 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnytime Integrated Task and Motion Policies for Stochastic Environments
Apr 30, 2019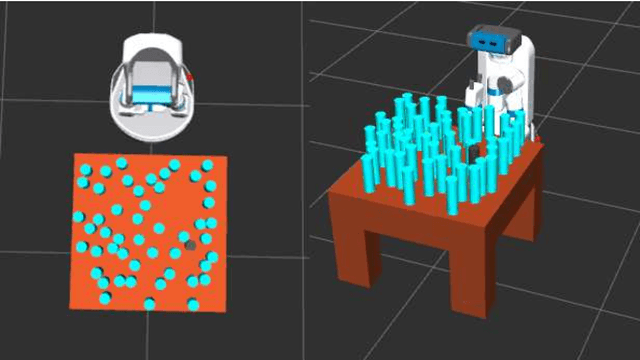

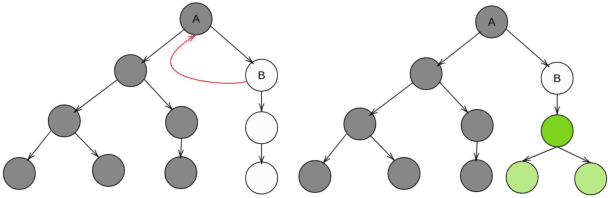
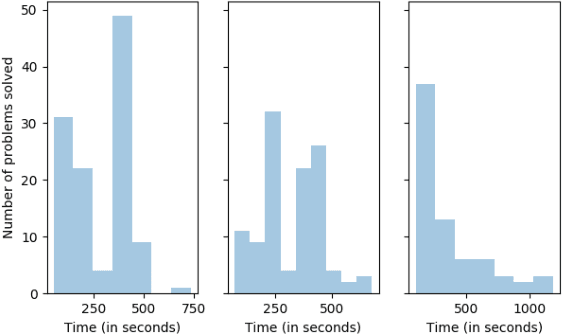
In order to solve complex, long-horizon tasks, intelligent robots need to be able to carry out high-level, abstract planning and reasoning in conjunction with motion planning. However, abstract models are typically lossy and plans or policies computed using them are often unexecutable in practice. These problems are aggravated in more realistic situations with stochastic dynamics, where the robot needs to reason about, and plan for multiple possible contingencies. We present a new approach for integrated task and motion planning in such settings. In contrast to prior work in this direction, we show that our approach can effectively compute integrated task and motion policies with branching structure encoding agent behaviors for various possible contingencies. We prove that our algorithm is probabilistically complete and can compute feasible solution policies in an anytime fashion so that the probability of encountering an unresolved contingency decreases over time. Empirical results on a set of challenging problems show the utility and scope of our methods.
Few Shot Speaker Recognition using Deep Neural Networks
Apr 17, 2019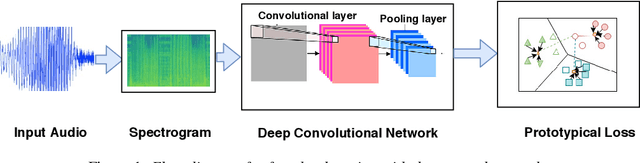
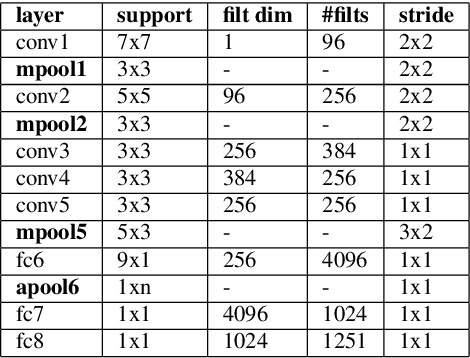

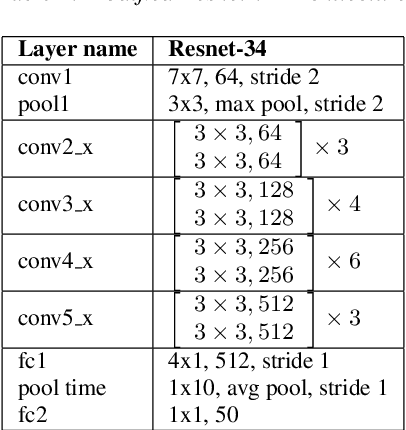
The recent advances in deep learning are mostly driven by availability of large amount of training data. However, availability of such data is not always possible for specific tasks such as speaker recognition where collection of large amount of data is not possible in practical scenarios. Therefore, in this paper, we propose to identify speakers by learning from only a few training examples. To achieve this, we use a deep neural network with prototypical loss where the input to the network is a spectrogram. For output, we project the class feature vectors into a common embedding space, followed by classification. Further, we show the effectiveness of capsule net in a few shot learning setting. To this end, we utilize an auto-encoder to learn generalized feature embeddings from class-specific embeddings obtained from capsule network. We provide exhaustive experiments on publicly available datasets and competitive baselines, demonstrating the superiority and generalization ability of the proposed few shot learning pipelines.
An Online Learning Approach for Dengue Fever Classification
Apr 17, 2019



This paper introduces a novel approach for dengue fever classification based on online learning paradigms. The proposed approach is suitable for practical implementation as it enables learning using only a few training samples. With time, the proposed approach is capable of learning incrementally from the data collected without need for retraining the model or redeployment of the prediction engine. Additionally, we also provide a comprehensive evaluation of machine learning methods for prediction of dengue fever. The input to the proposed pipeline comprises of recorded patient symptoms and diagnostic investigations. Offline classifier models have been employed to obtain baseline scores to establish that the feature set is optimal for classification of dengue. The primary benefit of the online detection model presented in the paper is that it has been established to effectively identify patients with high likelihood of dengue disease, and experiments on scalability in terms of number of training and test samples validate the use of the proposed model.
Learning Critical Regions for Robot Planning using Convolutional Neural Networks
Apr 15, 2019

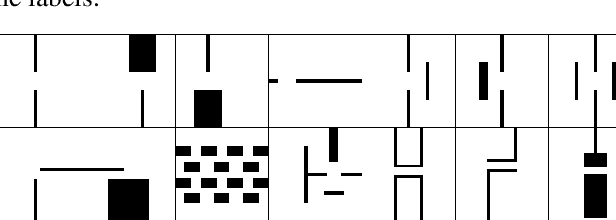

In this paper, we present a new approach to learning for motion planning (MP) where critical regions of an environment with low probability measure are learned from a given set of motion plans and used to improve performance on new problem instances. We show that convolutional neural networks (CNN) can be used to identify critical regions for motion planning problems. We also introduce a new sampling-based motion planner, Learn and Link. Our planner leverages critical region locations identified by our CNN to overcome the limitations of uniform sampling, while still maintaining guarantees of correctness inherent to sampling-based algorithms. We evaluate Learn and Link against planners from the Open Motion Planning Library (OMPL) using an extensive suite of experiments on challenging navigation planning problems. We show that our approach requires far less planning time than the existing sampling-based planners.
DeepPoint3D: Learning Discriminative Local Descriptors using Deep Metric Learning on 3D Point Clouds
Mar 27, 2019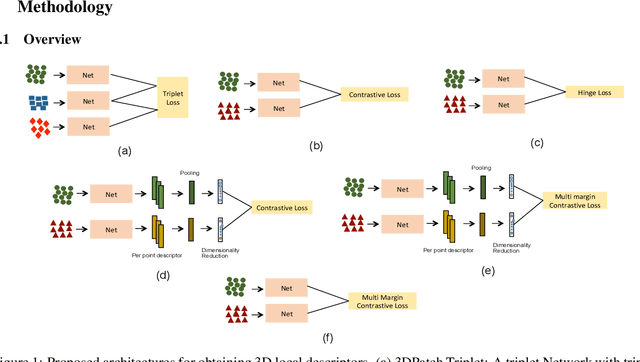
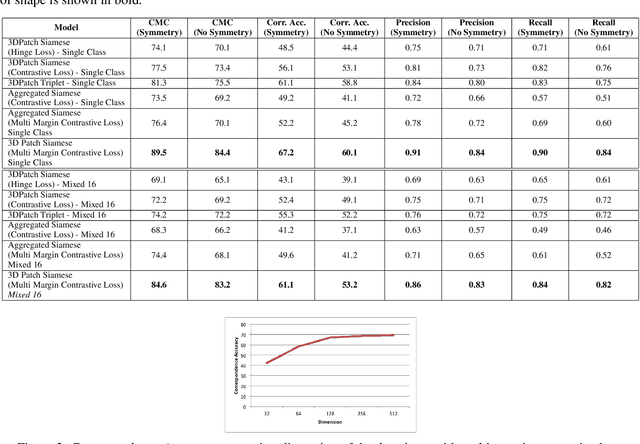

Learning local descriptors is an important problem in computer vision. While there are many techniques for learning local patch descriptors for 2D images, recently efforts have been made for learning local descriptors for 3D points. The recent progress towards solving this problem in 3D leverages the strong feature representation capability of image based convolutional neural networks by utilizing RGB-D or multi-view representations. However, in this paper, we propose to learn 3D local descriptors by directly processing unstructured 3D point clouds without needing any intermediate representation. The method constitutes a deep network for learning permutation invariant representation of 3D points. To learn the local descriptors, we use a multi-margin contrastive loss which discriminates between similar and dissimilar points on a surface while also leveraging the extent of dissimilarity among the negative samples at the time of training. With comprehensive evaluation against strong baselines, we show that the proposed method outperforms state-of-the-art methods for matching points in 3D point clouds. Further, we demonstrate the effectiveness of the proposed method on various applications achieving state-of-the-art results.
Learning 2D to 3D Lifting for Object Detection in 3D for Autonomous Vehicles
Mar 27, 2019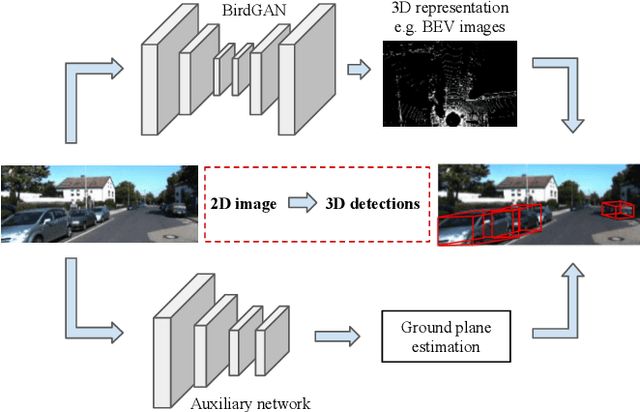
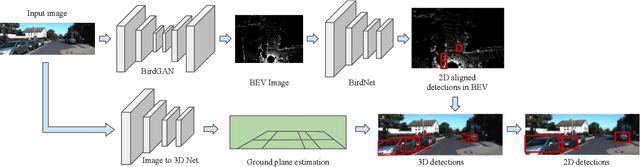
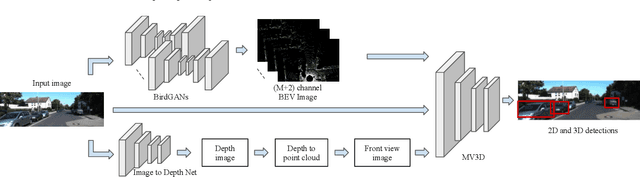
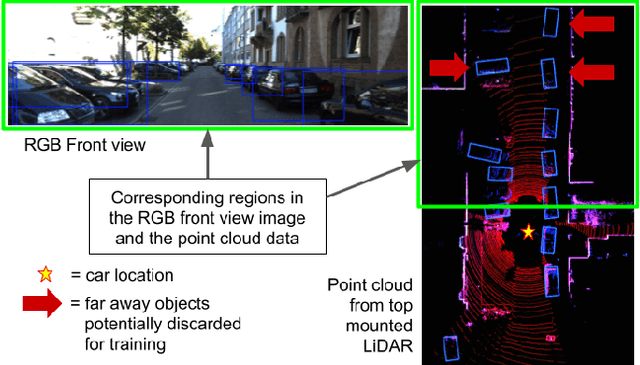
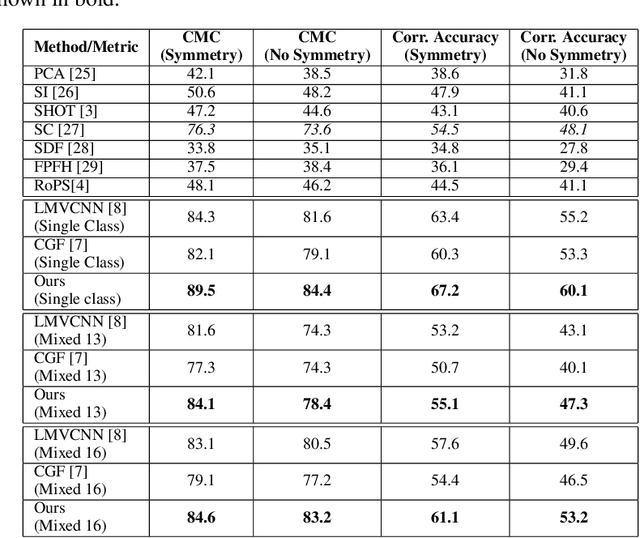
We address the problem of 3D object detection from 2D monocular images in autonomous driving scenarios. We propose to lift the 2D images to 3D representations using learned neural networks and leverage existing networks working directly on 3D to perform 3D object detection and localization. We show that, with carefully designed training mechanism and automatically selected minimally noisy data, such a method is not only feasible, but gives higher results than many methods working on actual 3D inputs acquired from physical sensors. On the challenging KITTI benchmark, we show that our 2D to 3D lifted method outperforms many recent competitive 3D networks while significantly outperforming previous state of the art for 3D detection from monocular images. We also show that a late fusion of the output of the network trained on generated 3D images, with that trained on real 3D images, improves performance. We find the results very interesting and argue that such a method could serve as a highly reliable backup in case of malfunction of expensive 3D sensors, if not potentially making them redundant, at least in the case of low human injury risk autonomous navigation scenarios like warehouse automation.
Why Couldn't You do that? Explaining Unsolvability of Classical Planning Problems in the Presence of Plan Advice
Mar 19, 2019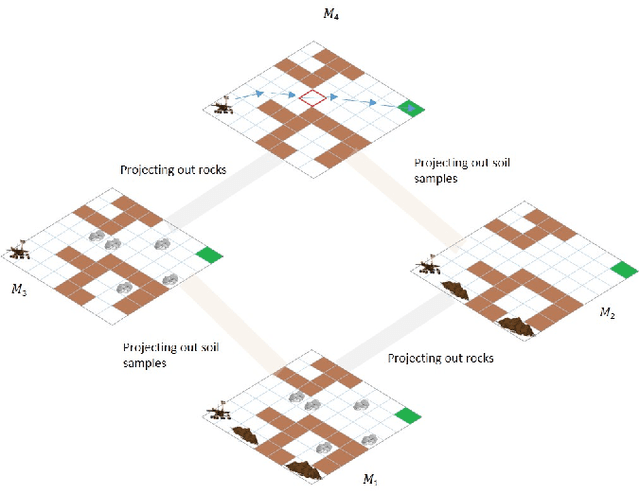

Explainable planning is widely accepted as a prerequisite for autonomous agents to successfully work with humans. While there has been a lot of research on generating explanations of solutions to planning problems, explaining the absence of solutions remains an open and under-studied problem, even though such situations can be the hardest to understand or debug. In this paper, we show that hierarchical abstractions can be used to efficiently generate reasons for unsolvability of planning problems. In contrast to related work on computing certificates of unsolvability, we show that these methods can generate compact, human-understandable reasons for unsolvability. Empirical analysis and user studies show the validity of our methods as well as their computational efficacy on a number of benchmark planning domains.
A Unified Framework for Planning in Adversarial and Cooperative Environments
Jul 26, 2018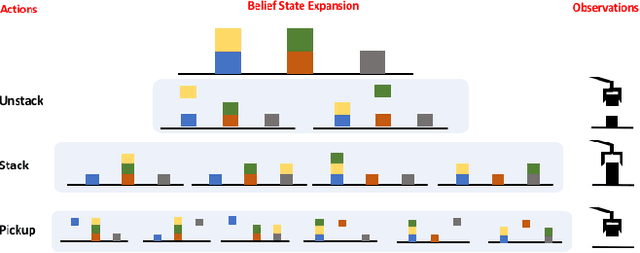
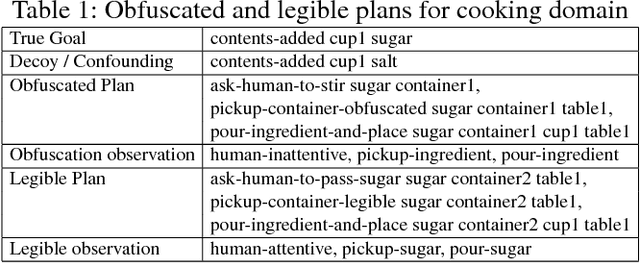

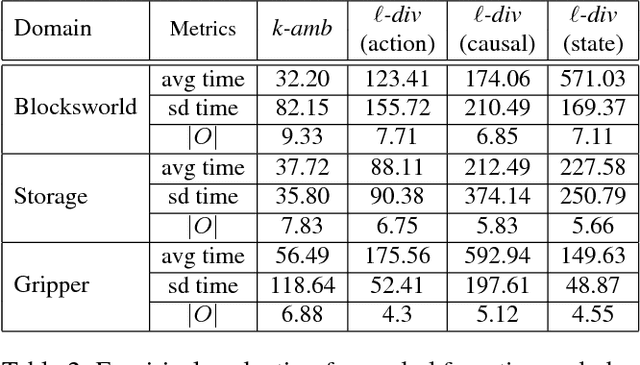
Users of AI systems may rely upon them to produce plans for achieving desired objectives. Such AI systems should be able to compute obfuscated plans whose execution in adversarial situations protects privacy, as well as legible plans which are easy for team members to understand in cooperative situations. We develop a unified framework that addresses these dual problems by computing plans with a desired level of comprehensibility from the point of view of a partially informed observer. For adversarial settings, our approach produces obfuscated plans with observations that are consistent with at least k goals from a set of decoy goals. By slightly varying our framework, we present an approach for goal legibility in cooperative settings which produces plans that achieve a goal while being consistent with at most j goals from a set of confounding goals. In addition, we show how the observability of the observer can be controlled to either obfuscate or clarify the next actions in a plan when the goal is known to the observer. We present theoretical results on the complexity analysis of our problems. We demonstrate the execution of obfuscated and legible plans in a cooking domain using a physical robot Fetch. We also provide an empirical evaluation to show the feasibility and usefulness of our approaches using IPC domains.
Learning Generalized Reactive Policies using Deep Neural Networks
Jul 25, 2018
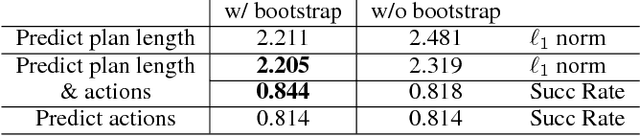
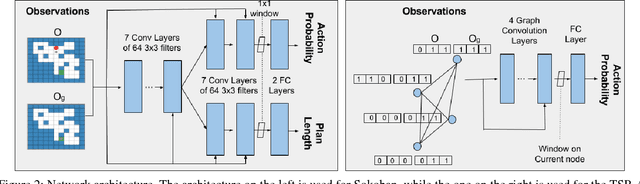

We present a new approach to learning for planning, where knowledge acquired while solving a given set of planning problems is used to plan faster in related, but new problem instances. We show that a deep neural network can be used to learn and represent a \emph{generalized reactive policy} (GRP) that maps a problem instance and a state to an action, and that the learned GRPs efficiently solve large classes of challenging problem instances. In contrast to prior efforts in this direction, our approach significantly reduces the dependence of learning on handcrafted domain knowledge or feature selection. Instead, the GRP is trained from scratch using a set of successful execution traces. We show that our approach can also be used to automatically learn a heuristic function that can be used in directed search algorithms. We evaluate our approach using an extensive suite of experiments on two challenging planning problem domains and show that our approach facilitates learning complex decision making policies and powerful heuristic functions with minimal human input. Videos of our results are available at goo.gl/Hpy4e3.
Discrete-Continuous Mixtures in Probabilistic Programming: Generalized Semantics and Inference Algorithms
Jun 08, 2018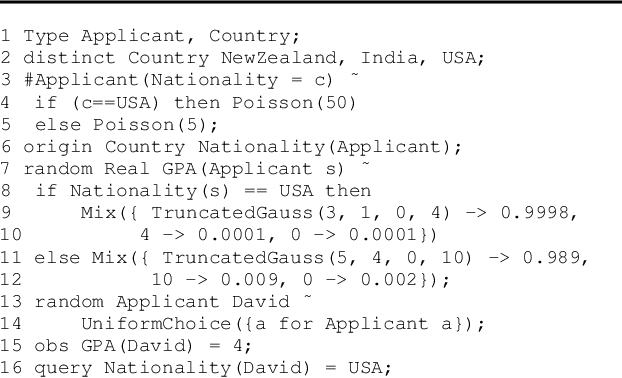

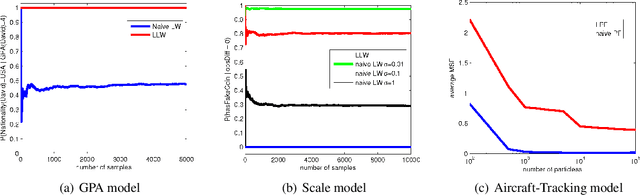

Despite the recent successes of probabilistic programming languages (PPLs) in AI applications, PPLs offer only limited support for random variables whose distributions combine discrete and continuous elements. We develop the notion of measure-theoretic Bayesian networks (MTBNs) and use it to provide more general semantics for PPLs with arbitrarily many random variables defined over arbitrary measure spaces. We develop two new general sampling algorithms that are provably correct under the MTBN framework: the lexicographic likelihood weighting (LLW) for general MTBNs and the lexicographic particle filter (LPF), a specialized algorithm for state-space models. We further integrate MTBNs into a widely used PPL system, BLOG, and verify the effectiveness of the new inference algorithms through representative examples.