 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetaCLIP 2: A Worldwide Scaling Recipe
Jul 29, 2025
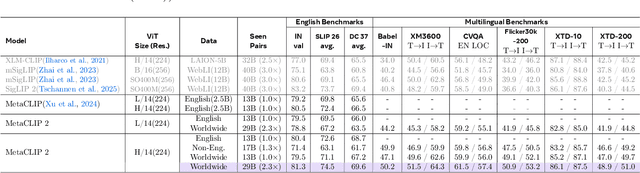


Contrastive Language-Image Pretraining (CLIP) is a popular foundation model, supporting from zero-shot classification, retrieval to encoders for multimodal large language models (MLLMs). Although CLIP is successfully trained on billion-scale image-text pairs from the English world, scaling CLIP's training further to learning from the worldwide web data is still challenging: (1) no curation method is available to handle data points from non-English world; (2) the English performance from existing multilingual CLIP is worse than its English-only counterpart, i.e., "curse of multilinguality" that is common in LLMs. Here, we present MetaCLIP 2, the first recipe training CLIP from scratch on worldwide web-scale image-text pairs. To generalize our findings, we conduct rigorous ablations with minimal changes that are necessary to address the above challenges and present a recipe enabling mutual benefits from English and non-English world data. In zero-shot ImageNet classification, MetaCLIP 2 ViT-H/14 surpasses its English-only counterpart by 0.8% and mSigLIP by 0.7%, and surprisingly sets new state-of-the-art without system-level confounding factors (e.g., translation, bespoke architecture changes) on multilingual benchmarks, such as CVQA with 57.4%, Babel-ImageNet with 50.2% and XM3600 with 64.3% on image-to-text retrieval.
Don't "Overthink" Passage Reranking: Is Reasoning Truly Necessary?
May 22, 2025With the growing success of reasoning models across complex natural language tasks, researchers in the Information Retrieval (IR) community have begun exploring how similar reasoning capabilities can be integrated into passage rerankers built on Large Language Models (LLMs). These methods typically employ an LLM to produce an explicit, step-by-step reasoning process before arriving at a final relevance prediction. But, does reasoning actually improve reranking accuracy? In this paper, we dive deeper into this question, studying the impact of the reasoning process by comparing reasoning-based pointwise rerankers (ReasonRR) to standard, non-reasoning pointwise rerankers (StandardRR) under identical training conditions, and observe that StandardRR generally outperforms ReasonRR. Building on this observation, we then study the importance of reasoning to ReasonRR by disabling its reasoning process (ReasonRR-NoReason), and find that ReasonRR-NoReason is surprisingly more effective than ReasonRR. Examining the cause of this result, our findings reveal that reasoning-based rerankers are limited by the LLM's reasoning process, which pushes it toward polarized relevance scores and thus fails to consider the partial relevance of passages, a key factor for the accuracy of pointwise rerankers.
Learning to Attribute with Attention
Apr 18, 2025Given a sequence of tokens generated by a language model, we may want to identify the preceding tokens that influence the model to generate this sequence. Performing such token attribution is expensive; a common approach is to ablate preceding tokens and directly measure their effects. To reduce the cost of token attribution, we revisit attention weights as a heuristic for how a language model uses previous tokens. Naive approaches to attribute model behavior with attention (e.g., averaging attention weights across attention heads to estimate a token's influence) have been found to be unreliable. To attain faithful attributions, we propose treating the attention weights of different attention heads as features. This way, we can learn how to effectively leverage attention weights for attribution (using signal from ablations). Our resulting method, Attribution with Attention (AT2), reliably performs on par with approaches that involve many ablations, while being significantly more efficient. To showcase the utility of AT2, we use it to prune less important parts of a provided context in a question answering setting, improving answer quality. We provide code for AT2 at https://github.com/MadryLab/AT2 .
SelfCite: Self-Supervised Alignment for Context Attribution in Large Language Models
Feb 13, 2025



We introduce SelfCite, a novel self-supervised approach that aligns LLMs to generate high-quality, fine-grained, sentence-level citations for the statements in their generated responses. Instead of only relying on costly and labor-intensive annotations, SelfCite leverages a reward signal provided by the LLM itself through context ablation: If a citation is necessary, removing the cited text from the context should prevent the same response; if sufficient, retaining the cited text alone should preserve the same response. This reward can guide the inference-time best-of-N sampling strategy to improve citation quality significantly, as well as be used in preference optimization to directly fine-tune the models for generating better citations. The effectiveness of SelfCite is demonstrated by increasing citation F1 up to 5.3 points on the LongBench-Cite benchmark across five long-form question answering tasks.
Zero-Shot Dense Retrieval with Embeddings from Relevance Feedback
Oct 28, 2024



Building effective dense retrieval systems remains difficult when relevance supervision is not available. Recent work has looked to overcome this challenge by using a Large Language Model (LLM) to generate hypothetical documents that can be used to find the closest real document. However, this approach relies solely on the LLM to have domain-specific knowledge relevant to the query, which may not be practical. Furthermore, generating hypothetical documents can be inefficient as it requires the LLM to generate a large number of tokens for each query. To address these challenges, we introduce Real Document Embeddings from Relevance Feedback (ReDE-RF). Inspired by relevance feedback, ReDE-RF proposes to re-frame hypothetical document generation as a relevance estimation task, using an LLM to select which documents should be used for nearest neighbor search. Through this re-framing, the LLM no longer needs domain-specific knowledge but only needs to judge what is relevant. Additionally, relevance estimation only requires the LLM to output a single token, thereby improving search latency. Our experiments show that ReDE-RF consistently surpasses state-of-the-art zero-shot dense retrieval methods across a wide range of low-resource retrieval datasets while also making significant improvements in latency per-query.
Lookback Lens: Detecting and Mitigating Contextual Hallucinations in Large Language Models Using Only Attention Maps
Jul 09, 2024When asked to summarize articles or answer questions given a passage, large language models (LLMs) can hallucinate details and respond with unsubstantiated answers that are inaccurate with respect to the input context. This paper describes a simple approach for detecting such contextual hallucinations. We hypothesize that contextual hallucinations are related to the extent to which an LLM attends to information in the provided context versus its own generations. Based on this intuition, we propose a simple hallucination detection model whose input features are given by the ratio of attention weights on the context versus newly generated tokens (for each attention head). We find that a linear classifier based on these lookback ratio features is as effective as a richer detector that utilizes the entire hidden states of an LLM or a text-based entailment model. The lookback ratio-based detector -- Lookback Lens -- is found to transfer across tasks and even models, allowing a detector that is trained on a 7B model to be applied (without retraining) to a larger 13B model. We further apply this detector to mitigate contextual hallucinations, and find that a simple classifier-guided decoding approach is able to reduce the amount of hallucination, for example by 9.6% in the XSum summarization task.
Found in the Middle: Calibrating Positional Attention Bias Improves Long Context Utilization
Jun 23, 2024



Large language models (LLMs), even when specifically trained to process long input contexts, struggle to capture relevant information located in the middle of their input. This phenomenon has been known as the lost-in-the-middle problem. In this work, we make three contributions. First, we set out to understand the factors that cause this phenomenon. In doing so, we establish a connection between lost-in-the-middle to LLMs' intrinsic attention bias: LLMs exhibit a U-shaped attention bias where the tokens at the beginning and at the end of its input receive higher attention, regardless of their relevance. Second, we mitigate this positional bias through a calibration mechanism, found-in-the-middle, that allows the model to attend to contexts faithfully according to their relevance, even though when they are in the middle. Third, we show found-in-the-middle not only achieves better performance in locating relevant information within a long context, but also eventually leads to improved retrieval-augmented generation (RAG) performance across various tasks, outperforming existing methods by up to 15 percentage points. These findings open up future directions in understanding LLM attention bias and its potential consequences.
A Large-Scale Evaluation of Speech Foundation Models
Apr 15, 2024The foundation model paradigm leverages a shared foundation model to achieve state-of-the-art (SOTA) performance for various tasks, requiring minimal downstream-specific modeling and data annotation. This approach has proven crucial in the field of Natural Language Processing (NLP). However, the speech processing community lacks a similar setup to explore the paradigm systematically. In this work, we establish the Speech processing Universal PERformance Benchmark (SUPERB) to study the effectiveness of the paradigm for speech. We propose a unified multi-tasking framework to address speech processing tasks in SUPERB using a frozen foundation model followed by task-specialized, lightweight prediction heads. Combining our results with community submissions, we verify that the foundation model paradigm is promising for speech, and our multi-tasking framework is simple yet effective, as the best-performing foundation model shows competitive generalizability across most SUPERB tasks. For reproducibility and extensibility, we have developed a long-term maintained platform that enables deterministic benchmarking, allows for result sharing via an online leaderboard, and promotes collaboration through a community-driven benchmark database to support new development cycles. Finally, we conduct a series of analyses to offer an in-depth understanding of SUPERB and speech foundation models, including information flows across tasks inside the models, the correctness of the weighted-sum benchmarking protocol and the statistical significance and robustness of the benchmark.
Curiosity-driven Red-teaming for Large Language Models
Feb 29, 2024



Large language models (LLMs) hold great potential for many natural language applications but risk generating incorrect or toxic content. To probe when an LLM generates unwanted content, the current paradigm is to recruit a \textit{red team} of human testers to design input prompts (i.e., test cases) that elicit undesirable responses from LLMs. However, relying solely on human testers is expensive and time-consuming. Recent works automate red teaming by training a separate red team LLM with reinforcement learning (RL) to generate test cases that maximize the chance of eliciting undesirable responses from the target LLM. However, current RL methods are only able to generate a small number of effective test cases resulting in a low coverage of the span of prompts that elicit undesirable responses from the target LLM. To overcome this limitation, we draw a connection between the problem of increasing the coverage of generated test cases and the well-studied approach of curiosity-driven exploration that optimizes for novelty. Our method of curiosity-driven red teaming (CRT) achieves greater coverage of test cases while mantaining or increasing their effectiveness compared to existing methods. Our method, CRT successfully provokes toxic responses from LLaMA2 model that has been heavily fine-tuned using human preferences to avoid toxic outputs. Code is available at \url{https://github.com/Improbable-AI/curiosity_redteam}
SpeechDPR: End-to-End Spoken Passage Retrieval for Open-Domain Spoken Question Answering
Jan 24, 2024


Spoken Question Answering (SQA) is essential for machines to reply to user's question by finding the answer span within a given spoken passage. SQA has been previously achieved without ASR to avoid recognition errors and Out-of-Vocabulary (OOV) problems. However, the real-world problem of Open-domain SQA (openSQA), in which the machine needs to first retrieve passages that possibly contain the answer from a spoken archive in addition, was never considered. This paper proposes the first known end-to-end framework, Speech Dense Passage Retriever (SpeechDPR), for the retrieval component of the openSQA problem. SpeechDPR learns a sentence-level semantic representation by distilling knowledge from the cascading model of unsupervised ASR (UASR) and text dense retriever (TDR). No manually transcribed speech data is needed. Initial experiments showed performance comparable to the cascading model of UASR and TDR, and significantly better when UASR was poor, verifying this approach is more robust to speech recognition errors.