 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobSurv: Vector Quantization-Based Multi-Modal Learning for Robust Cancer Survival Prediction
May 05, 2025



Cancer survival prediction using multi-modal medical imaging presents a critical challenge in oncology, mainly due to the vulnerability of deep learning models to noise and protocol variations across imaging centers. Current approaches struggle to extract consistent features from heterogeneous CT and PET images, limiting their clinical applicability. We address these challenges by introducing RobSurv, a robust deep-learning framework that leverages vector quantization for resilient multi-modal feature learning. The key innovation of our approach lies in its dual-path architecture: one path maps continuous imaging features to learned discrete codebooks for noise-resistant representation, while the parallel path preserves fine-grained details through continuous feature processing. This dual representation is integrated through a novel patch-wise fusion mechanism that maintains local spatial relationships while capturing global context via Transformer-based processing. In extensive evaluations across three diverse datasets (HECKTOR, H\&N1, and NSCLC Radiogenomics), RobSurv demonstrates superior performance, achieving concordance index of 0.771, 0.742, and 0.734 respectively - significantly outperforming existing methods. Most notably, our model maintains robust performance even under severe noise conditions, with performance degradation of only 3.8-4.5\% compared to 8-12\% in baseline methods. These results, combined with strong generalization across different cancer types and imaging protocols, establish RobSurv as a promising solution for reliable clinical prognosis that can enhance treatment planning and patient care.
Survival Prediction in Lung Cancer through Multi-Modal Representation Learning
Sep 30, 2024



Survival prediction is a crucial task associated with cancer diagnosis and treatment planning. This paper presents a novel approach to survival prediction by harnessing comprehensive information from CT and PET scans, along with associated Genomic data. Current methods rely on either a single modality or the integration of multiple modalities for prediction without adequately addressing associations across patients or modalities. We aim to develop a robust predictive model for survival outcomes by integrating multi-modal imaging data with genetic information while accounting for associations across patients and modalities. We learn representations for each modality via a self-supervised module and harness the semantic similarities across the patients to ensure the embeddings are aligned closely. However, optimizing solely for global relevance is inadequate, as many pairs sharing similar high-level semantics, such as tumor type, are inadvertently pushed apart in the embedding space. To address this issue, we use a cross-patient module (CPM) designed to harness inter-subject correspondences. The CPM module aims to bring together embeddings from patients with similar disease characteristics. Our experimental evaluation of the dataset of Non-Small Cell Lung Cancer (NSCLC) patients demonstrates the effectiveness of our approach in predicting survival outcomes, outperforming state-of-the-art methods.
Translating Imaging to Genomics: Leveraging Transformers for Predictive Modeling
Aug 01, 2024In this study, we present a novel approach for predicting genomic information from medical imaging modalities using a transformer-based model. We aim to bridge the gap between imaging and genomics data by leveraging transformer networks, allowing for accurate genomic profile predictions from CT/MRI images. Presently most studies rely on the use of whole slide images (WSI) for the association, which are obtained via invasive methodologies. We propose using only available CT/MRI images to predict genomic sequences. Our transformer based approach is able to efficiently generate associations between multiple sequences based on CT/MRI images alone. This work paves the way for the use of non-invasive imaging modalities for precise and personalized healthcare, allowing for a better understanding of diseases and treatment.
LISR: Learning Linear 3D Implicit Surface Representation Using Compactly Supported Radial Basis Functions
Feb 11, 2024Implicit 3D surface reconstruction of an object from its partial and noisy 3D point cloud scan is the classical geometry processing and 3D computer vision problem. In the literature, various 3D shape representations have been developed, differing in memory efficiency and shape retrieval effectiveness, such as volumetric, parametric, and implicit surfaces. Radial basis functions provide memory-efficient parameterization of the implicit surface. However, we show that training a neural network using the mean squared error between the ground-truth implicit surface and the linear basis-based implicit surfaces does not converge to the global solution. In this work, we propose locally supported compact radial basis functions for a linear representation of the implicit surface. This representation enables us to generate 3D shapes with arbitrary topologies at any resolution due to their continuous nature. We then propose a neural network architecture for learning the linear implicit shape representation of the 3D surface of an object. We learn linear implicit shapes within a supervised learning framework using ground truth Signed-Distance Field (SDF) data for guidance. The classical strategies face difficulties in finding linear implicit shapes from a given 3D point cloud due to numerical issues (requires solving inverse of a large matrix) in basis and query point selection. The proposed approach achieves better Chamfer distance and comparable F-score than the state-of-the-art approach on the benchmark dataset. We also show the effectiveness of the proposed approach by using it for the 3D shape completion task.
Deriving Explanation of Deep Visual Saliency Models
Sep 08, 2021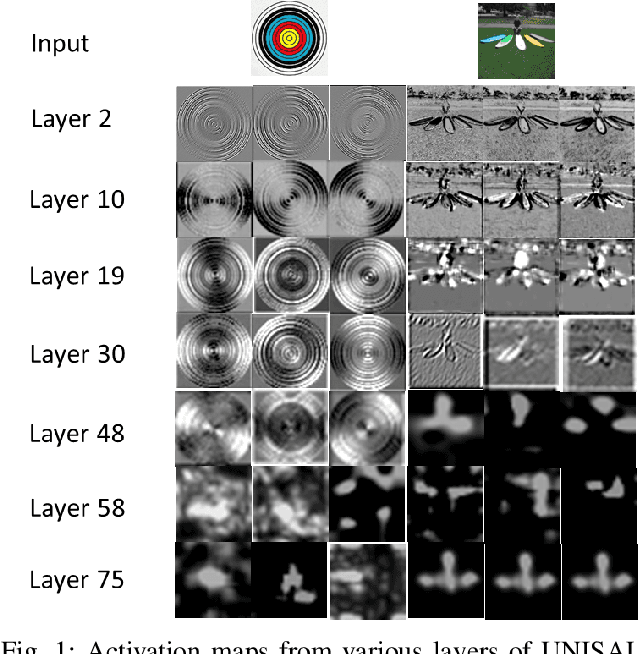
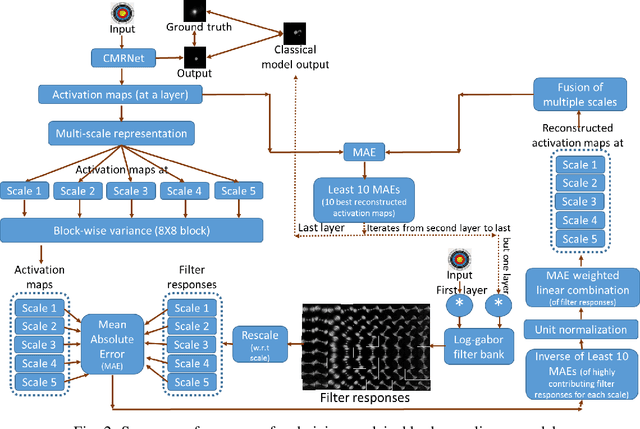
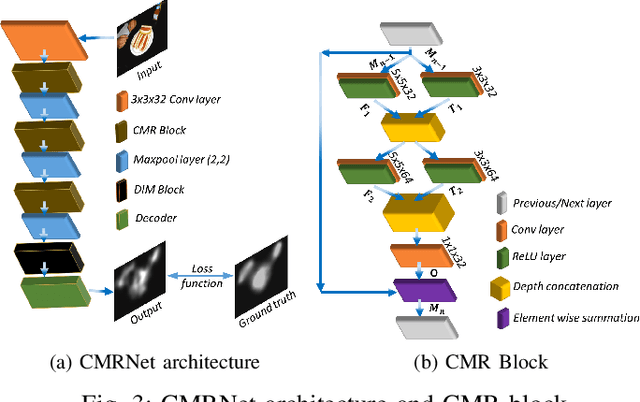
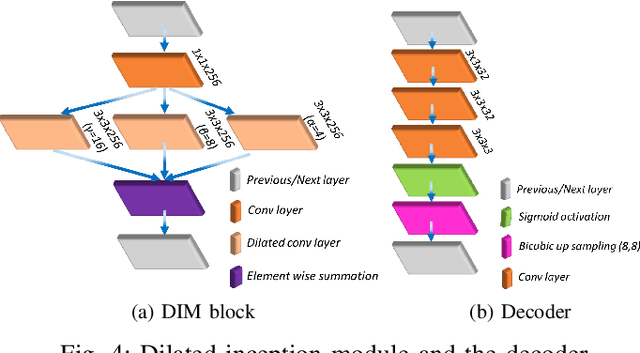
Deep neural networks have shown their profound impact on achieving human level performance in visual saliency prediction. However, it is still unclear how they learn the task and what it means in terms of understanding human visual system. In this work, we develop a technique to derive explainable saliency models from their corresponding deep neural architecture based saliency models by applying human perception theories and the conventional concepts of saliency. This technique helps us understand the learning pattern of the deep network at its intermediate layers through their activation maps. Initially, we consider two state-of-the-art deep saliency models, namely UNISAL and MSI-Net for our interpretation. We use a set of biologically plausible log-gabor filters for identifying and reconstructing the activation maps of them using our explainable saliency model. The final saliency map is generated using these reconstructed activation maps. We also build our own deep saliency model named cross-concatenated multi-scale residual block based network (CMRNet) for saliency prediction. Then, we evaluate and compare the performance of the explainable models derived from UNISAL, MSI-Net and CMRNet on three benchmark datasets with other state-of-the-art methods. Hence, we propose that this approach of explainability can be applied to any deep visual saliency model for interpretation which makes it a generic one.
Understanding Character Recognition using Visual Explanations Derived from the Human Visual System and Deep Networks
Aug 29, 2021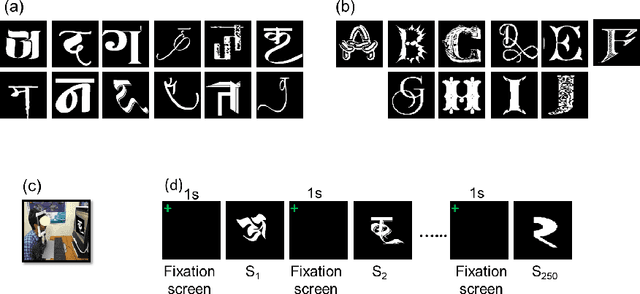
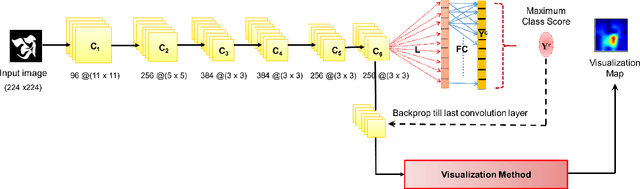
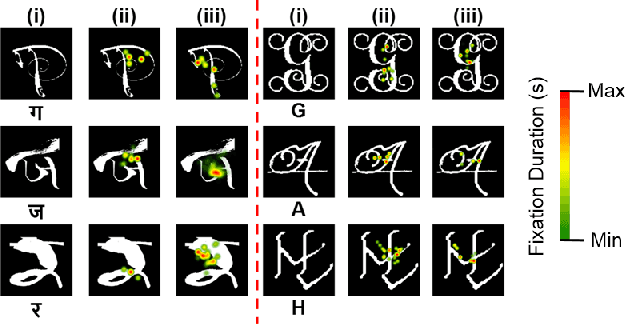
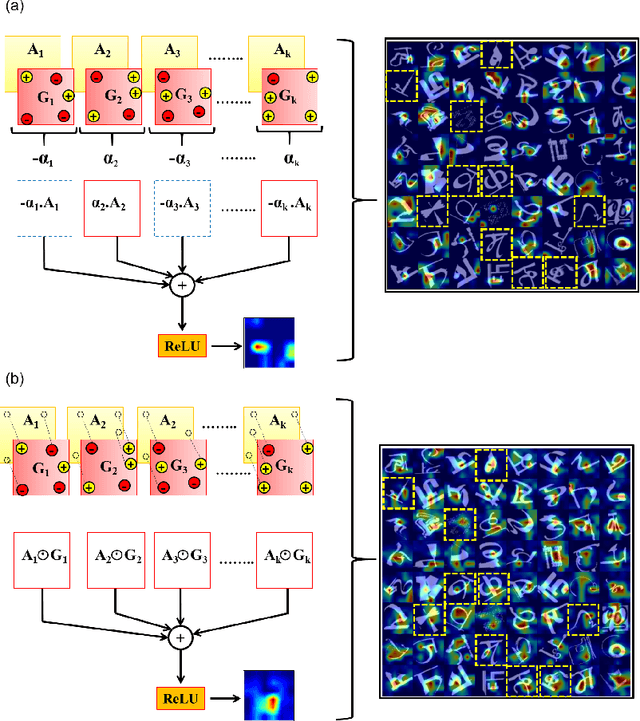
Human observers engage in selective information uptake when classifying visual patterns. The same is true of deep neural networks, which currently constitute the best performing artificial vision systems. Our goal is to examine the congruence, or lack thereof, in the information-gathering strategies of the two systems. We have operationalized our investigation as a character recognition task. We have used eye-tracking to assay the spatial distribution of information hotspots for humans via fixation maps and an activation mapping technique for obtaining analogous distributions for deep networks through visualization maps. Qualitative comparison between visualization maps and fixation maps reveals an interesting correlate of congruence. The deep learning model considered similar regions in character, which humans have fixated in the case of correctly classified characters. On the other hand, when the focused regions are different for humans and deep nets, the characters are typically misclassified by the latter. Hence, we propose to use the visual fixation maps obtained from the eye-tracking experiment as a supervisory input to align the model's focus on relevant character regions. We find that such supervision improves the model's performance significantly and does not require any additional parameters. This approach has the potential to find applications in diverse domains such as medical analysis and surveillance in which explainability helps to determine system fidelity.
Multi-Task Driven Explainable Diagnosis of COVID-19 using Chest X-ray Images
Aug 03, 2020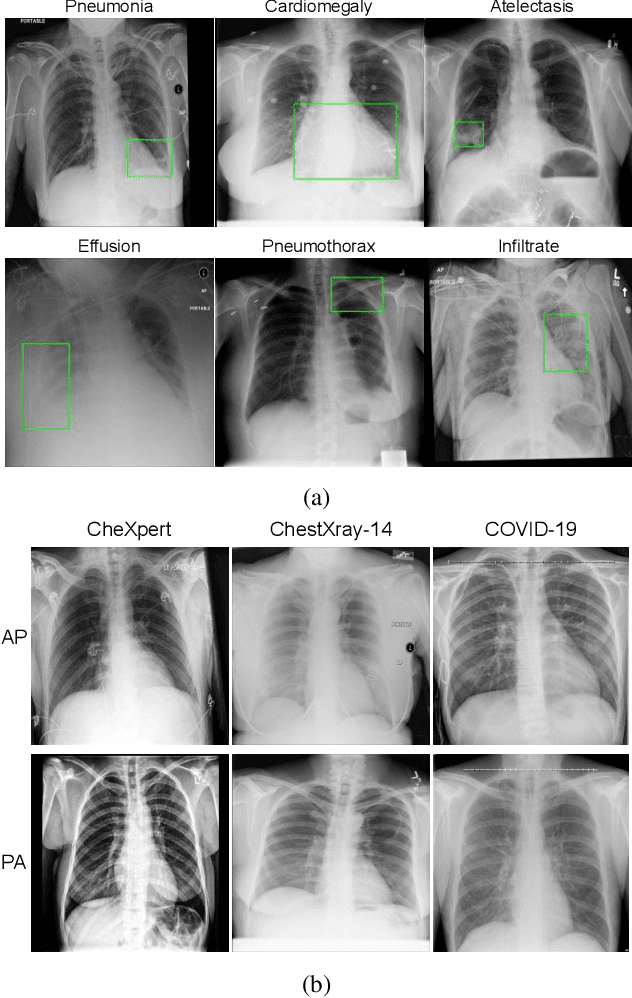
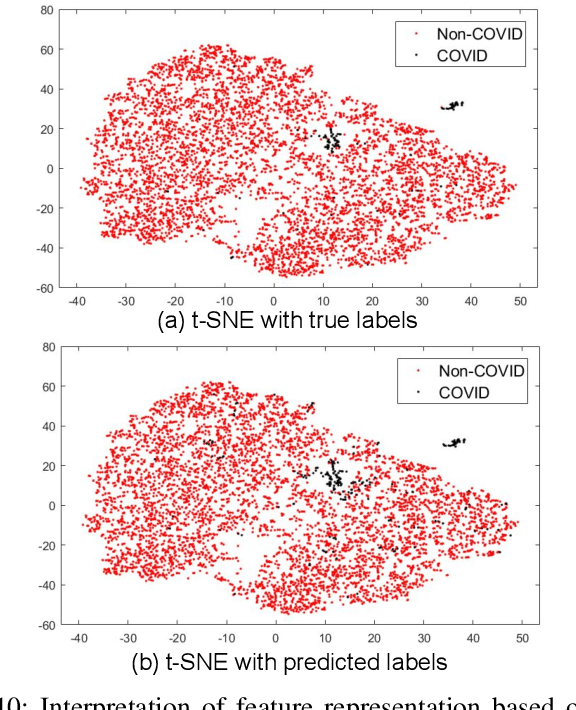
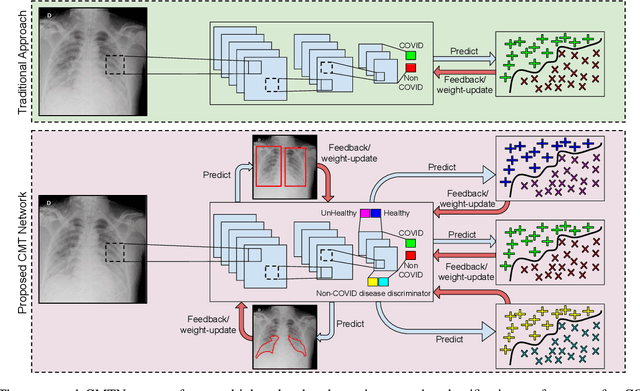
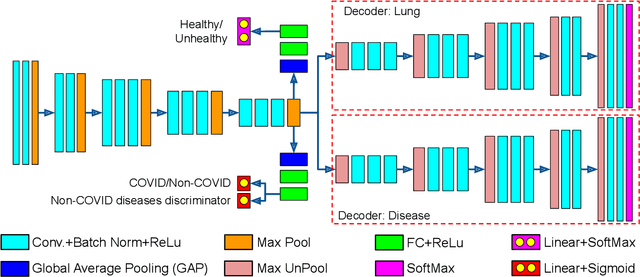
With increasing number of COVID-19 cases globally, all the countries are ramping up the testing numbers. While the RT-PCR kits are available in sufficient quantity in several countries, others are facing challenges with limited availability of testing kits and processing centers in remote areas. This has motivated researchers to find alternate methods of testing which are reliable, easily accessible and faster. Chest X-Ray is one of the modalities that is gaining acceptance as a screening modality. Towards this direction, the paper has two primary contributions. Firstly, we present the COVID-19 Multi-Task Network which is an automated end-to-end network for COVID-19 screening. The proposed network not only predicts whether the CXR has COVID-19 features present or not, it also performs semantic segmentation of the regions of interest to make the model explainable. Secondly, with the help of medical professionals, we manually annotate the lung regions of 9000 frontal chest radiographs taken from ChestXray-14, CheXpert and a consolidated COVID-19 dataset. Further, 200 chest radiographs pertaining to COVID-19 patients are also annotated for semantic segmentation. This database will be released to the research community.
Compressive sensing based privacy for fall detection
Jan 10, 2020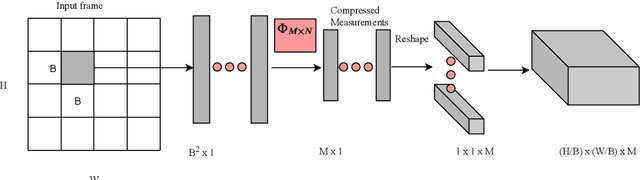

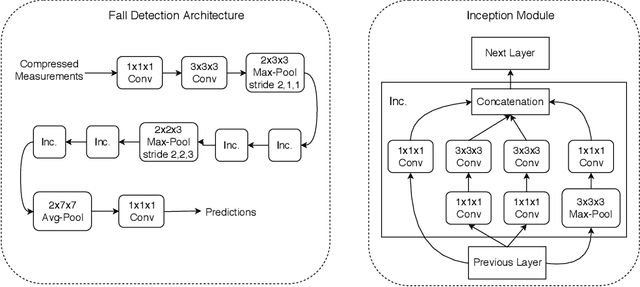
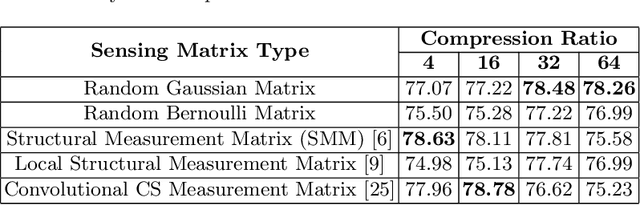
Fall detection holds immense importance in the field of healthcare, where timely detection allows for instant medical assistance. In this context, we propose a 3D ConvNet architecture which consists of 3D Inception modules for fall detection. The proposed architecture is a custom version of Inflated 3D (I3D) architecture, that takes compressed measurements of video sequence as spatio-temporal input, obtained from compressive sensing framework, rather than video sequence as input, as in the case of I3D convolutional neural network. This is adopted since privacy raises a huge concern for patients being monitored through these RGB cameras. The proposed framework for fall detection is flexible enough with respect to a wide variety of measurement matrices. Ten action classes randomly selected from Kinetics-400 with no fall examples, are employed to train our 3D ConvNet post compressive sensing with different types of sensing matrices on the original video clips. Our results show that 3D ConvNet performance remains unchanged with different sensing matrices. Also, the performance obtained with Kinetics pre-trained 3D ConvNet on compressively sensed fall videos from benchmark datasets is better than the state-of-the-art techniques.
DSAL-GAN: Denoising based Saliency Prediction with Generative Adversarial Networks
Apr 02, 2019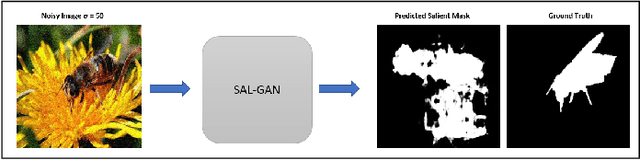

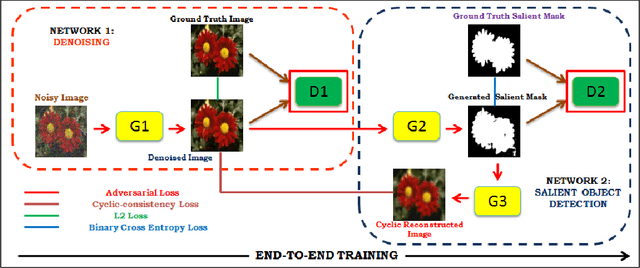

Synthesizing high quality saliency maps from noisy images is a challenging problem in computer vision and has many practical applications. Samples generated by existing techniques for saliency detection cannot handle the noise perturbations smoothly and fail to delineate the salient objects present in the given scene. In this paper, we present a novel end-to-end coupled Denoising based Saliency Prediction with Generative Adversarial Network (DSAL-GAN) framework to address the problem of salient object detection in noisy images. DSAL-GAN consists of two generative adversarial-networks (GAN) trained end-to-end to perform denoising and saliency prediction altogether in a holistic manner. The first GAN consists of a generator which denoises the noisy input image, and in the discriminator counterpart we check whether the output is a denoised image or ground truth original image. The second GAN predicts the saliency maps from raw pixels of the input denoised image using a data-driven metric based on saliency prediction method with adversarial loss. Cycle consistency loss is also incorporated to further improve salient region prediction. We demonstrate with comprehensive evaluation that the proposed framework outperforms several baseline saliency models on various performance benchmarks.
NEMGAN: Noise Engineered Mode-matching GAN
Nov 08, 2018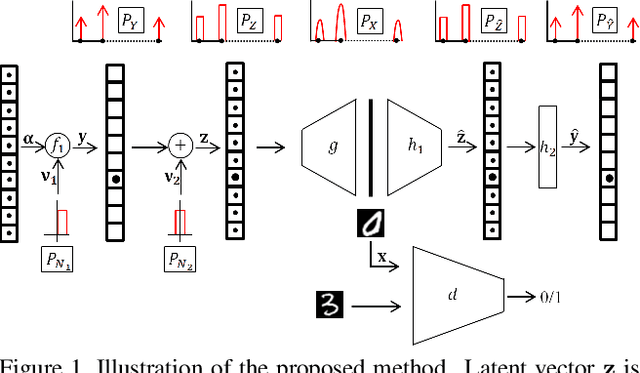
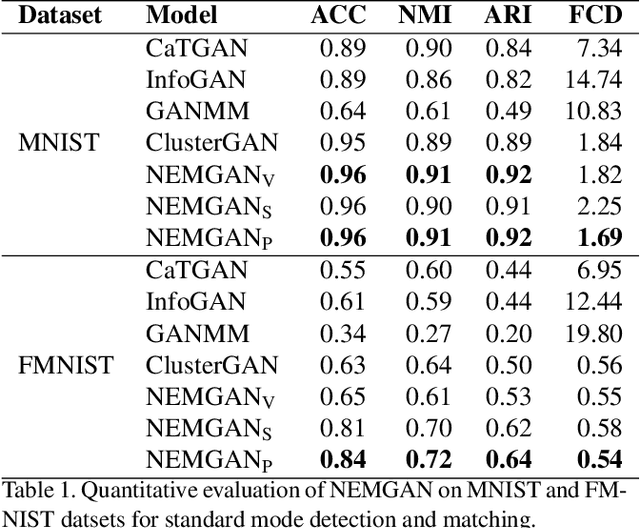

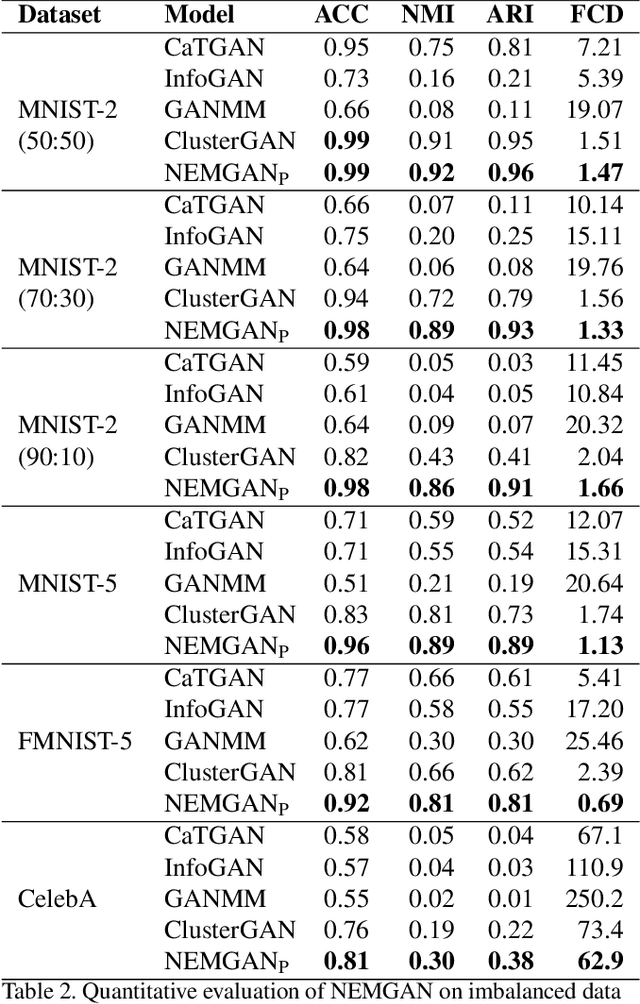
Conditional generation refers to the process of sampling from an unknown distribution conditioned on semantics of the data. This can be achieved by augmenting the generative model with the desired semantic labels, albeit it is not straightforward in an unsupervised setting where the semantic label of every data sample is unknown. In this paper, we address this issue by proposing a method that can generate samples conditioned on the properties of a latent distribution engineered in accordance with a certain data prior. In particular, a latent space inversion network is trained in tandem with a generative adversarial network such that the modal properties of the latent space distribution are induced in the data generating distribution. We demonstrate that our model despite being fully unsupervised, is effective in learning meaningful representations through its mode matching property. We validate our method on multiple unsupervised tasks such as conditional generation, attribute discovery and inference using three real world image datasets namely MNIST, CIFAR-10 and CelebA and show that the results are comparable to the state-of-the-art methods.