 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Better Instruction Following Retrieval Models
May 27, 2025



Modern information retrieval (IR) models, trained exclusively on standard <query, passage> pairs, struggle to effectively interpret and follow explicit user instructions. We introduce InF-IR, a large-scale, high-quality training corpus tailored for enhancing retrieval models in Instruction-Following IR. InF-IR expands traditional training pairs into over 38,000 expressive <instruction, query, passage> triplets as positive samples. In particular, for each positive triplet, we generate two additional hard negative examples by poisoning both instructions and queries, then rigorously validated by an advanced reasoning model (o3-mini) to ensure semantic plausibility while maintaining instructional incorrectness. Unlike existing corpora that primarily support computationally intensive reranking tasks for decoder-only language models, the highly contrastive positive-negative triplets in InF-IR further enable efficient representation learning for smaller encoder-only models, facilitating direct embedding-based retrieval. Using this corpus, we train InF-Embed, an instruction-aware Embedding model optimized through contrastive learning and instruction-query attention mechanisms to align retrieval outcomes precisely with user intents. Extensive experiments across five instruction-based retrieval benchmarks demonstrate that InF-Embed significantly surpasses competitive baselines by 8.1% in p-MRR, measuring the instruction-following capabilities.
AmorLIP: Efficient Language-Image Pretraining via Amortization
May 25, 2025



Contrastive Language-Image Pretraining (CLIP) has demonstrated strong zero-shot performance across diverse downstream text-image tasks. Existing CLIP methods typically optimize a contrastive objective using negative samples drawn from each minibatch. To achieve robust representation learning, these methods require extremely large batch sizes and escalate computational demands to hundreds or even thousands of GPUs. Prior approaches to mitigate this issue often compromise downstream performance, prolong training duration, or face scalability challenges with very large datasets. To overcome these limitations, we propose AmorLIP, an efficient CLIP pretraining framework that amortizes expensive computations involved in contrastive learning through lightweight neural networks, which substantially improves training efficiency and performance. Leveraging insights from a spectral factorization of energy-based models, we introduce novel amortization objectives along with practical techniques to improve training stability. Extensive experiments across 38 downstream tasks demonstrate the superior zero-shot classification and retrieval capabilities of AmorLIP, consistently outperforming standard CLIP baselines with substantial relative improvements of up to 12.24%.
SDDBench: A Benchmark for Synthesizable Drug Design
Nov 13, 2024



A significant challenge in wet lab experiments with current drug design generative models is the trade-off between pharmacological properties and synthesizability. Molecules predicted to have highly desirable properties are often difficult to synthesize, while those that are easily synthesizable tend to exhibit less favorable properties. As a result, evaluating the synthesizability of molecules in general drug design scenarios remains a significant challenge in the field of drug discovery. The commonly used synthetic accessibility (SA) score aims to evaluate the ease of synthesizing generated molecules, but it falls short of guaranteeing that synthetic routes can actually be found. Inspired by recent advances in top-down synthetic route generation, we propose a new, data-driven metric to evaluate molecule synthesizability. Our approach directly assesses the feasibility of synthetic routes for a given molecule through our proposed round-trip score. This novel metric leverages the synergistic duality between retrosynthetic planners and reaction predictors, both of which are trained on extensive reaction datasets. To demonstrate the efficacy of our method, we conduct a comprehensive evaluation of round-trip scores alongside search success rate across a range of representative molecule generative models. Code is available at https://github.com/SongtaoLiu0823/SDDBench.
Matryoshka: Learning to Drive Black-Box LLMs with LLMs
Oct 28, 2024Despite the impressive generative abilities of black-box large language models (LLMs), their inherent opacity hinders further advancements in capabilities such as reasoning, planning, and personalization. Existing works aim to enhance LLM capabilities via domain-specific adaptation or in-context learning, which require additional training on accessible model parameters, an infeasible option for black-box LLMs. To address this challenge, we introduce Matryoshika, a lightweight white-box LLM controller that guides a large-scale black-box LLM generator by decomposing complex tasks into a series of intermediate outputs. Specifically, we consider the black-box LLM as an environment, with Matryoshika serving as a policy to provide intermediate guidance through prompts for driving the black-box LLM. Matryoshika is trained to pivot the outputs of the black-box LLM aligning with preferences during iterative interaction, which enables controllable multi-turn generation and self-improvement in optimizing intermediate guidance. Empirical evaluations on three diverse tasks demonstrate that Matryoshika effectively enhances the capabilities of black-box LLMs in complex, long-horizon tasks, including reasoning, planning, and personalization. By leveraging this pioneering controller-generator framework to mitigate dependence on model parameters, Matryoshika provides a transparent and practical solution for improving black-box LLMs through controllable multi-turn generation using white-box LLMs.
Faster WIND: Accelerating Iterative Best-of-$N$ Distillation for LLM Alignment
Oct 28, 2024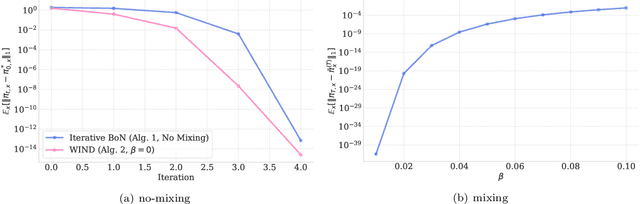
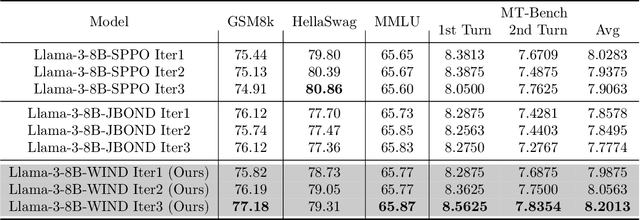
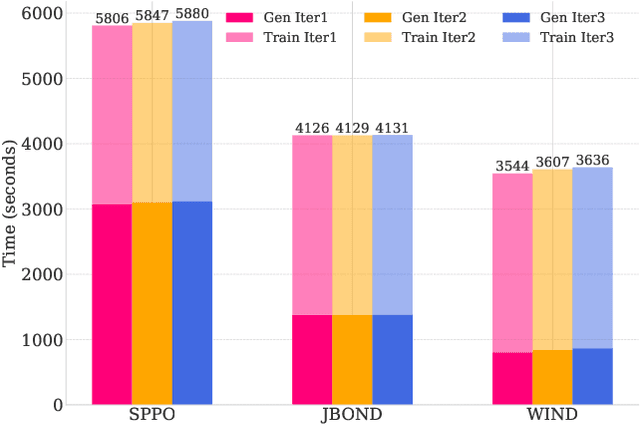
Recent advances in aligning large language models with human preferences have corroborated the growing importance of best-of-N distillation (BOND). However, the iterative BOND algorithm is prohibitively expensive in practice due to the sample and computation inefficiency. This paper addresses the problem by revealing a unified game-theoretic connection between iterative BOND and self-play alignment, which unifies seemingly disparate algorithmic paradigms. Based on the connection, we establish a novel framework, WIN rate Dominance (WIND), with a series of efficient algorithms for regularized win rate dominance optimization that approximates iterative BOND in the parameter space. We provides provable sample efficiency guarantee for one of the WIND variant with the square loss objective. The experimental results confirm that our algorithm not only accelerates the computation, but also achieves superior sample efficiency compared to existing methods.
Autoregressive Large Language Models are Computationally Universal
Oct 04, 2024


We show that autoregressive decoding of a transformer-based language model can realize universal computation, without external intervention or modification of the model's weights. Establishing this result requires understanding how a language model can process arbitrarily long inputs using a bounded context. For this purpose, we consider a generalization of autoregressive decoding where, given a long input, emitted tokens are appended to the end of the sequence as the context window advances. We first show that the resulting system corresponds to a classical model of computation, a Lag system, that has long been known to be computationally universal. By leveraging a new proof, we show that a universal Turing machine can be simulated by a Lag system with 2027 production rules. We then investigate whether an existing large language model can simulate the behaviour of such a universal Lag system. We give an affirmative answer by showing that a single system-prompt can be developed for gemini-1.5-pro-001 that drives the model, under deterministic (greedy) decoding, to correctly apply each of the 2027 production rules. We conclude that, by the Church-Turing thesis, prompted gemini-1.5-pro-001 with extended autoregressive (greedy) decoding is a general purpose computer.
Exploring and Benchmarking the Planning Capabilities of Large Language Models
Jun 18, 2024



We seek to elevate the planning capabilities of Large Language Models (LLMs)investigating four main directions. First, we construct a comprehensive benchmark suite encompassing both classical planning domains and natural language scenarios. This suite includes algorithms to generate instances with varying levels of difficulty, allowing for rigorous and systematic evaluation of LLM performance. Second, we investigate the use of in-context learning (ICL) to enhance LLM planning, exploring the direct relationship between increased context length and improved planning performance. Third, we demonstrate the positive impact of fine-tuning LLMs on optimal planning paths, as well as the effectiveness of incorporating model-driven search procedures. Finally, we investigate the performance of the proposed methods in out-of-distribution scenarios, assessing the ability to generalize to novel and unseen planning challenges.
Preference Optimization for Molecule Synthesis with Conditional Residual Energy-based Models
Jun 04, 2024



Molecule synthesis through machine learning is one of the fundamental problems in drug discovery. Current data-driven strategies employ one-step retrosynthesis models and search algorithms to predict synthetic routes in a top-bottom manner. Despite their effective performance, these strategies face limitations in the molecule synthetic route generation due to a greedy selection of the next molecule set without any lookahead. Furthermore, existing strategies cannot control the generation of synthetic routes based on possible criteria such as material costs, yields, and step count. In this work, we propose a general and principled framework via conditional residual energy-based models (EBMs), that focus on the quality of the entire synthetic route based on the specific criteria. By incorporating an additional energy-based function into our probabilistic model, our proposed algorithm can enhance the quality of the most probable synthetic routes (with higher probabilities) generated by various strategies in a plug-and-play fashion. Extensive experiments demonstrate that our framework can consistently boost performance across various strategies and outperforms previous state-of-the-art top-1 accuracy by a margin of 2.5%. Code is available at https://github.com/SongtaoLiu0823/CREBM.
Value-Incentivized Preference Optimization: A Unified Approach to Online and Offline RLHF
May 29, 2024


Reinforcement learning from human feedback (RLHF) has demonstrated great promise in aligning large language models (LLMs) with human preference. Depending on the availability of preference data, both online and offline RLHF are active areas of investigation. A key bottleneck is understanding how to incorporate uncertainty estimation in the reward function learned from the preference data for RLHF, regardless of how the preference data is collected. While the principles of optimism or pessimism under uncertainty are well-established in standard reinforcement learning (RL), a practically-implementable and theoretically-grounded form amenable to large language models is not yet available, as standard techniques for constructing confidence intervals become intractable under arbitrary policy parameterizations. In this paper, we introduce a unified approach to online and offline RLHF -- value-incentivized preference optimization (VPO) -- which regularizes the maximum-likelihood estimate of the reward function with the corresponding value function, modulated by a $\textit{sign}$ to indicate whether the optimism or pessimism is chosen. VPO also directly optimizes the policy with implicit reward modeling, and therefore shares a simpler RLHF pipeline similar to direct preference optimization. Theoretical guarantees of VPO are provided for both online and offline settings, matching the rates of their standard RL counterparts. Moreover, experiments on text summarization and dialog verify the practicality and effectiveness of VPO.
Beyond Expectations: Learning with Stochastic Dominance Made Practical
Feb 05, 2024



Stochastic dominance models risk-averse preferences for decision making with uncertain outcomes, which naturally captures the intrinsic structure of the underlying uncertainty, in contrast to simply resorting to the expectations. Despite theoretically appealing, the application of stochastic dominance in machine learning has been scarce, due to the following challenges: $\textbf{i)}$, the original concept of stochastic dominance only provides a $\textit{partial order}$, therefore, is not amenable to serve as an optimality criterion; and $\textbf{ii)}$, an efficient computational recipe remains lacking due to the continuum nature of evaluating stochastic dominance.%, which barriers its application for machine learning. In this work, we make the first attempt towards establishing a general framework of learning with stochastic dominance. We first generalize the stochastic dominance concept to enable feasible comparisons between any arbitrary pair of random variables. We next develop a simple and computationally efficient approach for finding the optimal solution in terms of stochastic dominance, which can be seamlessly plugged into many learning tasks. Numerical experiments demonstrate that the proposed method achieves comparable performance as standard risk-neutral strategies and obtains better trade-offs against risk across a variety of applications including supervised learning, reinforcement learning, and portfolio optimization.