 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralizing Graph Foundation Models via Hyperbolic Retrieval-Augmented Generation
Jun 03, 2026Graph foundation models (GFMs) emerged as a dominant paradigm in graph representation learning by leveraging large-scale pre-training for cross-domain inference. However, the parameterized knowledge encoded within these models is insufficient to cope with distribution shifts, limiting their generalization ability. To mitigate this issue, retrieval-augmented generation (RAG) has been introduced to incorporate external knowledge at inference time. Nevertheless, existing RAG frameworks operating in Euclidean space suffer from a fundamental geometric limitation: the polynomial volume growth of Euclidean space is inherently mismatched with the tree-structured external knowledge bases. This mismatch leads to the loss of semantic granularity in retrieval and gives rise to the hubness phenomenon.To address this limitation, we propose a Hyperbolic Retrieval-Augmented Generation (HyRAG) framework designed to enhance the generalization capabilities of GFMs. Specifically, the introduced Hyperbolic Knowledge Indexing module retains the tree-like hierarchies of the external knowledge base by modeling them within hyperbolic space. The Multi-granularity Retrieval module then provides GFMs with the global semantic anchors and local semantic nuances through coarse-grained and fine-grained knowledge retrieval, respectively. Finally, the Dual-path Fusion module achieves effective knowledge integration for graph tasks at both the feature and structural levels. Experiments on multiple graph benchmarks demonstrate significant improvements in the zero-shot setting, highlighting the generalization of our method for robust GFMs inference.
Periodic Steady-State Control of a Handkerchief-Spinning Task Using a Parallel Anti-Parallelogram Tendon-driven Wrist
Apr 20, 2026Spinning flexible objects, exemplified by traditional Chinese handkerchief performances, demands periodic steady-state motions under nonlinear dynamics with frictional contacts and boundary constraints. To address these challenges, we first design an intuitive dexterous wrist based on a parallel anti-parallelogram tendon-driven structure, which achieves 90 degrees omnidirectional rotation with low inertia and decoupled roll-pitch sensing, and implement a high-low level hierarchical control scheme. We then develop a particle-spring model of the handkerchief for control-oriented abstraction and strategy evaluation. Hardware experiments validate this framework, achieving an unfolding ratio of approximately 99% and fingertip tracking error of RMSE = 2.88 mm in high-dynamic spinning. These results demonstrate that integrating control-oriented modeling with a task-tailored dexterous wrist enables robust rest-to-steady-state transitions and precise periodic manipulation of highly flexible objects. More visualizations: https://slowly1113.github.io/icra2026-handkerchief/
Test-Time Perturbation Learning with Delayed Feedback for Vision-Language-Action Models
Apr 20, 2026Vision-Language-Action models (VLAs) achieve remarkable performance in sequential decision-making but remain fragile to subtle environmental shifts, such as small changes in object pose. We attribute this brittleness to trajectory overfitting, where VLAs over-attend to the spurious correlation between actions and entities, then reproduce memorized action patterns. We propose Perturbation learning with Delayed Feedback (PDF), a verifier-free test-time adaptation framework that improves decision performance without fine-tuning the base model. PDF mitigates the spurious correlation through uncertainty-based data augmentation and action voting, while an adaptive scheduler allocates augmentation budgets to balance performance and efficiency. To further improve stability, PDF learns a lightweight perturbation module that retrospectively adjusts action logits guided by delayed feedback, correcting overconfidence issue. Experiments on LIBERO (+7.4\% success rate) and Atari (+10.3 human normalized score) demonstrate consistent gains of PDF in task success over vanilla VLA and VLA with test-time adaptation, establishing a practical path toward reliable test-time adaptation in multimodal decision-making agents. The code is available at \href{https://github.com/zhoujiahuan1991/CVPR2026-PDF}{https://github.com/zhoujiahuan1991/CVPR2026-PDF}.
* 12 pages, 7 figures, 5 tables
Evolving the Complete Muscle: Efficient Morphology-Control Co-design for Musculoskeletal Locomotion
Apr 14, 2026Musculoskeletal robots offer intrinsic compliance and flexibility, providing a promising paradigm for versatile locomotion. However, existing research typically relies on models with fixed muscle physiological parameters. This static physical setting fails to accommodate the diverse dynamic demands of complex tasks, inherently limiting the robot's performance upper bound. In this work, we focus on the morphology and control co-design of musculoskeletal systems. Unlike previous studies that optimize single physiological attributes such as stiffness, we introduce a Complete Musculoskeletal Morphological Evolution Space that simultaneously evolves muscle strength, velocity, and stiffness. To overcome the exponential expansion of the exploration space caused by this comprehensive evolution, we propose Spectral Design Evolution (SDE), a high-efficiency co-optimization framework. By integrating a bilateral symmetry prior with Principal Component Analysis (PCA), SDE projects complex muscle parameters onto a low-dimensional spectral manifold, enabling efficient morphological exploration. Evaluated on the MyoSuite framework across four tasks (Walk, Stair, Hilly, and Rough terrains), our method demonstrates superior learning efficiency and locomotion stability compared to fixed-morphology and standard evolutionary baselines.
All-in-One Image Restoration via Causal-Deconfounding Wavelet-Disentangled Prompt Network
Mar 04, 2026Image restoration represents a promising approach for addressing the inherent defects of image content distortion. Standard image restoration approaches suffer from high storage cost and the requirement towards the known degradation pattern, including type and degree, which can barely be satisfied in dynamic practical scenarios. In contrast, all-in-one image restoration (AiOIR) eliminates multiple degradations within a unified model to circumvent the aforementioned issues. However, according to our causal analysis, we disclose that two significant defects still exacerbate the effectiveness and generalization of AiOIR models: 1) the spurious correlation between non-degradation semantic features and degradation patterns; 2) the biased estimation of degradation patterns. To obtain the true causation between degraded images and restored images, we propose Causal-deconfounding Wavelet-disentangled Prompt Network (CWP-Net) to perform effective AiOIR. CWP-Net introduces two modules for decoupling, i.e., wavelet attention module of encoder and wavelet attention module of decoder. These modules explicitly disentangle the degradation and semantic features to tackle the issue of spurious correlation. To address the issue stemming from the biased estimation of degradation patterns, CWP-Net leverages a wavelet prompt block to generate the alternative variable for causal deconfounding. Extensive experiments on two all-in-one settings prove the effectiveness and superior performance of our proposed CWP-Net over the state-of-the-art AiOIR methods.
SceneTransporter: Optimal Transport-Guided Compositional Latent Diffusion for Single-Image Structured 3D Scene Generation
Feb 26, 2026We introduce SceneTransporter, an end-to-end framework for structured 3D scene generation from a single image. While existing methods generate part-level 3D objects, they often fail to organize these parts into distinct instances in open-world scenes. Through a debiased clustering probe, we reveal a critical insight: this failure stems from the lack of structural constraints within the model's internal assignment mechanism. Based on this finding, we reframe the task of structured 3D scene generation as a global correlation assignment problem. To solve this, SceneTransporter formulates and solves an entropic Optimal Transport (OT) objective within the denoising loop of the compositional DiT model. This formulation imposes two powerful structural constraints. First, the resulting transport plan gates cross-attention to enforce an exclusive, one-to-one routing of image patches to part-level 3D latents, preventing entanglement. Second, the competitive nature of the transport encourages the grouping of similar patches, a process that is further regularized by an edge-based cost, to form coherent objects and prevent fragmentation. Extensive experiments show that SceneTransporter outperforms existing methods on open-world scene generation, significantly improving instance-level coherence and geometric fidelity. Code and models will be publicly available at https://2019epwl.github.io/SceneTransporter/.
FLAC: Maximum Entropy RL via Kinetic Energy Regularized Bridge Matching
Feb 13, 2026Iterative generative policies, such as diffusion models and flow matching, offer superior expressivity for continuous control but complicate Maximum Entropy Reinforcement Learning because their action log-densities are not directly accessible. To address this, we propose Field Least-Energy Actor-Critic (FLAC), a likelihood-free framework that regulates policy stochasticity by penalizing the kinetic energy of the velocity field. Our key insight is to formulate policy optimization as a Generalized Schrödinger Bridge (GSB) problem relative to a high-entropy reference process (e.g., uniform). Under this view, the maximum-entropy principle emerges naturally as staying close to a high-entropy reference while optimizing return, without requiring explicit action densities. In this framework, kinetic energy serves as a physically grounded proxy for divergence from the reference: minimizing path-space energy bounds the deviation of the induced terminal action distribution. Building on this view, we derive an energy-regularized policy iteration scheme and a practical off-policy algorithm that automatically tunes the kinetic energy via a Lagrangian dual mechanism. Empirically, FLAC achieves superior or comparable performance on high-dimensional benchmarks relative to strong baselines, while avoiding explicit density estimation.
Flow-Based Policy for Online Reinforcement Learning
Jun 15, 2025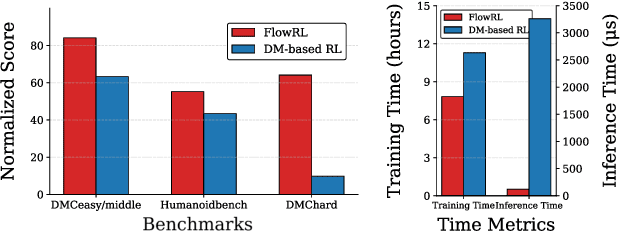



We present \textbf{FlowRL}, a novel framework for online reinforcement learning that integrates flow-based policy representation with Wasserstein-2-regularized optimization. We argue that in addition to training signals, enhancing the expressiveness of the policy class is crucial for the performance gains in RL. Flow-based generative models offer such potential, excelling at capturing complex, multimodal action distributions. However, their direct application in online RL is challenging due to a fundamental objective mismatch: standard flow training optimizes for static data imitation, while RL requires value-based policy optimization through a dynamic buffer, leading to difficult optimization landscapes. FlowRL first models policies via a state-dependent velocity field, generating actions through deterministic ODE integration from noise. We derive a constrained policy search objective that jointly maximizes Q through the flow policy while bounding the Wasserstein-2 distance to a behavior-optimal policy implicitly derived from the replay buffer. This formulation effectively aligns the flow optimization with the RL objective, enabling efficient and value-aware policy learning despite the complexity of the policy class. Empirical evaluations on DMControl and Humanoidbench demonstrate that FlowRL achieves competitive performance in online reinforcement learning benchmarks.
On the Transferability and Discriminability of Repersentation Learning in Unsupervised Domain Adaptation
May 28, 2025In this paper, we addressed the limitation of relying solely on distribution alignment and source-domain empirical risk minimization in Unsupervised Domain Adaptation (UDA). Our information-theoretic analysis showed that this standard adversarial-based framework neglects the discriminability of target-domain features, leading to suboptimal performance. To bridge this theoretical-practical gap, we defined "good representation learning" as guaranteeing both transferability and discriminability, and proved that an additional loss term targeting target-domain discriminability is necessary. Building on these insights, we proposed a novel adversarial-based UDA framework that explicitly integrates a domain alignment objective with a discriminability-enhancing constraint. Instantiated as Domain-Invariant Representation Learning with Global and Local Consistency (RLGLC), our method leverages Asymmetrically-Relaxed Wasserstein of Wasserstein Distance (AR-WWD) to address class imbalance and semantic dimension weighting, and employs a local consistency mechanism to preserve fine-grained target-domain discriminative information. Extensive experiments across multiple benchmark datasets demonstrate that RLGLC consistently surpasses state-of-the-art methods, confirming the value of our theoretical perspective and underscoring the necessity of enforcing both transferability and discriminability in adversarial-based UDA.
Multi-segment Soft Robot Control via Deep Koopman-based Model Predictive Control
May 01, 2025Soft robots, compared to regular rigid robots, as their multiple segments with soft materials bring flexibility and compliance, have the advantages of safe interaction and dexterous operation in the environment. However, due to its characteristics of high dimensional, nonlinearity, time-varying nature, and infinite degree of freedom, it has been challenges in achieving precise and dynamic control such as trajectory tracking and position reaching. To address these challenges, we propose a framework of Deep Koopman-based Model Predictive Control (DK-MPC) for handling multi-segment soft robots. We first employ a deep learning approach with sampling data to approximate the Koopman operator, which therefore linearizes the high-dimensional nonlinear dynamics of the soft robots into a finite-dimensional linear representation. Secondly, this linearized model is utilized within a model predictive control framework to compute optimal control inputs that minimize the tracking error between the desired and actual state trajectories. The real-world experiments on the soft robot "Chordata" demonstrate that DK-MPC could achieve high-precision control, showing the potential of DK-MPC for future applications to soft robots.