 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Do Autoregressive Sequence Models Forecast Physical Wavefields? A Controlled Study on Synthetic Seismograms
Jun 09, 2026Long-horizon autoregressive forecasting of oscillatory physical signals, such as seismograms, gravitational-wave strain, and similar wavefields is limited by error accumulation: as a causal model is fed its own outputs over hundreds of steps, small per-step errors compound into phase drift that pointwise metrics fail to detect. We ask when such rollout stays stable, using synthetic three-component seismograms as a physically structured testbed and the \textsc{SeismoGPT} autoregressive forecaster as the model under study. Through controlled, intra-architecture ablations evaluated on free-running rollout with paired significance tests, we isolate the contribution of each design choice. Multi-token prediction is the dominant stabilizer, accounting for almost the entire improvement over a single-token baseline ($+0.040$ median NCC); a horizon-embedding hybrid prediction head and a cross-horizon STFT-magnitude coherence loss each add a small but consistent further gain. Performance depends sharply on a context-ratio threshold near one, roughly the full P-S interval of observed signal, below which rollout generalization collapses. The dominant residual failure is a polarity inversion that a magnitude-based spectral loss cannot, by construction, penalize, identifying phase-aware objectives as the natural next step. We frame this as a controlled study of rollout stability on oscillatory wavefields, not a benchmark of forecasting architectures.
Data-Driven Forecasting of three-Component Seismograms Using Transformer Architectures
Jun 01, 2026Forecasting seismic waveforms beyond observed data remains challenging due to the nonlinear, dispersive, and multi-scale nature of seismic wave propagation. In this work, we introduce \textsc{SeismoGPT}, a transformer-based autoregressive model designed to forecast three-component seismic waveforms directly in the time domain. Forecasting is formulated as a physically constrained continuation problem in which the model receives waveform context beginning at the P-wave arrival and extending a defined time beyond the S-wave arrival, after which future motion is generated recursively without access to ground-truth samples. Evaluation is performed on synthetic seismograms spanning source depths of 5--100\,km, epicentral distances of 10--90$^\circ$, and magnitudes $3 \leq M_w \leq 7$. To disentangle the effects of context length and prediction horizon, we define three evaluation configurations using a distance-normalized context ratio and fixed prediction horizons of 120 and 240\,s. Across all configurations, the model achieves median normalized cross correlation above 0.93. Analysis of representative forecasts shows that successful predictions preserve both phase coherence and spectral energy distribution. Where failure cases arise, this is primarily due to gradual phase drift during autoregressive rollout rather than unphysical signal generation. These results demonstrate that transformer-based sequence models can learn stable dynamical continuation of seismic wavefields, highlighting the potential of foundation-model approaches for physics-driven time-series forecasting. There are potential applications of this methodology in seismic warning and hazard mitigation, particularly for next-generation gravitational-wave observatories, such as the Einstein Telescope.
Transformers Provably Learn to Internalize Chain-of-Thought
May 27, 2026Chain-of-Thought (CoT) prompting substantially improves the sample efficiency of transformers, reducing the complexity of tasks like parity learning from exponential to polynomial in the input length. However, generating explicit reasoning steps at inference is computationally expensive. Implicit Chain-of-Thought (ICoT) has emerged as a promising empirical remedy that trains models to internalize intermediate steps within their hidden states, but its theoretical foundations remain poorly understood. We give the first theoretical analysis of ICoT, proving that an $L$-layer transformer trained under our proposed Log-ICoT curriculum learns $k$-parity with $\mathsf{poly}(n)$ samples and $L = \log_2 k$ training stages. This matches the sample efficiency of explicit CoT while eliminating its inference overhead, and extends prior one-layer parity guarantees to multi-layer architectures. Compared to standard ICoT, which removes thinking tokens one at a time, Log-ICoT removes them in geometric chunks, reducing the number of stages from linear in $k$ to logarithmic. Experiments on multi-layer transformers confirm the theory and visualize how reasoning is progressively absorbed into deeper layers.
Learning the Preferences of a Learning Agent
May 09, 2026For AI systems to be useful to humans, they must understand and act in accordance with our values and preferences. Since specifying preferences is a hard task, inverse reinforcement learning (IRL) aims to develop methods that allow for inferring preferences from observed behavior. However, IRL assumes the human to be approximately optimal. This is a big limitation in cases where the human themselves may be learning to act optimally in an environment. In this paper, we formalize the problem of learning the preferences of a learning agent: a predictor observes a learner acting online and tries to infer the underlying reward function being (initially suboptimally) optimized by the learner. We model the learner as either being no-regret, or as converging to an optimal Boltzmann policy over time. In each of these settings, we establish theoretical guarantees for various preference learning algorithms, or otherwise show that such guarantees are impossible.
Robust and Diverse Multi-Agent Learning via Rational Policy Gradient
Nov 12, 2025Adversarial optimization algorithms that explicitly search for flaws in agents' policies have been successfully applied to finding robust and diverse policies in multi-agent settings. However, the success of adversarial optimization has been largely limited to zero-sum settings because its naive application in cooperative settings leads to a critical failure mode: agents are irrationally incentivized to self-sabotage, blocking the completion of tasks and halting further learning. To address this, we introduce Rationality-preserving Policy Optimization (RPO), a formalism for adversarial optimization that avoids self-sabotage by ensuring agents remain rational--that is, their policies are optimal with respect to some possible partner policy. To solve RPO, we develop Rational Policy Gradient (RPG), which trains agents to maximize their own reward in a modified version of the original game in which we use opponent shaping techniques to optimize the adversarial objective. RPG enables us to extend a variety of existing adversarial optimization algorithms that, no longer subject to the limitations of self-sabotage, can find adversarial examples, improve robustness and adaptability, and learn diverse policies. We empirically validate that our approach achieves strong performance in several popular cooperative and general-sum environments. Our project page can be found at https://rational-policy-gradient.github.io.
GSM-Agent: Understanding Agentic Reasoning Using Controllable Environments
Sep 26, 2025
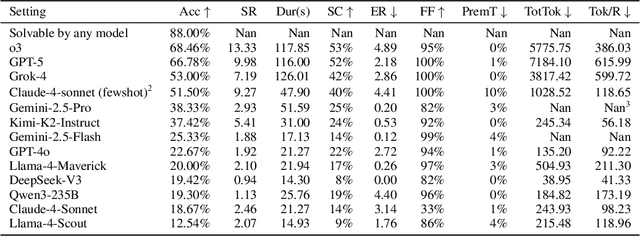


As LLMs are increasingly deployed as agents, agentic reasoning - the ability to combine tool use, especially search, and reasoning - becomes a critical skill. However, it is hard to disentangle agentic reasoning when evaluated in complex environments and tasks. Current agent benchmarks often mix agentic reasoning with challenging math reasoning, expert-level knowledge, and other advanced capabilities. To fill this gap, we build a novel benchmark, GSM-Agent, where an LLM agent is required to solve grade-school-level reasoning problems, but is only presented with the question in the prompt without the premises that contain the necessary information to solve the task, and needs to proactively collect that information using tools. Although the original tasks are grade-school math problems, we observe that even frontier models like GPT-5 only achieve 67% accuracy. To understand and analyze the agentic reasoning patterns, we propose the concept of agentic reasoning graph: cluster the environment's document embeddings into nodes, and map each tool call to its nearest node to build a reasoning path. Surprisingly, we identify that the ability to revisit a previously visited node, widely taken as a crucial pattern in static reasoning, is often missing for agentic reasoning for many models. Based on the insight, we propose a tool-augmented test-time scaling method to improve LLM's agentic reasoning performance by adding tools to encourage models to revisit. We expect our benchmark and the agentic reasoning framework to aid future studies of understanding and pushing the boundaries of agentic reasoning.
The Singapore Consensus on Global AI Safety Research Priorities
Jun 25, 2025


Rapidly improving AI capabilities and autonomy hold significant promise of transformation, but are also driving vigorous debate on how to ensure that AI is safe, i.e., trustworthy, reliable, and secure. Building a trusted ecosystem is therefore essential -- it helps people embrace AI with confidence and gives maximal space for innovation while avoiding backlash. The "2025 Singapore Conference on AI (SCAI): International Scientific Exchange on AI Safety" aimed to support research in this space by bringing together AI scientists across geographies to identify and synthesise research priorities in AI safety. This resulting report builds on the International AI Safety Report chaired by Yoshua Bengio and backed by 33 governments. By adopting a defence-in-depth model, this report organises AI safety research domains into three types: challenges with creating trustworthy AI systems (Development), challenges with evaluating their risks (Assessment), and challenges with monitoring and intervening after deployment (Control).
Generalization or Hallucination? Understanding Out-of-Context Reasoning in Transformers
Jun 12, 2025Large language models (LLMs) can acquire new knowledge through fine-tuning, but this process exhibits a puzzling duality: models can generalize remarkably from new facts, yet are also prone to hallucinating incorrect information. However, the reasons for this phenomenon remain poorly understood. In this work, we argue that both behaviors stem from a single mechanism known as out-of-context reasoning (OCR): the ability to deduce implications by associating concepts, even those without a causal link. Our experiments across five prominent LLMs confirm that OCR indeed drives both generalization and hallucination, depending on whether the associated concepts are causally related. To build a rigorous theoretical understanding of this phenomenon, we then formalize OCR as a synthetic factual recall task. We empirically show that a one-layer single-head attention-only transformer with factorized output and value matrices can learn to solve this task, while a model with combined weights cannot, highlighting the crucial role of matrix factorization. Our theoretical analysis shows that the OCR capability can be attributed to the implicit bias of gradient descent, which favors solutions that minimize the nuclear norm of the combined output-value matrix. This mathematical structure explains why the model learns to associate facts and implications with high sample efficiency, regardless of whether the correlation is causal or merely spurious. Ultimately, our work provides a theoretical foundation for understanding the OCR phenomenon, offering a new lens for analyzing and mitigating undesirable behaviors from knowledge injection.
Provable Sim-to-Real Transfer via Offline Domain Randomization
Jun 11, 2025


Reinforcement-learning agents often struggle when deployed from simulation to the real-world. A dominant strategy for reducing the sim-to-real gap is domain randomization (DR) which trains the policy across many simulators produced by sampling dynamics parameters, but standard DR ignores offline data already available from the real system. We study offline domain randomization (ODR), which first fits a distribution over simulator parameters to an offline dataset. While a growing body of empirical work reports substantial gains with algorithms such as DROPO, the theoretical foundations of ODR remain largely unexplored. In this work, we (i) formalize ODR as a maximum-likelihood estimation over a parametric simulator family, (ii) prove consistency of this estimator under mild regularity and identifiability conditions, showing it converges to the true dynamics as the dataset grows, (iii) derive gap bounds demonstrating ODRs sim-to-real error is up to an O(M) factor tighter than uniform DR in the finite-simulator case (and analogous gains in the continuous setting), and (iv) introduce E-DROPO, a new version of DROPO which adds an entropy bonus to prevent variance collapse, yielding broader randomization and more robust zero-shot transfer in practice.
Reasoning by Superposition: A Theoretical Perspective on Chain of Continuous Thought
May 18, 2025Large Language Models (LLMs) have demonstrated remarkable performance in many applications, including challenging reasoning problems via chain-of-thoughts (CoTs) techniques that generate ``thinking tokens'' before answering the questions. While existing theoretical works demonstrate that CoTs with discrete tokens boost the capability of LLMs, recent work on continuous CoTs lacks a theoretical understanding of why it outperforms discrete counterparts in various reasoning tasks such as directed graph reachability, a fundamental graph reasoning problem that includes many practical domain applications as special cases. In this paper, we prove that a two-layer transformer with $D$ steps of continuous CoTs can solve the directed graph reachability problem, where $D$ is the diameter of the graph, while the best known result of constant-depth transformers with discrete CoTs requires $O(n^2)$ decoding steps where $n$ is the number of vertices ($D<n$). In our construction, each continuous thought vector is a superposition state that encodes multiple search frontiers simultaneously (i.e., parallel breadth-first search (BFS)), while discrete CoTs must choose a single path sampled from the superposition state, which leads to sequential search that requires many more steps and may be trapped into local solutions. We also performed extensive experiments to verify that our theoretical construction aligns well with the empirical solution obtained via training dynamics. Notably, encoding of multiple search frontiers as a superposition state automatically emerges in training continuous CoTs, without explicit supervision to guide the model to explore multiple paths simultaneously.