 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Mean of Multi-Object Trajectories
Apr 29, 2025



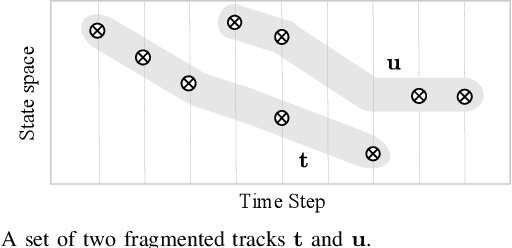
This paper introduces the concept of a mean for trajectories and multi-object trajectories--sets or multi-sets of trajectories--along with algorithms for computing them. Specifically, we use the Fr\'{e}chet mean, and metrics based on the optimal sub-pattern assignment (OSPA) construct, to extend the notion of average from vectors to trajectories and multi-object trajectories. Further, we develop efficient algorithms to compute these means using greedy search and Gibbs sampling. Using distributed multi-object tracking as an application, we demonstrate that the Fr\'{e}chet mean approach to multi-object trajectory consensus significantly outperforms state-of-the-art distributed multi-object tracking methods.
An Overview of Multi-Object Estimation via Labeled Random Finite Set
Sep 27, 2024



This article presents the Labeled Random Finite Set (LRFS) framework for multi-object systems-systems in which the number of objects and their states are unknown and vary randomly with time. In particular, we focus on state and trajectory estimation via a multi-object State Space Model (SSM) that admits principled tractable multi-object tracking filters/smoothers. Unlike the single-object counterpart, a time sequence of states does not necessarily represent the trajectory of a multi-object system. The LRFS formulation enables a time sequence of multi-object states to represent the multi-object trajectory that accommodates trajectory crossings and fragmentations. We present the basics of LRFS, covering a suite of commonly used models and mathematical apparatus (including the latest results not published elsewhere). Building on this, we outline the fundamentals of multi-object state space modeling and estimation using LRFS, which formally address object identities/trajectories, ancestries for spawning objects, and characterization of the uncertainty on the ensemble of objects (and their trajectories). Numerical solutions to multi-object SSM problems are inherently far more challenging than those in standard SSM. To bridge the gap between theory and practice, we discuss state-of-the-art implementations that address key computational bottlenecks in the number of objects, measurements, sensors, and scans.
Track Initialization and Re-Identification for~3D Multi-View Multi-Object Tracking
May 28, 2024



We propose a 3D multi-object tracking (MOT) solution using only 2D detections from monocular cameras, which automatically initiates/terminates tracks as well as resolves track appearance-reappearance and occlusions. Moreover, this approach does not require detector retraining when cameras are reconfigured but only the camera matrices of reconfigured cameras need to be updated. Our approach is based on a Bayesian multi-object formulation that integrates track initiation/termination, re-identification, occlusion handling, and data association into a single Bayes filtering recursion. However, the exact filter that utilizes all these functionalities is numerically intractable due to the exponentially growing number of terms in the (multi-object) filtering density, while existing approximations trade-off some of these functionalities for speed. To this end, we develop a more efficient approximation suitable for online MOT by incorporating object features and kinematics into the measurement model, which improves data association and subsequently reduces the number of terms. Specifically, we exploit the 2D detections and extracted features from multiple cameras to provide a better approximation of the multi-object filtering density to realize the track initiation/termination and re-identification functionalities. Further, incorporating a tractable geometric occlusion model based on 2D projections of 3D objects on the camera planes realizes the occlusion handling functionality of the filter. Evaluation of the proposed solution on challenging datasets demonstrates significant improvements and robustness when camera configurations change on-the-fly, compared to existing multi-view MOT solutions. The source code is publicly available at https://github.com/linh-gist/mv-glmb-ab.
Linear Complexity Gibbs Sampling for Generalized Labeled Multi-Bernoulli Filtering
Nov 29, 2022



Generalized Labeled Multi-Bernoulli (GLMB) densities arise in a host of multi-object system applications analogous to Gaussians in single-object filtering. However, computing the GLMB filtering density requires solving NP-hard problems. To alleviate this computational bottleneck, we develop a linear complexity Gibbs sampling framework for GLMB density computation. Specifically, we propose a tempered Gibbs sampler that exploits the structure of the GLMB filtering density to achieve an $\mathcal{O}(T(P+M))$ complexity, where $T$ is the number of iterations of the algorithm, $P$ and $M$ are the number hypothesized objects and measurements. This innovation enables an $\mathcal{O}(T(P+M+\log(T))+PM)$ complexity implementation of the GLMB filter. Convergence of the proposed Gibbs sampler is established and numerical studies are presented to validate the proposed GLMB filter implementation.
Tracking Cells and their Lineages via Labeled Random Finite Sets
Apr 22, 2021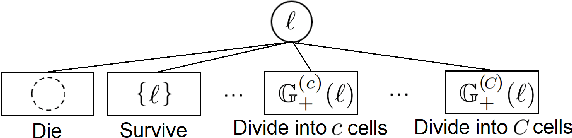
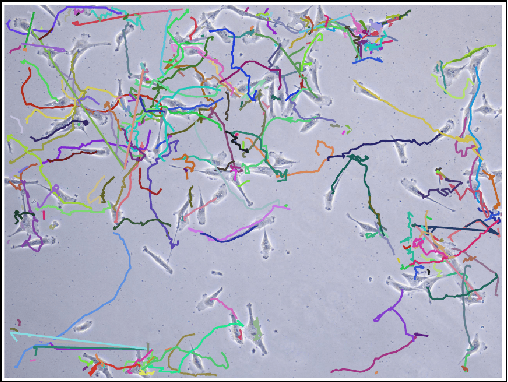
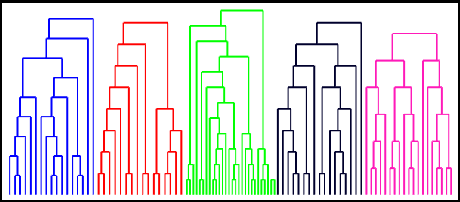
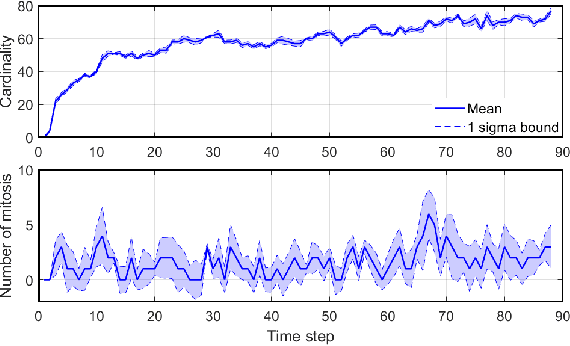
Determining the trajectories of cells and their lineages or ancestries in live-cell experiments are fundamental to the understanding of how cells behave and divide. This paper proposes novel online algorithms for jointly tracking and resolving lineages of an unknown and time-varying number of cells from time-lapse video data. Our approach involves modeling the cell ensemble as a labeled random finite set with labels representing cell identities and lineages. A spawning model is developed to take into account cell lineages and changes in cell appearance prior to division. We then derive analytic filters to propagate multi-object distributions that contain information on the current cell ensemble including their lineages. We also develop numerical implementations of the resulting multi-object filters. Experiments using simulation, synthetic cell migration video, and real time-lapse sequence, are presented to demonstrate the capability of the solutions.
Distributed Multi-object Tracking under Limited Field of View Sensors
Dec 23, 2020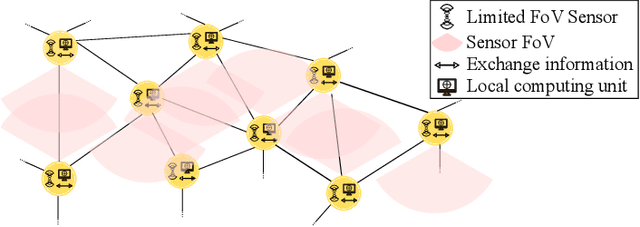
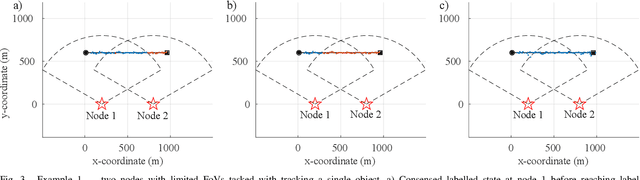
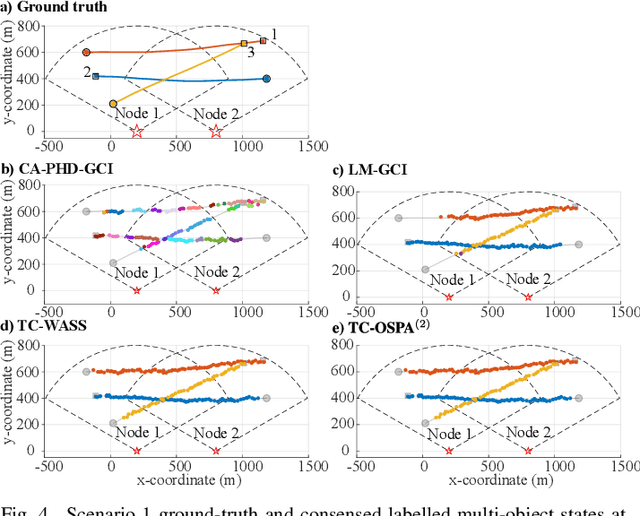
We consider the challenging problem of tracking multiple objects using a distributed network of sensors. In the pragmatic settings of a limited field of view (FoV) sensors, computing and communication resources of nodes, we develop a novel distributed multi-target algorithm that fuses local multi-object states instead of local multi-object densities. This algorithm uses a novel label consensus approach that reduces label inconsistency, caused by movements of objects from one node's limited FoV to another. To accomplish this, we formalise the concept of label consistency and determine a sufficient condition to achieve it. The proposed algorithm is i) fast and requires significantly less processing time than fusion methods using multi-object filtering densities, and ii) achieves better tracking accuracy by considering tracking errors measured by the Optimal Sub-Pattern Assignment (OSPA) metric over several scans rather than a single scan. Numerical experiments demonstrate the real-time capability of our proposed solution, in computational efficiency and accuracy compared to state-of-the-art solutions in challenging scenarios.
How Trustworthy are the Existing Performance Evaluations for Basic Vision Tasks?
Aug 08, 2020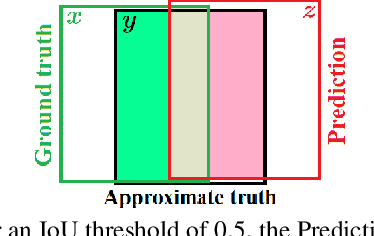
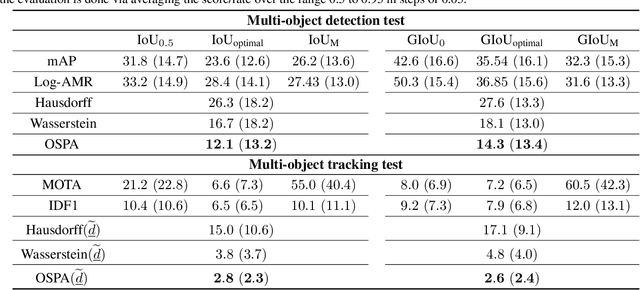
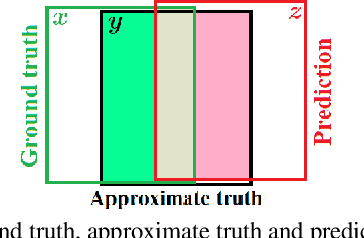
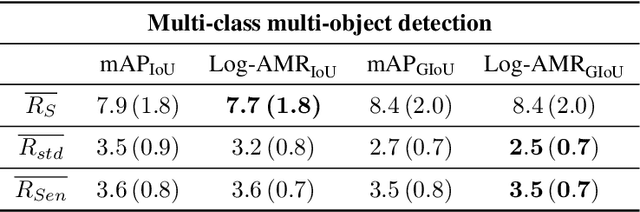
Performance evaluation is indispensable to the advancement of machine vision, yet its consistency and rigour have not received proportionate attention. This paper examines performance evaluation criteria for basic vision tasks namely, object detection, instance-level segmentation and multi-object tracking. Specifically, we advocate the use of criteria that are (i) consistent with mathematical requirements such as the metric properties, (ii) contextually meaningful in sanity tests, and (iii) robust to hyper-parameters for reliability. We show that many widely used performance criteria do not fulfill these requirements. Moreover, we explore alternative criteria for detection, segmentation, and tracking, using metrics for sets of shapes, and assess them against these requirements.
Multi-Objective Multi-Agent Planning for Jointly Discovering and Tracking Mobile Object
Nov 22, 2019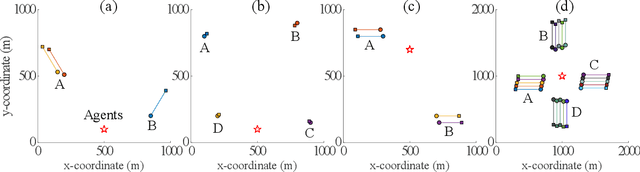
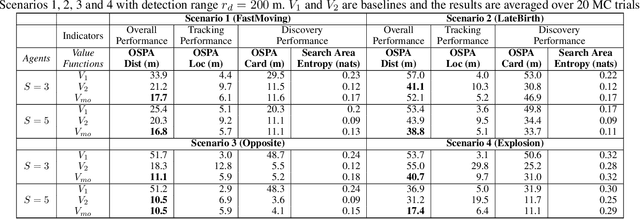
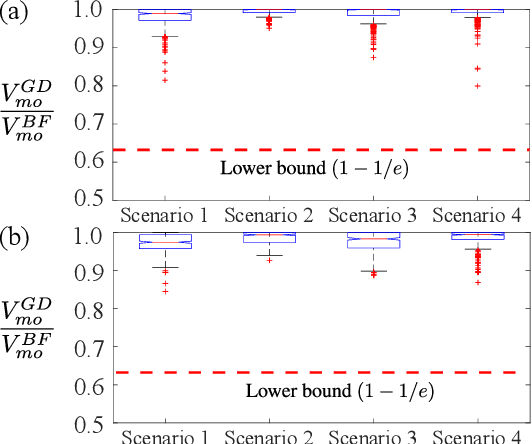
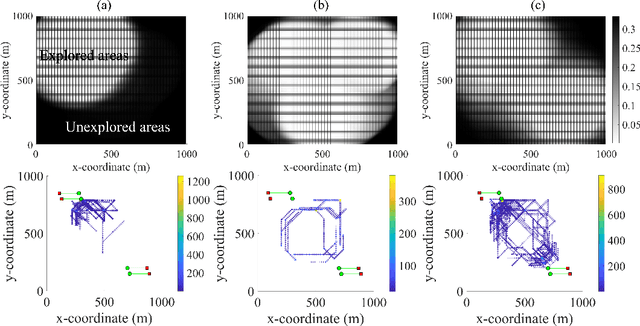
We consider the challenging problem of online planning for a team of agents to autonomously search and track a time-varying number of mobile objects under the practical constraint of detection range limited onboard sensors. A standard POMDP with a value function that either encourages discovery or accurate tracking of mobile objects is inadequate to simultaneously meet the conflicting goals of searching for undiscovered mobile objects whilst keeping track of discovered objects. The planning problem is further complicated by misdetections or false detections of objects caused by range limited sensors and noise inherent to sensor measurements. We formulate a novel multi-objective POMDP based on information theoretic criteria, and an online multi-object tracking filter for the problem. Since controlling multi-agent is a well known combinatorial optimization problem, assigning control actions to agents necessitates a greedy algorithm. We prove that our proposed multi-objective value function is a monotone submodular set function; consequently, the greedy algorithm can achieve a (1-1/e) approximation for maximizing the submodular multi-objective function.
Model-Based Multiple Instance Learning
Aug 13, 2017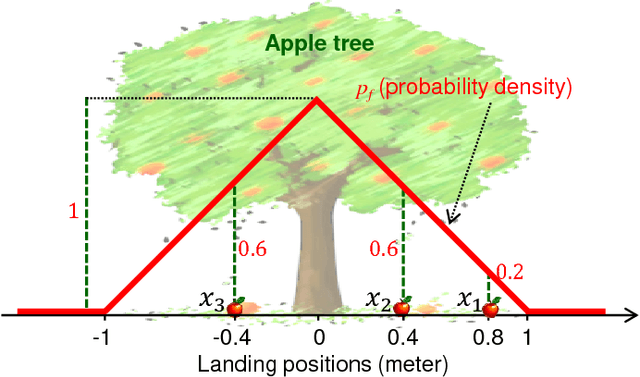
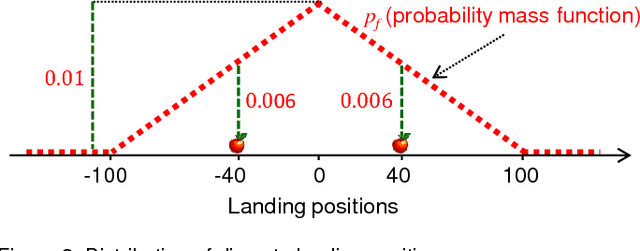
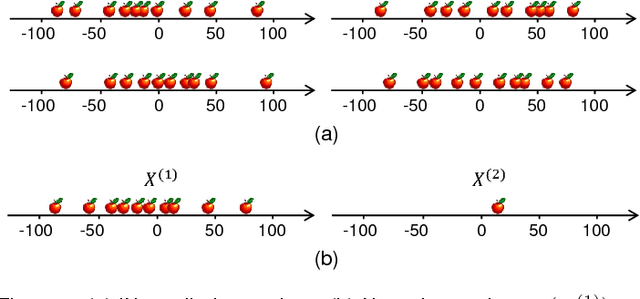
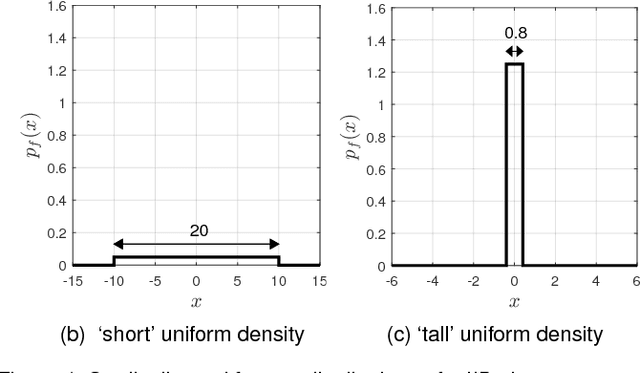
While Multiple Instance (MI) data are point patterns -- sets or multi-sets of unordered points -- appropriate statistical point pattern models have not been used in MI learning. This article proposes a framework for model-based MI learning using point process theory. Likelihood functions for point pattern data derived from point process theory enable principled yet conceptually transparent extensions of learning tasks, such as classification, novelty detection and clustering, to point pattern data. Furthermore, tractable point pattern models as well as solutions for learning and decision making from point pattern data are developed.
Online Visual Multi-Object Tracking via Labeled Random Finite Set Filtering
Aug 04, 2017
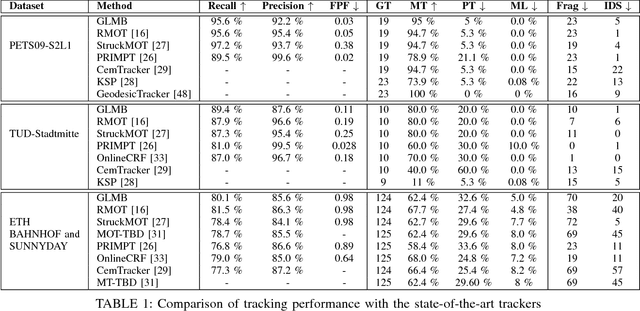
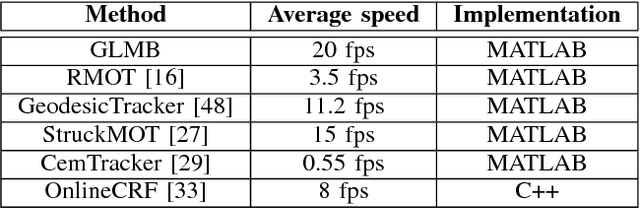
This paper proposes an online visual multi-object tracking algorithm using a top-down Bayesian formulation that seamlessly integrates state estimation, track management, clutter rejection, occlusion and mis-detection handling into a single recursion. This is achieved by modeling the multi-object state as labeled random finite set and using the Bayes recursion to propagate the multi-object filtering density forward in time. The proposed filter updates tracks with detections but switches to image data when mis-detection occurs, thereby exploiting the efficiency of detection data and the accuracy of image data. Furthermore the labeled random finite set framework enables the incorporation of prior knowledge that mis-detections of long tracks which occur in the middle of the scene are likely to be due to occlusions. Such prior knowledge can be exploited to improve occlusion handling, especially long occlusions that can lead to premature track termination in on-line multi-object tracking. Tracking performance are compared to state-of-the-art algorithms on well-known benchmark video datasets.