 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQwen2.5-1M Technical Report
Jan 26, 2025



We introduce Qwen2.5-1M, a series of models that extend the context length to 1 million tokens. Compared to the previous 128K version, the Qwen2.5-1M series have significantly enhanced long-context capabilities through long-context pre-training and post-training. Key techniques such as long data synthesis, progressive pre-training, and multi-stage supervised fine-tuning are employed to effectively enhance long-context performance while reducing training costs. To promote the use of long-context models among a broader user base, we present and open-source our inference framework. This framework includes a length extrapolation method that can expand the model context lengths by at least four times, or even more, without additional training. To reduce inference costs, we implement a sparse attention method along with chunked prefill optimization for deployment scenarios and a sparsity refinement method to improve precision. Additionally, we detail our optimizations in the inference engine, including kernel optimization, pipeline parallelism, and scheduling optimization, which significantly enhance overall inference performance. By leveraging our inference framework, the Qwen2.5-1M models achieve a remarkable 3x to 7x prefill speedup in scenarios with 1 million tokens of context. This framework provides an efficient and powerful solution for developing applications that require long-context processing using open-source models. The Qwen2.5-1M series currently includes the open-source models Qwen2.5-7B-Instruct-1M and Qwen2.5-14B-Instruct-1M, as well as the API-accessed model Qwen2.5-Turbo. Evaluations show that Qwen2.5-1M models have been greatly improved in long-context tasks without compromising performance in short-context scenarios. Specifically, the Qwen2.5-14B-Instruct-1M model significantly outperforms GPT-4o-mini in long-context tasks and supports contexts eight times longer.
KAnoCLIP: Zero-Shot Anomaly Detection through Knowledge-Driven Prompt Learning and Enhanced Cross-Modal Integration
Jan 07, 2025



Zero-shot anomaly detection (ZSAD) identifies anomalies without needing training samples from the target dataset, essential for scenarios with privacy concerns or limited data. Vision-language models like CLIP show potential in ZSAD but have limitations: relying on manually crafted fixed textual descriptions or anomaly prompts is time-consuming and prone to semantic ambiguity, and CLIP struggles with pixel-level anomaly segmentation, focusing more on global semantics than local details. To address these limitations, We introduce KAnoCLIP, a novel ZSAD framework that leverages vision-language models. KAnoCLIP combines general knowledge from a Large Language Model (GPT-3.5) and fine-grained, image-specific knowledge from a Visual Question Answering system (Llama3) via Knowledge-Driven Prompt Learning (KnPL). KnPL uses a knowledge-driven (KD) loss function to create learnable anomaly prompts, removing the need for fixed text prompts and enhancing generalization. KAnoCLIP includes the CLIP visual encoder with V-V attention (CLIP-VV), Bi-Directional Cross-Attention for Multi-Level Cross-Modal Interaction (Bi-CMCI), and Conv-Adapter. These components preserve local visual semantics, improve local cross-modal fusion, and align global visual features with textual information, enhancing pixel-level anomaly detection. KAnoCLIP achieves state-of-the-art performance in ZSAD across 12 industrial and medical datasets, demonstrating superior generalization compared to existing methods.
Qwen2.5 Technical Report
Dec 19, 2024



In this report, we introduce Qwen2.5, a comprehensive series of large language models (LLMs) designed to meet diverse needs. Compared to previous iterations, Qwen 2.5 has been significantly improved during both the pre-training and post-training stages. In terms of pre-training, we have scaled the high-quality pre-training datasets from the previous 7 trillion tokens to 18 trillion tokens. This provides a strong foundation for common sense, expert knowledge, and reasoning capabilities. In terms of post-training, we implement intricate supervised finetuning with over 1 million samples, as well as multistage reinforcement learning. Post-training techniques enhance human preference, and notably improve long text generation, structural data analysis, and instruction following. To handle diverse and varied use cases effectively, we present Qwen2.5 LLM series in rich sizes. Open-weight offerings include base and instruction-tuned models, with quantized versions available. In addition, for hosted solutions, the proprietary models currently include two mixture-of-experts (MoE) variants: Qwen2.5-Turbo and Qwen2.5-Plus, both available from Alibaba Cloud Model Studio. Qwen2.5 has demonstrated top-tier performance on a wide range of benchmarks evaluating language understanding, reasoning, mathematics, coding, human preference alignment, etc. Specifically, the open-weight flagship Qwen2.5-72B-Instruct outperforms a number of open and proprietary models and demonstrates competitive performance to the state-of-the-art open-weight model, Llama-3-405B-Instruct, which is around 5 times larger. Qwen2.5-Turbo and Qwen2.5-Plus offer superior cost-effectiveness while performing competitively against GPT-4o-mini and GPT-4o respectively. Additionally, as the foundation, Qwen2.5 models have been instrumental in training specialized models such as Qwen2.5-Math, Qwen2.5-Coder, QwQ, and multimodal models.
Rotated Runtime Smooth: Training-Free Activation Smoother for accurate INT4 inference
Sep 30, 2024



Large language models have demonstrated promising capabilities upon scaling up parameters. However, serving large language models incurs substantial computation and memory movement costs due to their large scale. Quantization methods have been employed to reduce service costs and latency. Nevertheless, outliers in activations hinder the development of INT4 weight-activation quantization. Existing approaches separate outliers and normal values into two matrices or migrate outliers from activations to weights, suffering from high latency or accuracy degradation. Based on observing activations from large language models, outliers can be classified into channel-wise and spike outliers. In this work, we propose Rotated Runtime Smooth (RRS), a plug-and-play activation smoother for quantization, consisting of Runtime Smooth and the Rotation operation. Runtime Smooth (RS) is introduced to eliminate channel-wise outliers by smoothing activations with channel-wise maximums during runtime. The rotation operation can narrow the gap between spike outliers and normal values, alleviating the effect of victims caused by channel-wise smoothing. The proposed method outperforms the state-of-the-art method in the LLaMA and Qwen families and improves WikiText-2 perplexity from 57.33 to 6.66 for INT4 inference.
Qwen2 Technical Report
Jul 16, 2024



This report introduces the Qwen2 series, the latest addition to our large language models and large multimodal models. We release a comprehensive suite of foundational and instruction-tuned language models, encompassing a parameter range from 0.5 to 72 billion, featuring dense models and a Mixture-of-Experts model. Qwen2 surpasses most prior open-weight models, including its predecessor Qwen1.5, and exhibits competitive performance relative to proprietary models across diverse benchmarks on language understanding, generation, multilingual proficiency, coding, mathematics, and reasoning. The flagship model, Qwen2-72B, showcases remarkable performance: 84.2 on MMLU, 37.9 on GPQA, 64.6 on HumanEval, 89.5 on GSM8K, and 82.4 on BBH as a base language model. The instruction-tuned variant, Qwen2-72B-Instruct, attains 9.1 on MT-Bench, 48.1 on Arena-Hard, and 35.7 on LiveCodeBench. Moreover, Qwen2 demonstrates robust multilingual capabilities, proficient in approximately 30 languages, spanning English, Chinese, Spanish, French, German, Arabic, Russian, Korean, Japanese, Thai, Vietnamese, and more, underscoring its versatility and global reach. To foster community innovation and accessibility, we have made the Qwen2 model weights openly available on Hugging Face and ModelScope, and the supplementary materials including example code on GitHub. These platforms also include resources for quantization, fine-tuning, and deployment, facilitating a wide range of applications and research endeavors.
Generative AI for Architectural Design: A Literature Review
Mar 30, 2024



Generative Artificial Intelligence (AI) has pioneered new methodological paradigms in architectural design, significantly expanding the innovative potential and efficiency of the design process. This paper explores the extensive applications of generative AI technologies in architectural design, a trend that has benefited from the rapid development of deep generative models. This article provides a comprehensive review of the basic principles of generative AI and large-scale models and highlights the applications in the generation of 2D images, videos, and 3D models. In addition, by reviewing the latest literature from 2020, this paper scrutinizes the impact of generative AI technologies at different stages of architectural design, from generating initial architectural 3D forms to producing final architectural imagery. The marked trend of research growth indicates an increasing inclination within the architectural design community towards embracing generative AI, thereby catalyzing a shared enthusiasm for research. These research cases and methodologies have not only proven to enhance efficiency and innovation significantly but have also posed challenges to the conventional boundaries of architectural creativity. Finally, we point out new directions for design innovation and articulate fresh trajectories for applying generative AI in the architectural domain. This article provides the first comprehensive literature review about generative AI for architectural design, and we believe this work can facilitate more research work on this significant topic in architecture.
Ripple Knowledge Graph Convolutional Networks For Recommendation Systems
May 02, 2023Using knowledge graphs to assist deep learning models in making recommendation decisions has recently been proven to effectively improve the model's interpretability and accuracy. This paper introduces an end-to-end deep learning model, named RKGCN, which dynamically analyses each user's preferences and makes a recommendation of suitable items. It combines knowledge graphs on both the item side and user side to enrich their representations to maximize the utilization of the abundant information in knowledge graphs. RKGCN is able to offer more personalized and relevant recommendations in three different scenarios. The experimental results show the superior effectiveness of our model over 5 baseline models on three real-world datasets including movies, books, and music.
A Long-term Dependent and Trustworthy Approach to Reactor Accident Prognosis based on Temporal Fusion Transformer
Oct 28, 2022



Prognosis of the reactor accident is a crucial way to ensure appropriate strategies are adopted to avoid radioactive releases. However, there is very limited research in the field of nuclear industry. In this paper, we propose a method for accident prognosis based on the Temporal Fusion Transformer (TFT) model with multi-headed self-attention and gating mechanisms. The method utilizes multiple covariates to improve prediction accuracy on the one hand, and quantile regression methods for uncertainty assessment on the other. The method proposed in this paper is applied to the prognosis after loss of coolant accidents (LOCAs) in HPR1000 reactor. Extensive experimental results show that the method surpasses novel deep learning-based prediction methods in terms of prediction accuracy and confidence. Furthermore, the interference experiments with different signal-to-noise ratios and the ablation experiments for static covariates further illustrate that the robustness comes from the ability to extract the features of static and historical covariates. In summary, this work for the first time applies the novel composite deep learning model TFT to the prognosis of key parameters after a reactor accident, and makes a positive contribution to the establishment of a more intelligent and staff-light maintenance method for reactor systems.
Representation Learning based and Interpretable Reactor System Diagnosis Using Denoising Padded Autoencoder
Aug 30, 2022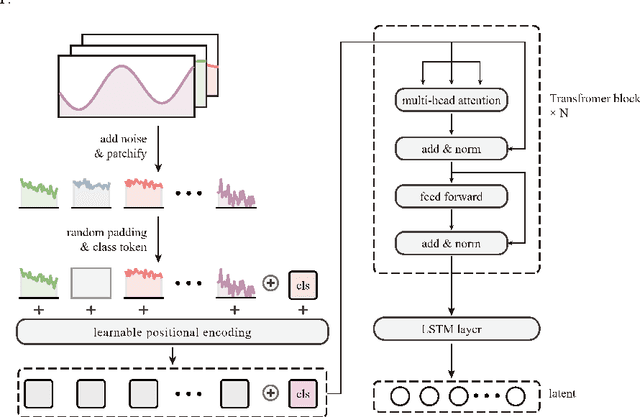
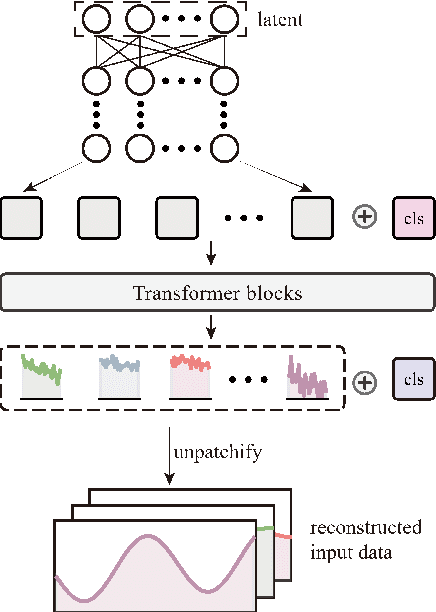

With the mass construction of Gen III nuclear reactors, it is a popular trend to use deep learning (DL) techniques for fast and effective diagnosis of possible accidents. To overcome the common problems of previous work in diagnosing reactor accidents using deep learning theory, this paper proposes a diagnostic process that ensures robustness to noisy and crippled data and is interpretable. First, a novel Denoising Padded Autoencoder (DPAE) is proposed for representation extraction of monitoring data, with representation extractor still effective on disturbed data with signal-to-noise ratios up to 25.0 and monitoring data missing up to 40.0%. Secondly, a diagnostic framework using DPAE encoder for extraction of representations followed by shallow statistical learning algorithms is proposed, and such stepwise diagnostic approach is tested on disturbed datasets with 41.8% and 80.8% higher classification and regression task evaluation metrics, in comparison with the end-to-end diagnostic approaches. Finally, a hierarchical interpretation algorithm using SHAP and feature ablation is presented to analyze the importance of the input monitoring parameters and validate the effectiveness of the high importance parameters. The outcomes of this study provide a referential method for building robust and interpretable intelligent reactor anomaly diagnosis systems in scenarios with high safety requirements.
An Unsupervised Learning-based Framework for Effective Representation Extraction of Reactor Accidents
Aug 28, 2022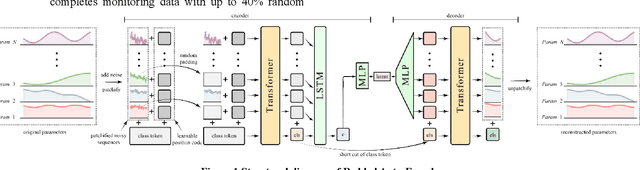
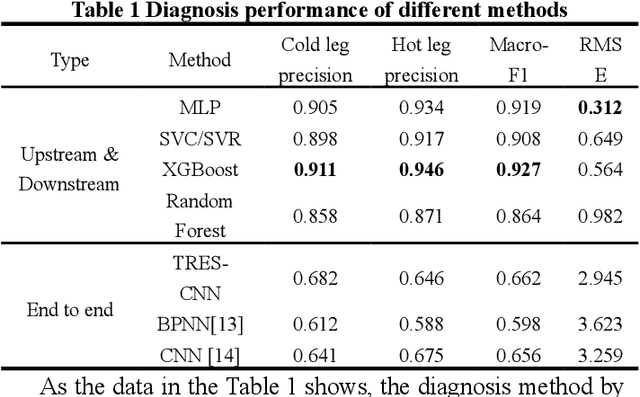
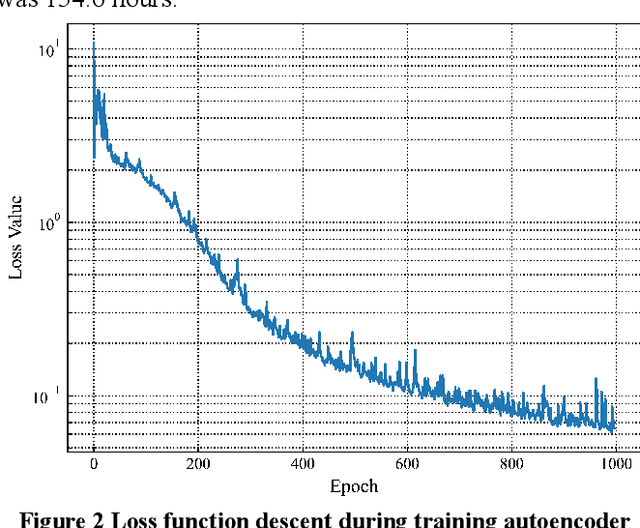
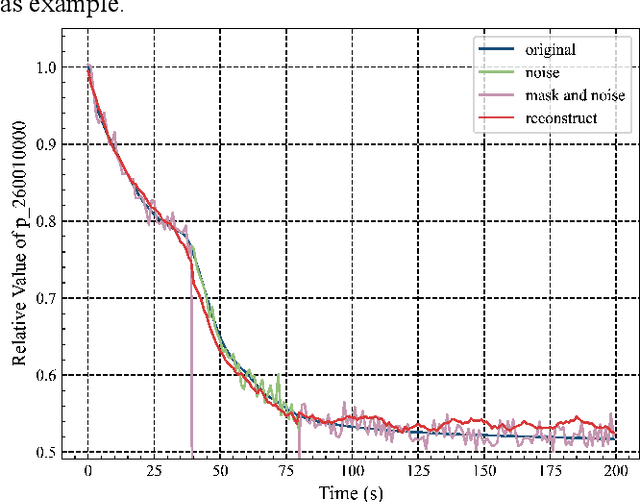
With the increasing use of high-precision system analysis programs in nuclear engineering, the number of high-fidelity computational data for accident simulation is exploding. Therefore, an algorithm that can achieve both automatic extraction of low-dimensional features from the data and guarantee the validity of the features is needed to improve the performance and confidence of the accident diagnosis system. This study proposes an autoencoder-based autonomous learning framework, namely Padded Auto-Encoder (PAE), which is able to automatically encode accident monitoring data that has been noise-added and with partially missing data into low-dimensional feature vectors via a Vision Transformer-based encoder, and to decode the feature vectors into noise-free and complete reconstructed monitoring data. Thus, the encoder part of the framework is able to automatically infer valid representations from partially missing and noisy monitoring data that reflect the complete and noise-free original data, and the representation vectors can be used for downstream tasks for accident diagnosis or else. In this paper, LOCA of HPR1000 was used as the study object, and the PAE was trained by an unsupervised method using cases with different break locations and sizes as the dataset. The encoder part of the pre-trained PAE was subsequently used as the feature extractor for the monitoring data, and several basic statistical learning algorithms for predicting the break locations and sizes. The results of the study show that the pre-trained diagnostic model with two stages has a better performance in break location and size diagnostic capability with an improvement of 41.62% and 80.86% in the metrics respectively, compared to the diagnostic model with end-to-end model structure.