 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmark Designers Should "Train on the Test Set" to Expose Exploitable Non-Visual Shortcuts
Nov 06, 2025Robust benchmarks are crucial for evaluating Multimodal Large Language Models (MLLMs). Yet we find that models can ace many multimodal benchmarks without strong visual understanding, instead exploiting biases, linguistic priors, and superficial patterns. This is especially problematic for vision-centric benchmarks that are meant to require visual inputs. We adopt a diagnostic principle for benchmark design: if a benchmark can be gamed, it will be. Designers should therefore try to ``game'' their own benchmarks first, using diagnostic and debiasing procedures to systematically identify and mitigate non-visual biases. Effective diagnosis requires directly ``training on the test set'' -- probing the released test set for its intrinsic, exploitable patterns. We operationalize this standard with two components. First, we diagnose benchmark susceptibility using a ``Test-set Stress-Test'' (TsT) methodology. Our primary diagnostic tool involves fine-tuning a powerful Large Language Model via $k$-fold cross-validation on exclusively the non-visual, textual inputs of the test set to reveal shortcut performance and assign each sample a bias score $s(x)$. We complement this with a lightweight Random Forest-based diagnostic operating on hand-crafted features for fast, interpretable auditing. Second, we debias benchmarks by filtering high-bias samples using an ``Iterative Bias Pruning'' (IBP) procedure. Applying this framework to four benchmarks -- VSI-Bench, CV-Bench, MMMU, and VideoMME -- we uncover pervasive non-visual biases. As a case study, we apply our full framework to create VSI-Bench-Debiased, demonstrating reduced non-visual solvability and a wider vision-blind performance gap than the original.
Cambrian-S: Towards Spatial Supersensing in Video
Nov 06, 2025We argue that progress in true multimodal intelligence calls for a shift from reactive, task-driven systems and brute-force long context towards a broader paradigm of supersensing. We frame spatial supersensing as four stages beyond linguistic-only understanding: semantic perception (naming what is seen), streaming event cognition (maintaining memory across continuous experiences), implicit 3D spatial cognition (inferring the world behind pixels), and predictive world modeling (creating internal models that filter and organize information). Current benchmarks largely test only the early stages, offering narrow coverage of spatial cognition and rarely challenging models in ways that require true world modeling. To drive progress in spatial supersensing, we present VSI-SUPER, a two-part benchmark: VSR (long-horizon visual spatial recall) and VSC (continual visual spatial counting). These tasks require arbitrarily long video inputs yet are resistant to brute-force context expansion. We then test data scaling limits by curating VSI-590K and training Cambrian-S, achieving +30% absolute improvement on VSI-Bench without sacrificing general capabilities. Yet performance on VSI-SUPER remains limited, indicating that scale alone is insufficient for spatial supersensing. We propose predictive sensing as a path forward, presenting a proof-of-concept in which a self-supervised next-latent-frame predictor leverages surprise (prediction error) to drive memory and event segmentation. On VSI-SUPER, this approach substantially outperforms leading proprietary baselines, showing that spatial supersensing requires models that not only see but also anticipate, select, and organize experience.
SIMS-V: Simulated Instruction-Tuning for Spatial Video Understanding
Nov 06, 2025Despite impressive high-level video comprehension, multimodal language models struggle with spatial reasoning across time and space. While current spatial training approaches rely on real-world video data, obtaining diverse footage with precise spatial annotations remains a bottleneck. To alleviate this bottleneck, we present SIMS-V -- a systematic data-generation framework that leverages the privileged information of 3D simulators to create spatially-rich video training data for multimodal language models. Using this framework, we investigate which properties of simulated data drive effective real-world transfer through systematic ablations of question types, mixes, and scales. We identify a minimal set of three question categories (metric measurement, perspective-dependent reasoning, and temporal tracking) that prove most effective for developing transferable spatial intelligence, outperforming comprehensive coverage despite using fewer question types. These insights enable highly efficient training: our 7B-parameter video LLM fine-tuned on just 25K simulated examples outperforms the larger 72B baseline and achieves competitive performance with proprietary models on rigorous real-world spatial reasoning benchmarks. Our approach demonstrates robust generalization, maintaining performance on general video understanding while showing substantial improvements on embodied and real-world spatial tasks.
MetaCLIP 2: A Worldwide Scaling Recipe
Jul 29, 2025
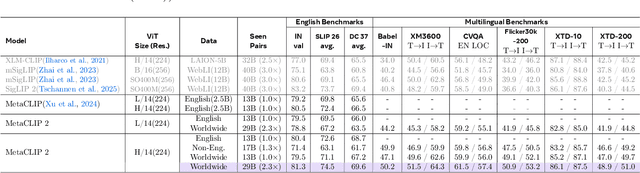


Contrastive Language-Image Pretraining (CLIP) is a popular foundation model, supporting from zero-shot classification, retrieval to encoders for multimodal large language models (MLLMs). Although CLIP is successfully trained on billion-scale image-text pairs from the English world, scaling CLIP's training further to learning from the worldwide web data is still challenging: (1) no curation method is available to handle data points from non-English world; (2) the English performance from existing multilingual CLIP is worse than its English-only counterpart, i.e., "curse of multilinguality" that is common in LLMs. Here, we present MetaCLIP 2, the first recipe training CLIP from scratch on worldwide web-scale image-text pairs. To generalize our findings, we conduct rigorous ablations with minimal changes that are necessary to address the above challenges and present a recipe enabling mutual benefits from English and non-English world data. In zero-shot ImageNet classification, MetaCLIP 2 ViT-H/14 surpasses its English-only counterpart by 0.8% and mSigLIP by 0.7%, and surprisingly sets new state-of-the-art without system-level confounding factors (e.g., translation, bespoke architecture changes) on multilingual benchmarks, such as CVQA with 57.4%, Babel-ImageNet with 50.2% and XM3600 with 64.3% on image-to-text retrieval.
Spatial Mental Modeling from Limited Views
Jun 26, 2025



Can Vision Language Models (VLMs) imagine the full scene from just a few views, like humans do? Humans form spatial mental models, internal representations of unseen space, to reason about layout, perspective, and motion. Our new MindCube benchmark with 21,154 questions across 3,268 images exposes this critical gap, where existing VLMs exhibit near-random performance. Using MindCube, we systematically evaluate how well VLMs build robust spatial mental models through representing positions (cognitive mapping), orientations (perspective-taking), and dynamics (mental simulation for "what-if" movements). We then explore three approaches to help VLMs approximate spatial mental models, including unseen intermediate views, natural language reasoning chains, and cognitive maps. The significant improvement comes from a synergistic approach, "map-then-reason", that jointly trains the model to first generate a cognitive map and then reason upon it. By training models to reason over these internal maps, we boosted accuracy from 37.8% to 60.8% (+23.0%). Adding reinforcement learning pushed performance even further to 70.7% (+32.9%). Our key insight is that such scaffolding of spatial mental models, actively constructing and utilizing internal structured spatial representations with flexible reasoning processes, significantly improves understanding of unobservable space.
LiveCodeBench Pro: How Do Olympiad Medalists Judge LLMs in Competitive Programming?
Jun 13, 2025Recent reports claim that large language models (LLMs) now outperform elite humans in competitive programming. Drawing on knowledge from a group of medalists in international algorithmic contests, we revisit this claim, examining how LLMs differ from human experts and where limitations still remain. We introduce LiveCodeBench Pro, a benchmark composed of problems from Codeforces, ICPC, and IOI that are continuously updated to reduce the likelihood of data contamination. A team of Olympiad medalists annotates every problem for algorithmic categories and conducts a line-by-line analysis of failed model-generated submissions. Using this new data and benchmark, we find that frontier models still have significant limitations: without external tools, the best model achieves only 53% pass@1 on medium-difficulty problems and 0% on hard problems, domains where expert humans still excel. We also find that LLMs succeed at implementation-heavy problems but struggle with nuanced algorithmic reasoning and complex case analysis, often generating confidently incorrect justifications. High performance appears largely driven by implementation precision and tool augmentation, not superior reasoning. LiveCodeBench Pro thus highlights the significant gap to human grandmaster levels, while offering fine-grained diagnostics to steer future improvements in code-centric LLM reasoning.
Traveling Across Languages: Benchmarking Cross-Lingual Consistency in Multimodal LLMs
May 21, 2025The rapid evolution of multimodal large language models (MLLMs) has significantly enhanced their real-world applications. However, achieving consistent performance across languages, especially when integrating cultural knowledge, remains a significant challenge. To better assess this issue, we introduce two new benchmarks: KnowRecall and VisRecall, which evaluate cross-lingual consistency in MLLMs. KnowRecall is a visual question answering benchmark designed to measure factual knowledge consistency in 15 languages, focusing on cultural and historical questions about global landmarks. VisRecall assesses visual memory consistency by asking models to describe landmark appearances in 9 languages without access to images. Experimental results reveal that state-of-the-art MLLMs, including proprietary ones, still struggle to achieve cross-lingual consistency. This underscores the need for more robust approaches that produce truly multilingual and culturally aware models.
Exploring the Deep Fusion of Large Language Models and Diffusion Transformers for Text-to-Image Synthesis
May 15, 2025



This paper does not describe a new method; instead, it provides a thorough exploration of an important yet understudied design space related to recent advances in text-to-image synthesis -- specifically, the deep fusion of large language models (LLMs) and diffusion transformers (DiTs) for multi-modal generation. Previous studies mainly focused on overall system performance rather than detailed comparisons with alternative methods, and key design details and training recipes were often left undisclosed. These gaps create uncertainty about the real potential of this approach. To fill these gaps, we conduct an empirical study on text-to-image generation, performing controlled comparisons with established baselines, analyzing important design choices, and providing a clear, reproducible recipe for training at scale. We hope this work offers meaningful data points and practical guidelines for future research in multi-modal generation.
BLIP3-o: A Family of Fully Open Unified Multimodal Models-Architecture, Training and Dataset
May 14, 2025Unifying image understanding and generation has gained growing attention in recent research on multimodal models. Although design choices for image understanding have been extensively studied, the optimal model architecture and training recipe for a unified framework with image generation remain underexplored. Motivated by the strong potential of autoregressive and diffusion models for high-quality generation and scalability, we conduct a comprehensive study of their use in unified multimodal settings, with emphasis on image representations, modeling objectives, and training strategies. Grounded in these investigations, we introduce a novel approach that employs a diffusion transformer to generate semantically rich CLIP image features, in contrast to conventional VAE-based representations. This design yields both higher training efficiency and improved generative quality. Furthermore, we demonstrate that a sequential pretraining strategy for unified models-first training on image understanding and subsequently on image generation-offers practical advantages by preserving image understanding capability while developing strong image generation ability. Finally, we carefully curate a high-quality instruction-tuning dataset BLIP3o-60k for image generation by prompting GPT-4o with a diverse set of captions covering various scenes, objects, human gestures, and more. Building on our innovative model design, training recipe, and datasets, we develop BLIP3-o, a suite of state-of-the-art unified multimodal models. BLIP3-o achieves superior performance across most of the popular benchmarks spanning both image understanding and generation tasks. To facilitate future research, we fully open-source our models, including code, model weights, training scripts, and pretraining and instruction tuning datasets.
Science-T2I: Addressing Scientific Illusions in Image Synthesis
Apr 17, 2025We present a novel approach to integrating scientific knowledge into generative models, enhancing their realism and consistency in image synthesis. First, we introduce Science-T2I, an expert-annotated adversarial dataset comprising adversarial 20k image pairs with 9k prompts, covering wide distinct scientific knowledge categories. Leveraging Science-T2I, we present SciScore, an end-to-end reward model that refines the assessment of generated images based on scientific knowledge, which is achieved by augmenting both the scientific comprehension and visual capabilities of pre-trained CLIP model. Additionally, based on SciScore, we propose a two-stage training framework, comprising a supervised fine-tuning phase and a masked online fine-tuning phase, to incorporate scientific knowledge into existing generative models. Through comprehensive experiments, we demonstrate the effectiveness of our framework in establishing new standards for evaluating the scientific realism of generated content. Specifically, SciScore attains performance comparable to human-level, demonstrating a 5% improvement similar to evaluations conducted by experienced human evaluators. Furthermore, by applying our proposed fine-tuning method to FLUX, we achieve a performance enhancement exceeding 50% on SciScore.