect and associate targets characterized by complex spatial semantics (e.g., ``the person closest to the camera'') and to maintain reliable identities under severe occlusion, due to the absence of explicit 3D spatial information. In this work, we propose a novel task, RGBD Referring Multi-Object Tracking (DRMOT), which explicitly requires models to fuse RGB, Depth (D), and Language (L) modalities to achieve 3D-aware tracking. To advance research on the DRMOT task, we construct a tailored RGBD referring multi-object tracking dataset, named DRSet, designed to evaluate models' spatial-semantic grounding and tracking capabilities. Specifically, DRSet contains RGB images and depth maps from 187 scenes, along with 240 language descriptions, among which 56 descriptions incorporate depth-related information. Furthermore, we propose DRTrack, a MLLM-guided depth-referring tracking framework. DRTrack performs depth-aware target grounding from joint RGB-D-L inputs and enforces robust trajectory association by incorporating depth cues. Extensive experiments on the DRSet dataset demonstrate the effectiveness of our framework.
ReaMOT: A Benchmark and Framework for Reasoning-based Multi-Object Tracking
May 26, 2025



Referring Multi-object tracking (RMOT) is an important research field in computer vision. Its task form is to guide the models to track the objects that conform to the language instruction. However, the RMOT task commonly requires clear language instructions, such methods often fail to work when complex language instructions with reasoning characteristics appear. In this work, we propose a new task, called Reasoning-based Multi-Object Tracking (ReaMOT). ReaMOT is a more challenging task that requires accurate reasoning about objects that match the language instruction with reasoning characteristic and tracking the objects' trajectories. To advance the ReaMOT task and evaluate the reasoning capabilities of tracking models, we construct ReaMOT Challenge, a reasoning-based multi-object tracking benchmark built upon 12 datasets. Specifically, it comprises 1,156 language instructions with reasoning characteristic, 423,359 image-language pairs, and 869 diverse scenes, which is divided into three levels of reasoning difficulty. In addition, we propose a set of evaluation metrics tailored for the ReaMOT task. Furthermore, we propose ReaTrack, a training-free framework for reasoning-based multi-object tracking based on large vision-language models (LVLM) and SAM2, as a baseline for the ReaMOT task. Extensive experiments on the ReaMOT Challenge benchmark demonstrate the effectiveness of our ReaTrack framework.
Perception-R1: Pioneering Perception Policy with Reinforcement Learning
Apr 10, 2025



Inspired by the success of DeepSeek-R1, we explore the potential of rule-based reinforcement learning (RL) in MLLM post-training for perception policy learning. While promising, our initial experiments reveal that incorporating a thinking process through RL does not consistently lead to performance gains across all visual perception tasks. This leads us to delve into the essential role of RL in the context of visual perception. In this work, we return to the fundamentals and explore the effects of RL on different perception tasks. We observe that the perceptual complexity is a major factor in determining the effectiveness of RL. We also observe that reward design plays a crucial role in further approching the upper limit of model perception. To leverage these findings, we propose Perception-R1, a scalable RL framework using GRPO during MLLM post-training. With a standard Qwen2.5-VL-3B-Instruct, Perception-R1 achieves +4.2% on RefCOCO+, +17.9% on PixMo-Count, +4.2% on PageOCR, and notably, 31.9% AP on COCO2017 val for the first time, establishing a strong baseline for perception policy learning.
OVTR: End-to-End Open-Vocabulary Multiple Object Tracking with Transformer
Mar 13, 2025



Open-vocabulary multiple object tracking aims to generalize trackers to unseen categories during training, enabling their application across a variety of real-world scenarios. However, the existing open-vocabulary tracker is constrained by its framework structure, isolated frame-level perception, and insufficient modal interactions, which hinder its performance in open-vocabulary classification and tracking. In this paper, we propose OVTR (End-to-End Open-Vocabulary Multiple Object Tracking with TRansformer), the first end-to-end open-vocabulary tracker that models motion, appearance, and category simultaneously. To achieve stable classification and continuous tracking, we design the CIP (Category Information Propagation) strategy, which establishes multiple high-level category information priors for subsequent frames. Additionally, we introduce a dual-branch structure for generalization capability and deep multimodal interaction, and incorporate protective strategies in the decoder to enhance performance. Experimental results show that our method surpasses previous trackers on the open-vocabulary MOT benchmark while also achieving faster inference speeds and significantly reducing preprocessing requirements. Moreover, the experiment transferring the model to another dataset demonstrates its strong adaptability. Models and code are released at https://github.com/jinyanglii/OVTR.
Unhackable Temporal Rewarding for Scalable Video MLLMs
Feb 17, 2025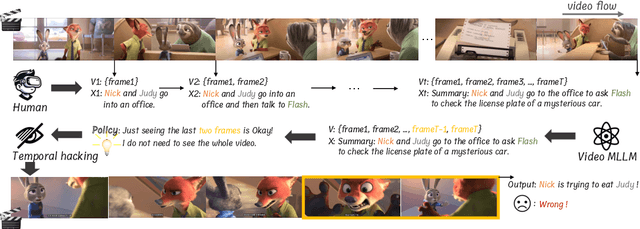
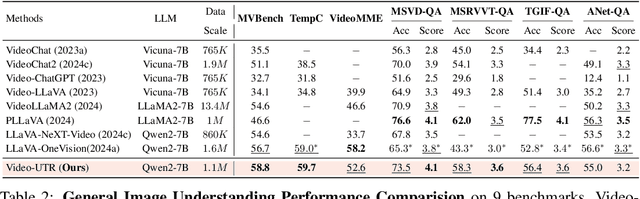
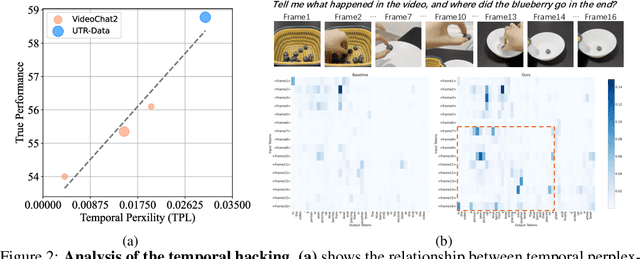

In the pursuit of superior video-processing MLLMs, we have encountered a perplexing paradox: the "anti-scaling law", where more data and larger models lead to worse performance. This study unmasks the culprit: "temporal hacking", a phenomenon where models shortcut by fixating on select frames, missing the full video narrative. In this work, we systematically establish a comprehensive theory of temporal hacking, defining it from a reinforcement learning perspective, introducing the Temporal Perplexity (TPL) score to assess this misalignment, and proposing the Unhackable Temporal Rewarding (UTR) framework to mitigate the temporal hacking. Both theoretically and empirically, TPL proves to be a reliable indicator of temporal modeling quality, correlating strongly with frame activation patterns. Extensive experiments reveal that UTR not only counters temporal hacking but significantly elevates video comprehension capabilities. This work not only advances video-AI systems but also illuminates the critical importance of aligning proxy rewards with true objectives in MLLM development.
Cross-View Referring Multi-Object Tracking
Dec 23, 2024



Referring Multi-Object Tracking (RMOT) is an important topic in the current tracking field. Its task form is to guide the tracker to track objects that match the language description. Current research mainly focuses on referring multi-object tracking under single-view, which refers to a view sequence or multiple unrelated view sequences. However, in the single-view, some appearances of objects are easily invisible, resulting in incorrect matching of objects with the language description. In this work, we propose a new task, called Cross-view Referring Multi-Object Tracking (CRMOT). It introduces the cross-view to obtain the appearances of objects from multiple views, avoiding the problem of the invisible appearances of objects in RMOT task. CRMOT is a more challenging task of accurately tracking the objects that match the language description and maintaining the identity consistency of objects in each cross-view. To advance CRMOT task, we construct a cross-view referring multi-object tracking benchmark based on CAMPUS and DIVOTrack datasets, named CRTrack. Specifically, it provides 13 different scenes and 221 language descriptions. Furthermore, we propose an end-to-end cross-view referring multi-object tracking method, named CRTracker. Extensive experiments on the CRTrack benchmark verify the effectiveness of our method. The dataset and code are available at https://github.com/chen-si-jia/CRMOT.