 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmooth Computation without Input Delay: Robust Tube-Based Model Predictive Control for Robot Manipulator Planning
Mar 09, 2024



Model Predictive Control (MPC) has exhibited remarkable capabilities in optimizing objectives and meeting constraints. However, the substantial computational burden associated with solving the Optimal Control Problem (OCP) at each triggering instant introduces significant delays between state sampling and control application. These delays limit the practicality of MPC in resource-constrained systems when engaging in complex tasks. The intuition to address this issue in this paper is that by predicting the successor state, the controller can solve the OCP one time step ahead of time thus avoiding the delay of the next action. To this end, we compute deviations between real and nominal system states, predicting forthcoming real states as initial conditions for the imminent OCP solution. Anticipatory computation stores optimal control based on current nominal states, thus mitigating the delay effects. Additionally, we establish an upper bound for linearization error, effectively linearizing the nonlinear system, reducing OCP complexity, and enhancing response speed. We provide empirical validation through two numerical simulations and corresponding real-world robot tasks, demonstrating significant performance improvements and augmented response speed (up to $90\%$) resulting from the seamless integration of our proposed approach compared to conventional time-triggered MPC strategies.
Exploring Visual Pre-training for Robot Manipulation: Datasets, Models and Methods
Aug 07, 2023



Visual pre-training with large-scale real-world data has made great progress in recent years, showing great potential in robot learning with pixel observations. However, the recipes of visual pre-training for robot manipulation tasks are yet to be built. In this paper, we thoroughly investigate the effects of visual pre-training strategies on robot manipulation tasks from three fundamental perspectives: pre-training datasets, model architectures and training methods. Several significant experimental findings are provided that are beneficial for robot learning. Further, we propose a visual pre-training scheme for robot manipulation termed Vi-PRoM, which combines self-supervised learning and supervised learning. Concretely, the former employs contrastive learning to acquire underlying patterns from large-scale unlabeled data, while the latter aims learning visual semantics and temporal dynamics. Extensive experiments on robot manipulations in various simulation environments and the real robot demonstrate the superiority of the proposed scheme. Videos and more details can be found on \url{https://explore-pretrain-robot.github.io}.
MOMA-Force: Visual-Force Imitation for Real-World Mobile Manipulation
Aug 07, 2023



In this paper, we present a novel method for mobile manipulators to perform multiple contact-rich manipulation tasks. While learning-based methods have the potential to generate actions in an end-to-end manner, they often suffer from insufficient action accuracy and robustness against noise. On the other hand, classical control-based methods can enhance system robustness, but at the cost of extensive parameter tuning. To address these challenges, we present MOMA-Force, a visual-force imitation method that seamlessly combines representation learning for perception, imitation learning for complex motion generation, and admittance whole-body control for system robustness and controllability. MOMA-Force enables a mobile manipulator to learn multiple complex contact-rich tasks with high success rates and small contact forces. In a real household setting, our method outperforms baseline methods in terms of task success rates. Moreover, our method achieves smaller contact forces and smaller force variances compared to baseline methods without force imitation. Overall, we offer a promising approach for efficient and robust mobile manipulation in the real world. Videos and more details can be found on \url{https://visual-force-imitation.github.io}
Embodied Referring Expression for Manipulation Question Answering in Interactive Environment
Oct 06, 2022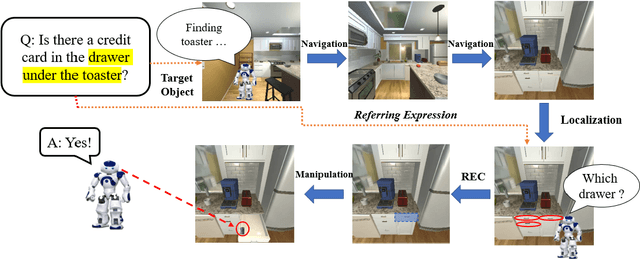
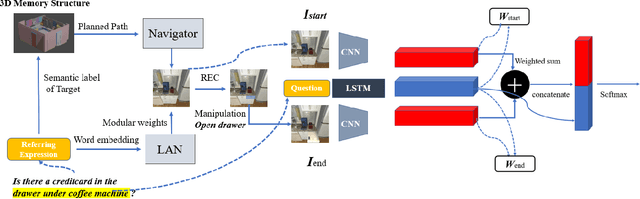

Embodied agents are expected to perform more complicated tasks in an interactive environment, with the progress of Embodied AI in recent years. Existing embodied tasks including Embodied Referring Expression (ERE) and other QA-form tasks mainly focuses on interaction in term of linguistic instruction. Therefore, enabling the agent to manipulate objects in the environment for exploration actively has become a challenging problem for the community. To solve this problem, We introduce a new embodied task: Remote Embodied Manipulation Question Answering (REMQA) to combine ERE with manipulation tasks. In the REMQA task, the agent needs to navigate to a remote position and perform manipulation with the target object to answer the question. We build a benchmark dataset for the REMQA task in the AI2-THOR simulator. To this end, a framework with 3D semantic reconstruction and modular network paradigms is proposed. The evaluation of the proposed framework on the REMQA dataset is presented to validate its effectiveness.
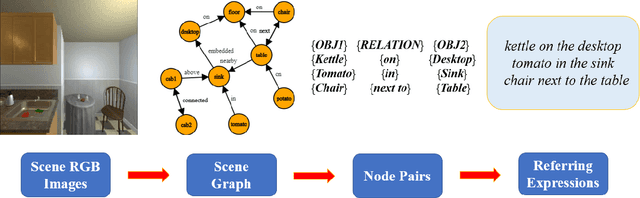
Scene Graph for Embodied Exploration in Cluttered Scenario
Jul 16, 2022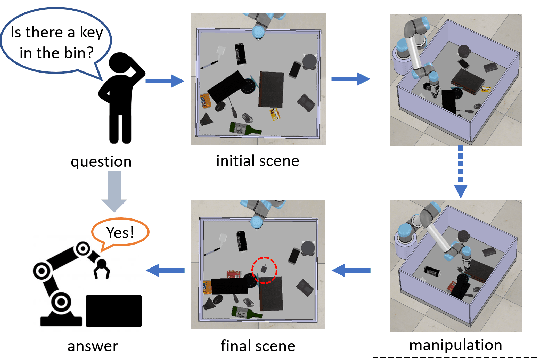
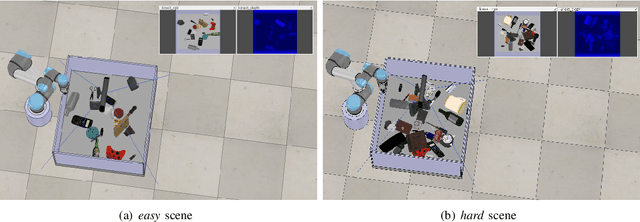
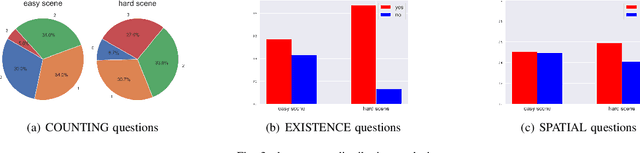
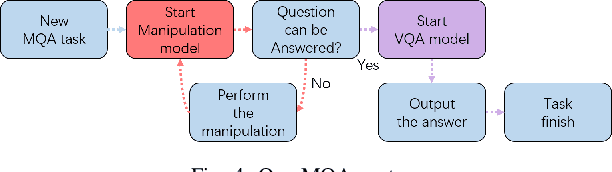
The ability to handle objects in cluttered environment has been long anticipated by robotic community. However, most of works merely focus on manipulation instead of rendering hidden semantic information in cluttered objects. In this work, we introduce the scene graph for embodied exploration in cluttered scenarios to solve this problem. To validate our method in cluttered scenario, we adopt the Manipulation Question Answering (MQA) tasks as our test benchmark, which requires an embodied robot to have the active exploration ability and semantic understanding ability of vision and language.As a general solution framework to the task, we propose an imitation learning method to generate manipulations for exploration. Meanwhile, a VQA model based on dynamic scene graph is adopted to comprehend a series of RGB frames from wrist camera of manipulator along with every step of manipulation is conducted to answer questions in our framework.The experiments on of MQA dataset with different interaction requirements demonstrate that our proposed framework is effective for MQA task a representative of tasks in cluttered scenario.
Simultaneous Trajectory Optimization and Force Control with Soft Contact Mechanics
Apr 21, 2020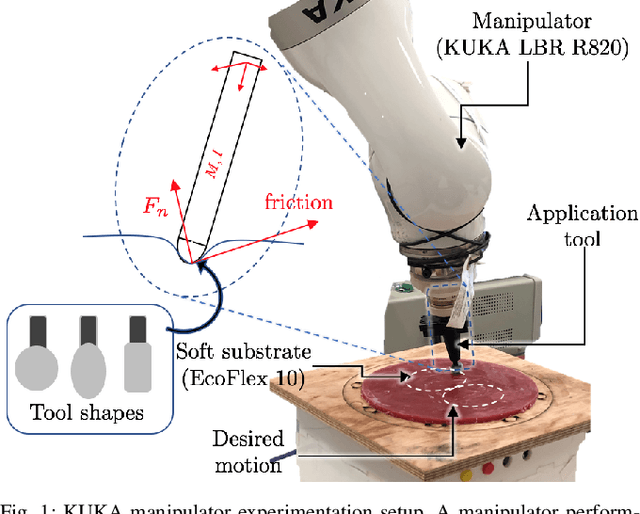
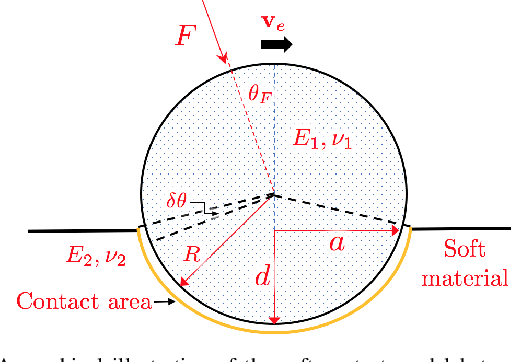
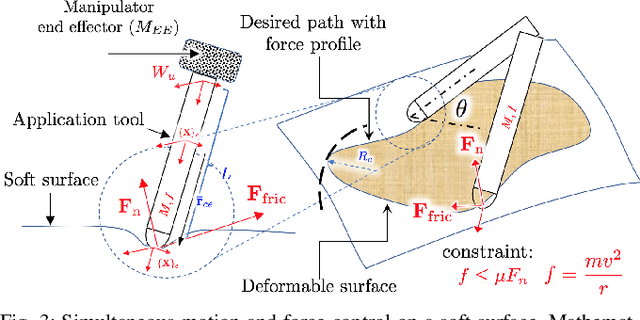

Force modulation of robotic manipulators has been extensively studied for several decades but is not yet commonly used in safety-critical applications due to a lack of accurate interaction contact modeling and weak performance guarantees - a large proportion of them concerning the modulation of interaction forces. This study presents a high-level framework for simultaneous trajectory optimization and force control of the interaction between manipulator and soft environments. Sliding friction and normal contact force are taken into account. The dynamics of the soft contact model and the manipulator dynamics are simultaneously incorporated in the trajectory optimizer to generate desired motion and force profiles. A constraint optimization framework based on Differential Dynamic Programming and Alternative Direction Method of Multipliers has been employed to generate optimal control input and high-dimensional state trajectories. Experimental validation of the model performance is conducted on a soft substrate with known material properties using Cartesian space force control mode. Results show a comparison of ground truth and predicted model based contact force states for a few cartesian motions and the validity range of the friction model. Potential applications include high-level task planning of medical tasks involving manipulation of compliant, delicate, and deformable tissues.