 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCalibAnyView: Beyond Single-View Camera Calibration in the Wild
May 14, 2026Camera calibration is a fundamental prerequisite for reliable geometric perception, yet classical approaches rely on controlled acquisition setups that are impractical for in-the-wild imagery. Recent learning-based methods have shown promising results for single-view calibration, but inherently neglect geometric consistency across multiple views. We introduce CalibAnyView, a unified formulation that supports an arbitrary number of input views ($N \geq 1$) by explicitly modeling cross-view geometric consistency. To facilitate this, we construct a large-scale multi-view video dataset covering diverse real-world scenarios, including multiple camera models, dynamic scenes, realistic motion trajectories, and heterogeneous lens distortions. Building on this dataset, we develop a multi-view transformer that predicts dense perspective fields, which are further integrated into a geometric optimization framework to jointly estimate camera intrinsics and gravity direction. Extensive experiments demonstrate that CalibAnyView consistently outperforms state-of-the-art methods, achieves strong robustness under single-view settings, and further improves with multi-view inference, providing a reliable foundation for downstream tasks such as 3D reconstruction and robotic perception in the wild.
A Probabilistic Framework for Hierarchical Goal Recognition
Apr 24, 2026Goal recognition aims to infer an agent's goal from observations of its behaviour. In realistic settings, recognition can benefit from exploiting hierarchical task structure and reasoning under uncertainty. Planning-based goal recognition has made substantial progress over the past decade, but to the best of our knowledge no existing approach jointly integrates hierarchical task structure with probabilistic inference. In this paper, we introduce the first planning-based probabilistic framework for hierarchical goal recognition over Hierarchical Task Networks (HTNs). We instantiate the framework by exploiting an HTN planner with a three-stage generative model for likelihood estimation, yielding posterior distributions over goal hypotheses. Empirical results show improved recognition performance over the existing HTN-based recognizer on HTN benchmarks. Overall, the framework lays a foundation for probabilistic goal recognition grounded in hierarchical planning structure, moving goal recognition toward more practical settings.
dinov3.seg: Open-Vocabulary Semantic Segmentation with DINOv3
Mar 19, 2026Open-Vocabulary Semantic Segmentation (OVSS) assigns pixel-level labels from an open set of text-defined categories, demanding reliable generalization to unseen classes at inference. Although modern vision-language models (VLMs) support strong open-vocabulary recognition, their representations learned through global contrastive objectives remain suboptimal for dense prediction, prompting many OVSS methods to depend on limited adaptation or refinement of image-text similarity maps. This, in turn, restricts spatial precision and robustness in complex, cluttered scenes. We introduce dinov3.seg, extending dinov3.txt into a dedicated framework for OVSS. Our contributions are four-fold. First, we design a task-specific architecture tailored to this backbone, systematically adapting established design principles from prior open-vocabulary segmentation work. Second, we jointly leverage text embeddings aligned with both the global [CLS] token and local patch-level visual features from ViT-based encoder, effectively combining semantic discrimination with fine-grained spatial locality. Third, unlike prior approaches that rely primarily on post hoc similarity refinement, we perform early refinement of visual representations prior to image-text interaction, followed by late refinement of the resulting image-text correlation features, enabling more accurate and robust dense predictions in cluttered scenes. Finally, we propose a high-resolution local-global inference strategy based on sliding-window aggregation, which preserves spatial detail while maintaining global context. We conduct extensive experiments on five widely adopted OVSS benchmarks to evaluate our approach. The results demonstrate its effectiveness and robustness, consistently outperforming current state-of-the-art methods.
VIEW2SPACE: Studying Multi-View Visual Reasoning from Sparse Observations
Mar 17, 2026Multi-view visual reasoning is essential for intelligent systems that must understand complex environments from sparse and discrete viewpoints, yet existing research has largely focused on single-image or temporally dense video settings. In real-world scenarios, reasoning across views requires integrating partial observations without explicit guidance, while collecting large-scale multi-view data with accurate geometric and semantic annotations remains challenging. To address this gap, we leverage physically grounded simulation to construct diverse, high-fidelity 3D scenes with precise per-view metadata, enabling scalable data generation that remains transferable to real-world settings. Based on this engine, we introduce VIEW2SPACE, a multi-dimensional benchmark for sparse multi-view reasoning, together with a scalable, disjoint training split supporting millions of grounded question-answer pairs. Using this benchmark, a comprehensive evaluation of state-of-the-art vision-language and spatial models reveals that multi-view reasoning remains largely unsolved, with most models performing only marginally above random guessing. We further investigate whether training can bridge this gap. Our proposed Grounded Chain-of-Thought with Visual Evidence substantially improves performance under moderate difficulty, and generalizes to real-world data, outperforming existing approaches in cross-dataset evaluation. We further conduct difficulty-aware scaling analyses across model size, data scale, reasoning depth, and visibility constraints, indicating that while geometric perception can benefit from scaling under sufficient visibility, deep compositional reasoning across sparse views remains a fundamental challenge.
JRDB-Pose3D: A Multi-person 3D Human Pose and Shape Estimation Dataset for Robotics
Feb 03, 2026Real-world scenes are inherently crowded. Hence, estimating 3D poses of all nearby humans, tracking their movements over time, and understanding their activities within social and environmental contexts are essential for many applications, such as autonomous driving, robot perception, robot navigation, and human-robot interaction. However, most existing 3D human pose estimation datasets primarily focus on single-person scenes or are collected in controlled laboratory environments, which restricts their relevance to real-world applications. To bridge this gap, we introduce JRDB-Pose3D, which captures multi-human indoor and outdoor environments from a mobile robotic platform. JRDB-Pose3D provides rich 3D human pose annotations for such complex and dynamic scenes, including SMPL-based pose annotations with consistent body-shape parameters and track IDs for each individual over time. JRDB-Pose3D contains, on average, 5-10 human poses per frame, with some scenes featuring up to 35 individuals simultaneously. The proposed dataset presents unique challenges, including frequent occlusions, truncated bodies, and out-of-frame body parts, which closely reflect real-world environments. Moreover, JRDB-Pose3D inherits all available annotations from the JRDB dataset, such as 2D pose, information about social grouping, activities, and interactions, full-scene semantic masks with consistent human- and object-level tracking, and detailed annotations for each individual, such as age, gender, and race, making it a holistic dataset for a wide range of downstream perception and human-centric understanding tasks.
MATA: A Trainable Hierarchical Automaton System for Multi-Agent Visual Reasoning
Jan 27, 2026Recent vision-language models have strong perceptual ability but their implicit reasoning is hard to explain and easily generates hallucinations on complex queries. Compositional methods improve interpretability, but most rely on a single agent or hand-crafted pipeline and cannot decide when to collaborate across complementary agents or compete among overlapping ones. We introduce MATA (Multi-Agent hierarchical Trainable Automaton), a multi-agent system presented as a hierarchical finite-state automaton for visual reasoning whose top-level transitions are chosen by a trainable hyper agent. Each agent corresponds to a state in the hyper automaton, and runs a small rule-based sub-automaton for reliable micro-control. All agents read and write a shared memory, yielding transparent execution history. To supervise the hyper agent's transition policy, we build transition-trajectory trees and transform to memory-to-next-state pairs, forming the MATA-SFT-90K dataset for supervised finetuning (SFT). The finetuned LLM as the transition policy understands the query and the capacity of agents, and it can efficiently choose the optimal agent to solve the task. Across multiple visual reasoning benchmarks, MATA achieves the state-of-the-art results compared with monolithic and compositional baselines. The code and dataset are available at https://github.com/ControlNet/MATA.
ASAP-Textured Gaussians: Enhancing Textured Gaussians with Adaptive Sampling and Anisotropic Parameterization
Dec 16, 2025



Recent advances have equipped 3D Gaussian Splatting with texture parameterizations to capture spatially varying attributes, improving the performance of both appearance modeling and downstream tasks. However, the added texture parameters introduce significant memory efficiency challenges. Rather than proposing new texture formulations, we take a step back to examine the characteristics of existing textured Gaussian methods and identify two key limitations in common: (1) Textures are typically defined in canonical space, leading to inefficient sampling that wastes textures' capacity on low-contribution regions; and (2) texture parameterization is uniformly assigned across all Gaussians, regardless of their visual complexity, resulting in over-parameterization. In this work, we address these issues through two simple yet effective strategies: adaptive sampling based on the Gaussian density distribution and error-driven anisotropic parameterization that allocates texture resources according to rendering error. Our proposed ASAP Textured Gaussians, short for Adaptive Sampling and Anisotropic Parameterization, significantly improve the quality efficiency tradeoff, achieving high-fidelity rendering with far fewer texture parameters.
A Multi-Modal Neuro-Symbolic Approach for Spatial Reasoning-Based Visual Grounding in Robotics
Oct 30, 2025
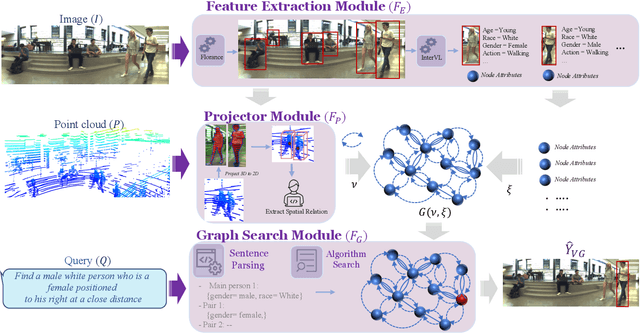


Visual reasoning, particularly spatial reasoning, is a challenging cognitive task that requires understanding object relationships and their interactions within complex environments, especially in robotics domain. Existing vision_language models (VLMs) excel at perception tasks but struggle with fine-grained spatial reasoning due to their implicit, correlation-driven reasoning and reliance solely on images. We propose a novel neuro_symbolic framework that integrates both panoramic-image and 3D point cloud information, combining neural perception with symbolic reasoning to explicitly model spatial and logical relationships. Our framework consists of a perception module for detecting entities and extracting attributes, and a reasoning module that constructs a structured scene graph to support precise, interpretable queries. Evaluated on the JRDB-Reasoning dataset, our approach demonstrates superior performance and reliability in crowded, human_built environments while maintaining a lightweight design suitable for robotics and embodied AI applications.
Explain Before You Answer: A Survey on Compositional Visual Reasoning
Aug 24, 2025



Compositional visual reasoning has emerged as a key research frontier in multimodal AI, aiming to endow machines with the human-like ability to decompose visual scenes, ground intermediate concepts, and perform multi-step logical inference. While early surveys focus on monolithic vision-language models or general multimodal reasoning, a dedicated synthesis of the rapidly expanding compositional visual reasoning literature is still missing. We fill this gap with a comprehensive survey spanning 2023 to 2025 that systematically reviews 260+ papers from top venues (CVPR, ICCV, NeurIPS, ICML, ACL, etc.). We first formalize core definitions and describe why compositional approaches offer advantages in cognitive alignment, semantic fidelity, robustness, interpretability, and data efficiency. Next, we trace a five-stage paradigm shift: from prompt-enhanced language-centric pipelines, through tool-enhanced LLMs and tool-enhanced VLMs, to recently minted chain-of-thought reasoning and unified agentic VLMs, highlighting their architectural designs, strengths, and limitations. We then catalog 60+ benchmarks and corresponding metrics that probe compositional visual reasoning along dimensions such as grounding accuracy, chain-of-thought faithfulness, and high-resolution perception. Drawing on these analyses, we distill key insights, identify open challenges (e.g., limitations of LLM-based reasoning, hallucination, a bias toward deductive reasoning, scalable supervision, tool integration, and benchmark limitations), and outline future directions, including world-model integration, human-AI collaborative reasoning, and richer evaluation protocols. By offering a unified taxonomy, historical roadmap, and critical outlook, this survey aims to serve as a foundational reference and inspire the next generation of compositional visual reasoning research.
JRDB-Reasoning: A Difficulty-Graded Benchmark for Visual Reasoning in Robotics
Aug 14, 2025Recent advances in Vision-Language Models (VLMs) and large language models (LLMs) have greatly enhanced visual reasoning, a key capability for embodied AI agents like robots. However, existing visual reasoning benchmarks often suffer from several limitations: they lack a clear definition of reasoning complexity, offer have no control to generate questions over varying difficulty and task customization, and fail to provide structured, step-by-step reasoning annotations (workflows). To bridge these gaps, we formalize reasoning complexity, introduce an adaptive query engine that generates customizable questions of varying complexity with detailed intermediate annotations, and extend the JRDB dataset with human-object interaction and geometric relationship annotations to create JRDB-Reasoning, a benchmark tailored for visual reasoning in human-crowded environments. Our engine and benchmark enable fine-grained evaluation of visual reasoning frameworks and dynamic assessment of visual-language models across reasoning levels.