 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReLMoGen: Leveraging Motion Generation in Reinforcement Learning for Mobile Manipulation
Aug 18, 2020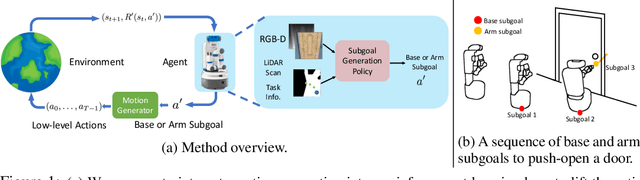
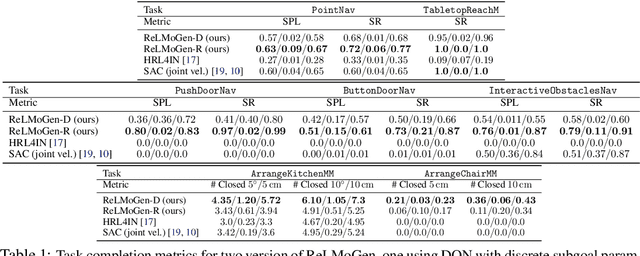
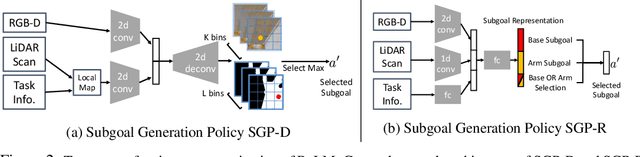

Many Reinforcement Learning (RL) approaches use joint control signals (positions, velocities, torques) as action space for continuous control tasks. We propose to lift the action space to a higher level in the form of subgoals for a motion generator (a combination of motion planner and trajectory executor). We argue that, by lifting the action space and by leveraging sampling-based motion planners, we can efficiently use RL to solve complex, long-horizon tasks that could not be solved with existing RL methods in the original action space. We propose ReLMoGen -- a framework that combines a learned policy to predict subgoals and a motion generator to plan and execute the motion needed to reach these subgoals. To validate our method, we apply ReLMoGen to two types of tasks: 1) Interactive Navigation tasks, navigation problems where interactions with the environment are required to reach the destination, and 2) Mobile Manipulation tasks, manipulation tasks that require moving the robot base. These problems are challenging because they are usually long-horizon, hard to explore during training, and comprise alternating phases of navigation and interaction. Our method is benchmarked on a diverse set of seven robotics tasks in photo-realistic simulation environments. In all settings, ReLMoGen outperforms state-of-the-art Reinforcement Learning and Hierarchical Reinforcement Learning baselines. ReLMoGen also shows outstanding transferability between different motion generators at test time, indicating a great potential to transfer to real robots.
Visuomotor Mechanical Search: Learning to Retrieve Target Objects in Clutter
Aug 13, 2020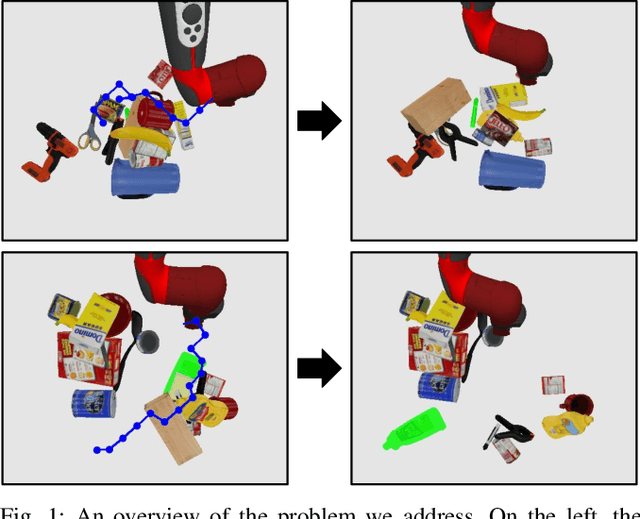
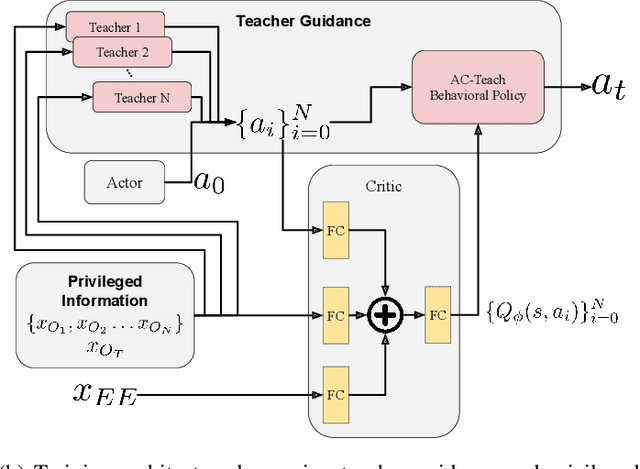
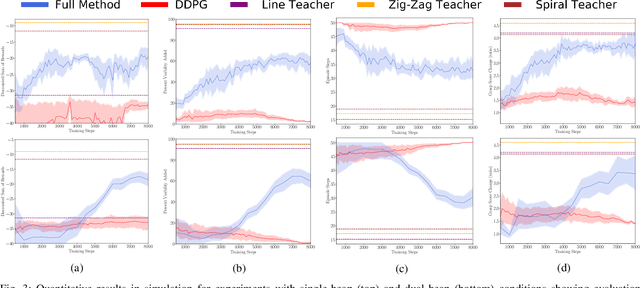
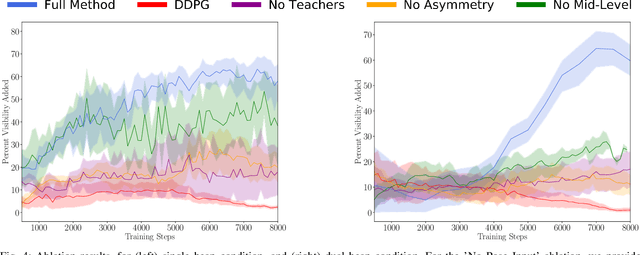
When searching for objects in cluttered environments, it is often necessary to perform complex interactions in order to move occluding objects out of the way and fully reveal the object of interest and make it graspable. Due to the complexity of the physics involved and the lack of accurate models of the clutter, planning and controlling precise predefined interactions with accurate outcome is extremely hard, when not impossible. In problems where accurate (forward) models are lacking, Deep Reinforcement Learning (RL) has shown to be a viable solution to map observations (e.g. images) to good interactions in the form of close-loop visuomotor policies. However, Deep RL is sample inefficient and fails when applied directly to the problem of unoccluding objects based on images. In this work we present a novel Deep RL procedure that combines i) teacher-aided exploration, ii) a critic with privileged information, and iii) mid-level representations, resulting in sample efficient and effective learning for the problem of uncovering a target object occluded by a heap of unknown objects. Our experiments show that our approach trains faster and converges to more efficient uncovering solutions than baselines and ablations, and that our uncovering policies lead to an average improvement in the graspability of the target object, facilitating downstream retrieval applications.
Goal-Aware Prediction: Learning to Model What Matters
Aug 10, 2020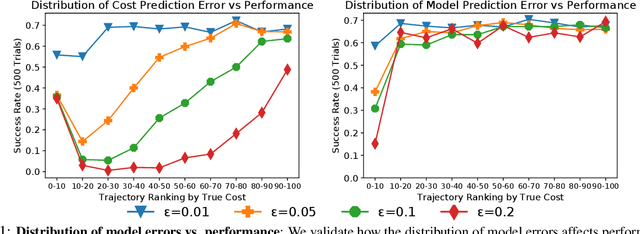
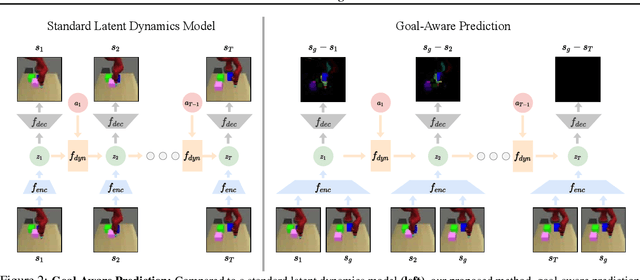
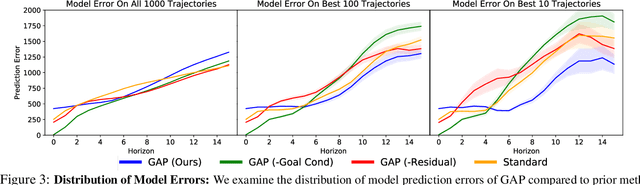
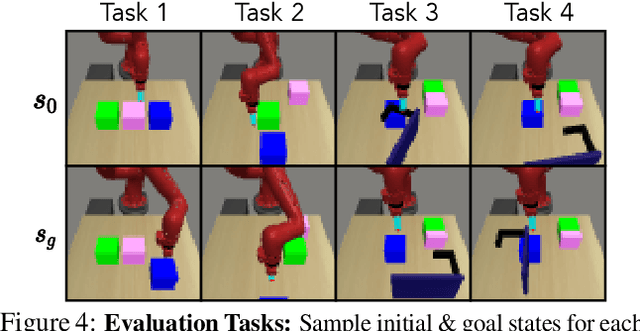
Learned dynamics models combined with both planning and policy learning algorithms have shown promise in enabling artificial agents to learn to perform many diverse tasks with limited supervision. However, one of the fundamental challenges in using a learned forward dynamics model is the mismatch between the objective of the learned model (future state reconstruction), and that of the downstream planner or policy (completing a specified task). This issue is exacerbated by vision-based control tasks in diverse real-world environments, where the complexity of the real world dwarfs model capacity. In this paper, we propose to direct prediction towards task relevant information, enabling the model to be aware of the current task and encouraging it to only model relevant quantities of the state space, resulting in a learning objective that more closely matches the downstream task. Further, we do so in an entirely self-supervised manner, without the need for a reward function or image labels. We find that our method more effectively models the relevant parts of the scene conditioned on the goal, and as a result outperforms standard task-agnostic dynamics models and model-free reinforcement learning.
How Trustworthy are the Existing Performance Evaluations for Basic Vision Tasks?
Aug 08, 2020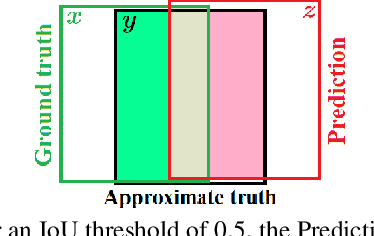
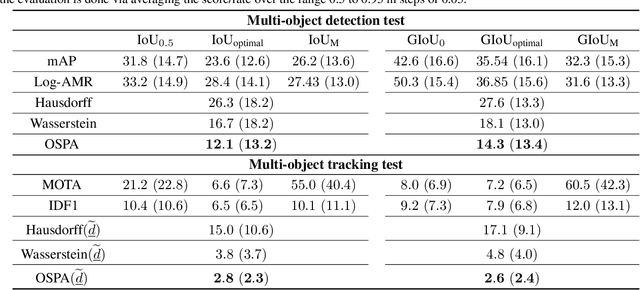
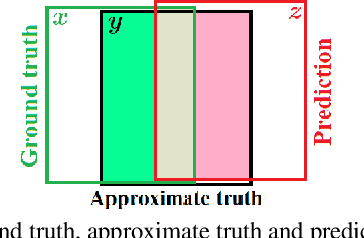
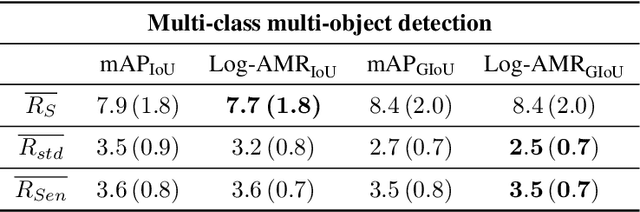
Performance evaluation is indispensable to the advancement of machine vision, yet its consistency and rigour have not received proportionate attention. This paper examines performance evaluation criteria for basic vision tasks namely, object detection, instance-level segmentation and multi-object tracking. Specifically, we advocate the use of criteria that are (i) consistent with mathematical requirements such as the metric properties, (ii) contextually meaningful in sanity tests, and (iii) robust to hyper-parameters for reliability. We show that many widely used performance criteria do not fulfill these requirements. Moreover, we explore alternative criteria for detection, segmentation, and tracking, using metrics for sets of shapes, and assess them against these requirements.
Adaptive Procedural Task Generation for Hard-Exploration Problems
Jul 01, 2020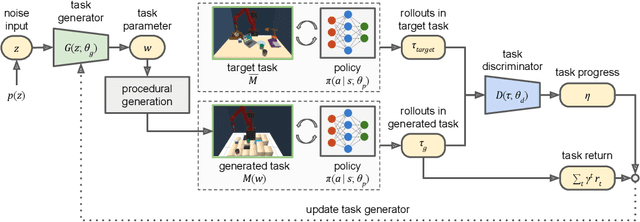
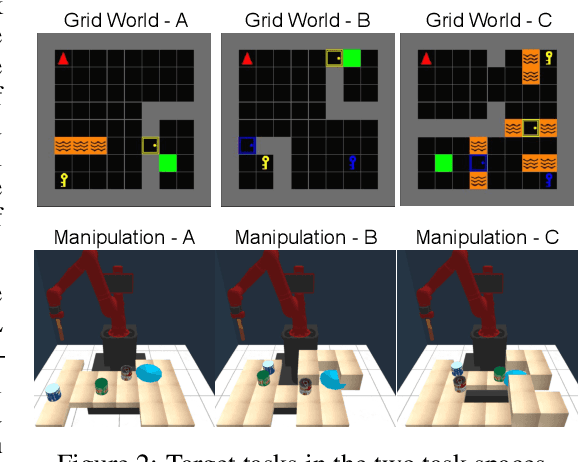
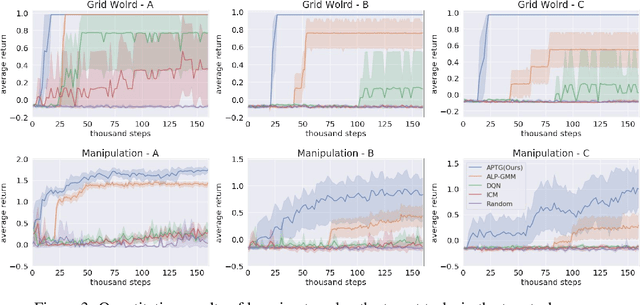
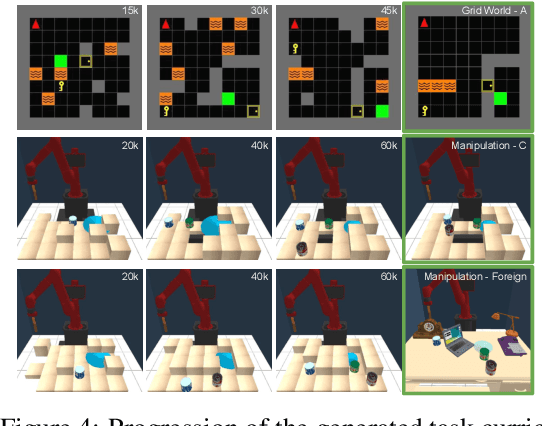
We introduce Adaptive Procedural Task Generation (APT-Gen), an approach for progressively generating a sequence of tasks as curricula to facilitate reinforcement learning in hard-exploration problems. At the heart of our approach, a task generator learns to create tasks via a black-box procedural generation module by adaptively sampling from the parameterized task space. To enable curriculum learning in the absence of a direct indicator of learning progress, the task generator is trained by balancing the agent's expected return in the generated tasks and their similarities to the target task. Through adversarial training, the similarity between the generated tasks and the target task is adaptively estimated by a task discriminator defined on the agent's behaviors. In this way, our approach can efficiently generate tasks of rich variations for target tasks of unknown parameterization or not covered by the predefined task space. Experiments demonstrate the effectiveness of our approach through quantitative and qualitative analysis in various scenarios.
Generative Sparse Detection Networks for 3D Single-shot Object Detection
Jun 22, 2020
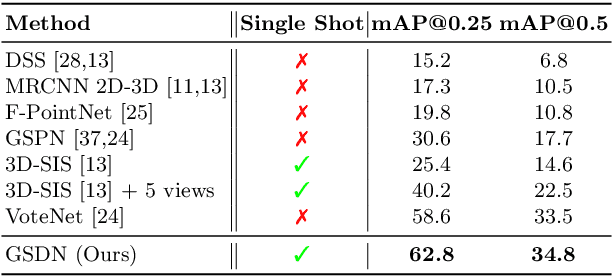
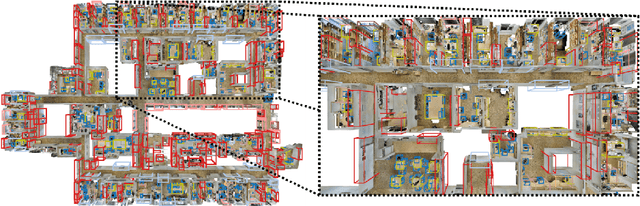

3D object detection has been widely studied due to its potential applicability to many promising areas such as robotics and augmented reality. Yet, the sparse nature of the 3D data poses unique challenges to this task. Most notably, the observable surface of the 3D point clouds is disjoint from the center of the instance to ground the bounding box prediction on. To this end, we propose Generative Sparse Detection Network (GSDN), a fully-convolutional single-shot sparse detection network that efficiently generates the support for object proposals. The key component of our model is a generative sparse tensor decoder, which uses a series of transposed convolutions and pruning layers to expand the support of sparse tensors while discarding unlikely object centers to maintain minimal runtime and memory footprint. GSDN can process unprecedentedly large-scale inputs with a single fully-convolutional feed-forward pass, thus does not require the heuristic post-processing stage that stitches results from sliding windows as other previous methods have. We validate our approach on three 3D indoor datasets including the large-scale 3D indoor reconstruction dataset where our method outperforms the state-of-the-art methods by a relative improvement of 7.14% while being 3.78 times faster than the best prior work.
Probabilistic Visual Navigation with Bidirectional Image Prediction
Mar 20, 2020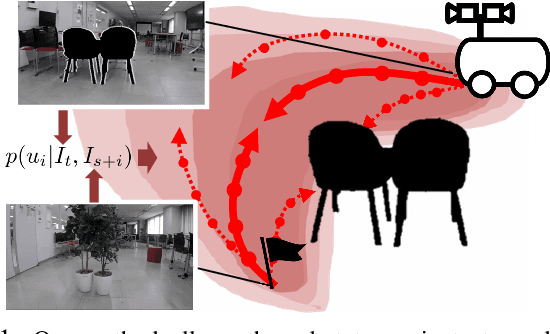
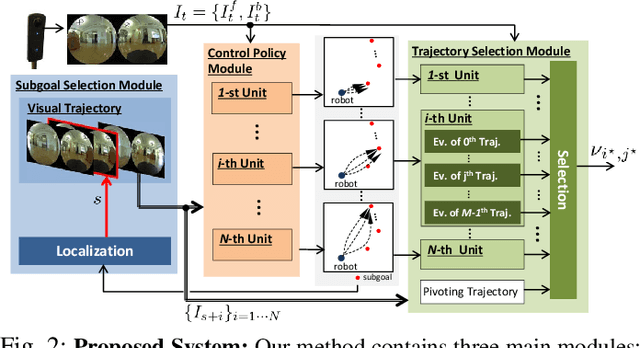
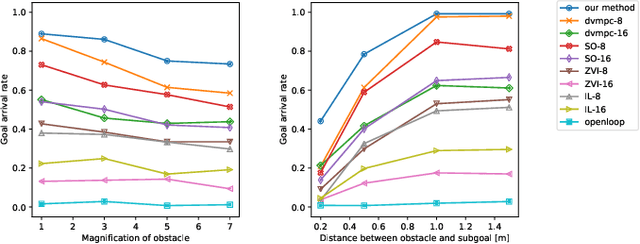
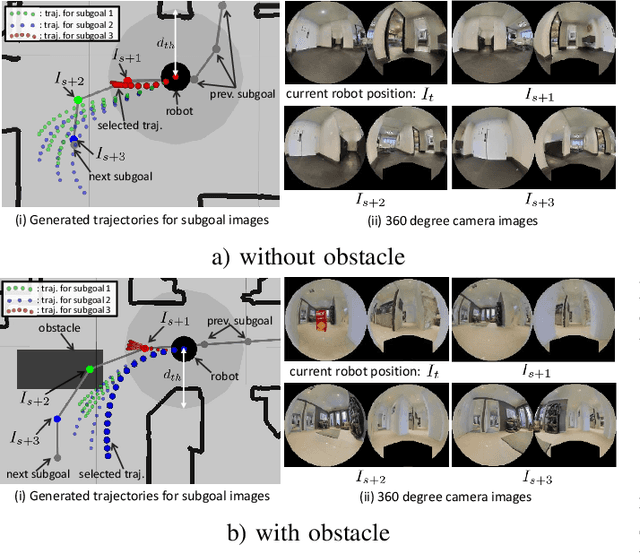
Humans can robustly follow a visual trajectory defined by a sequence of images (i.e. a video) regardless of substantial changes in the environment or the presence of obstacles. We aim at endowing similar visual navigation capabilities to mobile robots solely equipped with a RGB fisheye camera. We propose a novel probabilistic visual navigation system that learns to follow a sequence of images with bidirectional visual predictions conditioned on possible navigation velocities. By predicting bidirectionally (from start towards goal and vice versa) our method extends its predictive horizon enabling the robot to go around unseen large obstacles that are not visible in the video trajectory. Learning how to react to obstacles and potential risks in the visual field is achieved by imitating human teleoperators. Since the human teleoperation commands are diverse, we propose a probabilistic representation of trajectories that we can sample to find the safest path. Integrated into our navigation system, we present a novel localization approach that infers the current location of the robot based on the virtual predicted trajectories required to reach different images in the visual trajectory. We evaluate our navigation system quantitatively and qualitatively in multiple simulated and real environments and compare to state-of-the-art baselines.Our approach outperforms the most recent visual navigation methods with a large margin with regard to goal arrival rate, subgoal coverage rate, and success weighted by path length (SPL). Our method also generalizes to new robot embodiments never used during training.
JRMOT: A Real-Time 3D Multi-Object Tracker and a New Large-Scale Dataset
Mar 18, 2020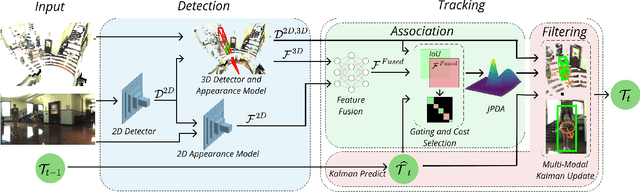
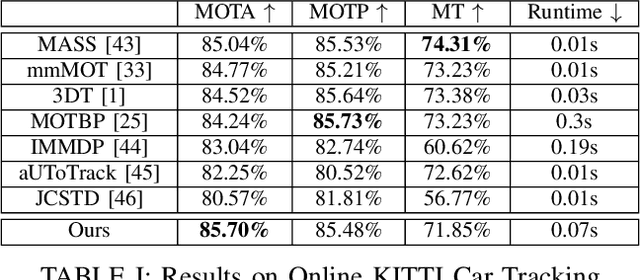
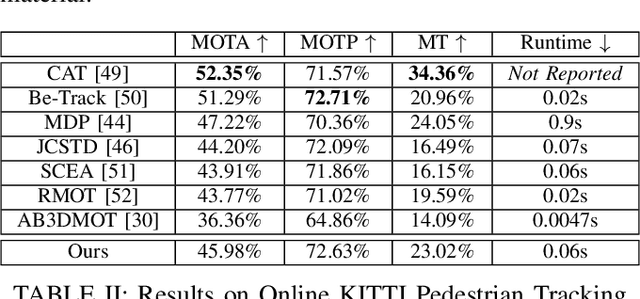
An autonomous navigating agent needs to perceive and track the motion of objects and other agents in its surroundings to achieve robust and safe motion planning and execution. While autonomous navigation requires a multi-object tracking (MOT) system to provide 3D information, most research has been done in 2D MOT from RGB videos. In this work we present JRMOT, a novel 3D MOT system that integrates information from 2D RGB images and 3D point clouds into a real-time performing framework. Our system leverages advancements in neural-network based re-identification as well as 2D and 3D detection and descriptors. We incorporate this into a joint probabilistic data-association framework within a multi-modal recursive Kalman architecture to achieve online, real-time 3D MOT. As part of our work, we release the JRDB dataset, a novel large scale 2D+3D dataset and benchmark annotated with over 2 million boxes and 3500 time consistent 2D+3D trajectories across 54 indoor and outdoor scenes. The dataset contains over 60 minutes of data including 360 degree cylindrical RGB video and 3D pointclouds. The presented 3D MOT system demonstrates state-of-the-art performance against competing methods on the popular 2D tracking KITTI benchmark and serves as a competitive 3D tracking baseline for our dataset and benchmark.
Learning to Generalize Across Long-Horizon Tasks from Human Demonstrations
Mar 13, 2020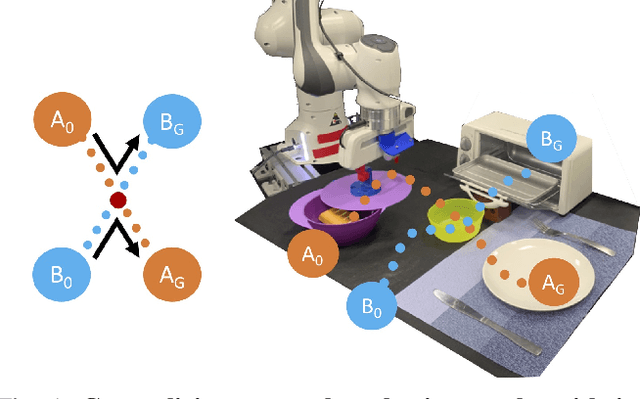
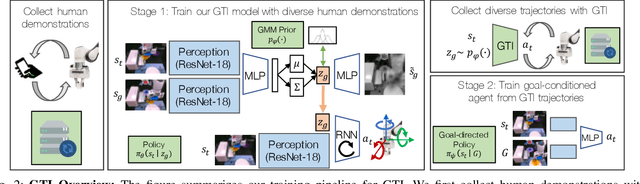

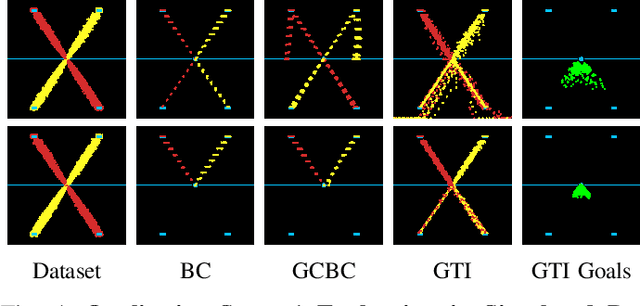
Imitation learning is an effective and safe technique to train robot policies in the real world because it does not depend on an expensive random exploration process. However, due to the lack of exploration, learning policies that generalize beyond the demonstrated behaviors is still an open challenge. We present a novel imitation learning framework to enable robots to 1) learn complex real world manipulation tasks efficiently from a small number of human demonstrations, and 2) synthesize new behaviors not contained in the collected demonstrations. Our key insight is that multi-task domains often present a latent structure, where demonstrated trajectories for different tasks intersect at common regions of the state space. We present Generalization Through Imitation (GTI), a two-stage offline imitation learning algorithm that exploits this intersecting structure to train goal-directed policies that generalize to unseen start and goal state combinations. In the first stage of GTI, we train a stochastic policy that leverages trajectory intersections to have the capacity to compose behaviors from different demonstration trajectories together. In the second stage of GTI, we collect a small set of rollouts from the unconditioned stochastic policy of the first stage, and train a goal-directed agent to generalize to novel start and goal configurations. We validate GTI in both simulated domains and a challenging long-horizon robotic manipulation domain in the real world. Additional results and videos are available at https://sites.google.com/view/gti2020/ .
Learning to Navigate Using Mid-Level Visual Priors
Dec 23, 2019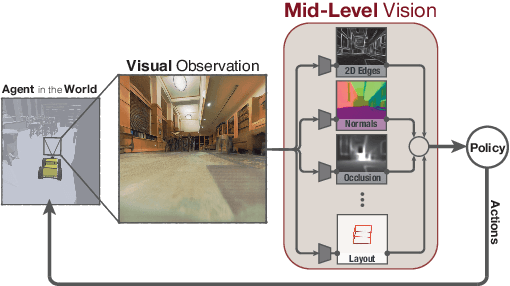
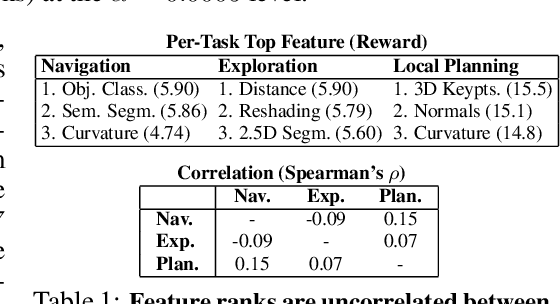
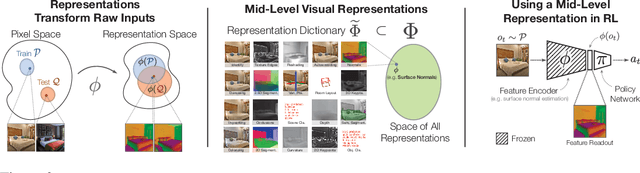

How much does having visual priors about the world (e.g. the fact that the world is 3D) assist in learning to perform downstream motor tasks (e.g. navigating a complex environment)? What are the consequences of not utilizing such visual priors in learning? We study these questions by integrating a generic perceptual skill set (a distance estimator, an edge detector, etc.) within a reinforcement learning framework (see Fig. 1). This skill set ("mid-level vision") provides the policy with a more processed state of the world compared to raw images. Our large-scale study demonstrates that using mid-level vision results in policies that learn faster, generalize better, and achieve higher final performance, when compared to learning from scratch and/or using state-of-the-art visual and non-visual representation learning methods. We show that conventional computer vision objectives are particularly effective in this regard and can be conveniently integrated into reinforcement learning frameworks. Finally, we found that no single visual representation was universally useful for all downstream tasks, hence we computationally derive a task-agnostic set of representations optimized to support arbitrary downstream tasks.