 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDDPO-VC: Speaker De-Identification via Diffusion Denoising Policy Optimization
Jun 13, 2026A key challenge of speaker de-identification is the balance between privacy and utility. Many utility variables, such as the cognitive health status of the speaker, are correlated with the privacy variable, such as the speaker identity, violating the independence assumption held by the disentanglement-based approaches, causing leakage of private information and the loss of useful information for downstream tasks. To tackle this challenge, we propose a general framework, DDPO-VC, for speaker de-identification through reinforcement learning-based post-training with diffusion models. Learning from reward signals combining knowledge from privacy-focused and utility-focused teachers, our method outperforms various strong \deid/ methods in both privacy preservation and cognitive utility on two commonly used dementia speech benchmarks. Please check out our code\footnote{\href{https://github.com/cactuswiththoughts/DDPO-VC}{https://github.com/cactuswiththoughts/DDPO-VC}} and demo\footnote{\href{https://cactuswiththoughts.github.io/SpeakerDeID-Demo/}{https://cactuswiththoughts.github.io/SpeakerDeID-Demo/}}.
Overcoming State Inertia in Full-Duplex Spoken Language Models via Activation Steering
Jun 09, 2026Full-duplex spoken language models (FD-SLMs) enable seamless speech interaction by allowing models to listen and speak simultaneously, yet the internal mechanism by which they coordinate listening and speaking remains underexplored. We analyze the predictive behavior encoded in FD-SLM hidden representations and find that they exhibit stream-specific predictive patterns: during listening, they preferentially predict the incoming user stream, whereas during speaking, they preferentially predict the model output stream. Building on this observation, we show that FD-SLMs dynamically modulate their internal predictive focus between two states: a generative state aligned with model output generation and a perceptive state aligned with incoming user input. However, this modulation can lag behind abrupt changes in conversational context. During user interruptions, the model remains transiently biased toward the generative state before transitioning into the perceptive state, causing it to miss the beginning of the incoming input. We term this delayed internal transition state inertia. To quantify its downstream impact, we introduce the Zero-Buffer Benchmark (ZBB), a diagnostic benchmark for evaluating immediate interruption comprehension when user speech begins abruptly. We evaluate this setting using response correctness and initial-word occurrence rate (IWOR). Finally, we mitigate state inertia through activation steering with a perception vector, a training-free intervention with little additional computational overhead. Across multiple state-of-the-art FD-SLMs, activation steering substantially improves interruption handling; for example, on PersonaPlex, it improves correctness from 28% to 45% and IWOR from 40% to 72% without any fine-tuning.
USAD 2.0: Scaling Representation Distillation for Universal Audio Understanding
Jun 04, 2026Audio encoders are critical to modern audio applications as large language models (LLMs) increasingly rely on a single encoder for diverse inputs. While self-supervised learning (SSL) has yielded strong domain-specific encoders like speech or music experts, multi-domain approaches like USAD and SPEAR remain limited in coverage and evaluation. Recent studies also suggest supervised encoders align better with audio LLMs. We present USAD 2.0, a universal encoder integrating knowledge from both SSL and supervised foundation models. USAD 2.0 introduces domain-aware distillation to address teacher mismatch, extends coverage to the music domain, and adds second-stage supervised distillation for downstream use. We further scale the model to one billion parameters via depth scaling. Experiments show USAD 2.0 achieves strong or state-of-the-art performance across probing and LLM-based evaluations.
TiCo: Time-Controllable Training for Spoken Dialogue Models
Mar 23, 2026We propose TiCo, a simple post-training method for enabling spoken dialogue models (SDMs) to follow time-constrained instructions and generate responses with controllable duration. This capability is valuable for real-world spoken language systems such as voice assistants and interactive agents, where controlling response duration can improve interaction quality. However, despite their strong ability to generate natural spoken responses, existing models lack time awareness and struggle to follow duration-related instructions (e.g., "Please generate a response lasting about 15 seconds"). Through an empirical evaluation of both open-source and commercial SDMs, we show that they frequently fail to satisfy such time-control requirements. TiCo addresses this limitation by enabling models to estimate elapsed speaking time during generation through Spoken Time Markers (STM) (e.g., <10.6 seconds>). These markers help the model maintain awareness of time and adjust the remaining content to meet the target duration. TiCo is simple and efficient: it requires only a small amount of data and no additional question-answer pairs, relying instead on self-generation and reinforcement learning. Experimental results show that TiCo significantly improves adherence to duration constraints while preserving response quality.
TaigiSpeech: A Low-Resource Real-World Speech Intent Dataset and Preliminary Results with Scalable Data Mining In-the-Wild
Mar 23, 2026Speech technologies have advanced rapidly and serve diverse populations worldwide. However, many languages remain underrepresented due to limited resources. In this paper, we introduce \textbf{TaigiSpeech}, a real-world speech intent dataset in Taiwanese Taigi (aka Taiwanese Hokkien/Southern Min), which is a low-resource and primarily spoken language. The dataset is collected from older adults, comprising 21 speakers with a total of 3k utterances. It is designed for practical intent detection scenarios, including healthcare and home assistant applications. To address the scarcity of labeled data, we explore two data mining strategies with two levels of supervision: keyword match data mining with LLM pseudo labeling via an intermediate language and an audio-visual framework that leverages multimodal cues with minimal textual supervision. This design enables scalable dataset construction for low-resource and unwritten spoken languages. TaigiSpeech will be released under the CC BY 4.0 license to facilitate broad adoption and research on low-resource and unwritten languages. The project website and the dataset can be found on https://kwchang.org/taigispeech.
Beyond Single-Shot: Multi-step Tool Retrieval via Query Planning
Jan 12, 2026LLM agents operating over massive, dynamic tool libraries rely on effective retrieval, yet standard single-shot dense retrievers struggle with complex requests. These failures primarily stem from the disconnect between abstract user goals and technical documentation, and the limited capacity of fixed-size embeddings to model combinatorial tool compositions. To address these challenges, we propose TOOLQP, a lightweight framework that models retrieval as iterative query planning. Instead of single-shot matching, TOOLQP decomposes instructions into sub-tasks and dynamically generates queries to interact with the retriever, effectively bridging the semantic gap by targeting the specific sub-tasks required for composition. We train TOOLQP using synthetic query trajectories followed by optimization via Reinforcement Learning with Verifiable Rewards (RLVR). Experiments demonstrate that TOOLQP achieves state-of-the-art performance, exhibiting superior zero-shot generalization, robustness across diverse retrievers, and significant improvements in downstream agentic execution.
TreePS-RAG: Tree-based Process Supervision for Reinforcement Learning in Agentic RAG
Jan 11, 2026Agentic retrieval-augmented generation (RAG) formulates question answering as a multi-step interaction between reasoning and information retrieval, and has recently been advanced by reinforcement learning (RL) with outcome-based supervision. While effective, relying solely on sparse final rewards limits step-wise credit assignment and provides weak guidance for intermediate reasoning and actions. Recent efforts explore process-level supervision, but typically depend on offline constructed training data, which risks distribution shift, or require costly intermediate annotations. We present TreePS-RAG, an online, tree-based RL framework for agentic RAG that enables step-wise credit assignment while retaining standard outcome-only rewards. Our key insight is to model agentic RAG reasoning as a rollout tree, where each reasoning step naturally maps to a node. This tree structure allows step utility to be estimated via Monte Carlo estimation over its descendant outcomes, yielding fine-grained process advantages without requiring intermediate labels. To make this paradigm practical, we introduce an efficient online tree construction strategy that preserves exploration diversity under a constrained computational budget. With a rollout cost comparable to strong baselines like Search-R1, experiments on seven multi-hop and general QA benchmarks across multiple model scales show that TreePS-RAG consistently and significantly outperforms both outcome-supervised and leading process-supervised RL methods.
LibriVAD: A Scalable Open Dataset with Deep Learning Benchmarks for Voice Activity Detection
Dec 19, 2025Robust Voice Activity Detection (VAD) remains a challenging task, especially under noisy, diverse, and unseen acoustic conditions. Beyond algorithmic development, a key limitation in advancing VAD research is the lack of large-scale, systematically controlled, and publicly available datasets. To address this, we introduce LibriVAD - a scalable open-source dataset derived from LibriSpeech and augmented with diverse real-world and synthetic noise sources. LibriVAD enables systematic control over speech-to-noise ratio, silence-to-speech ratio (SSR), and noise diversity, and is released in three sizes (15 GB, 150 GB, and 1.5 TB) with two variants (LibriVAD-NonConcat and LibriVAD-Concat) to support different experimental setups. We benchmark multiple feature-model combinations, including waveform, Mel-Frequency Cepstral Coefficients (MFCC), and Gammatone filter bank cepstral coefficients, and introduce the Vision Transformer (ViT) architecture for VAD. Our experiments show that ViT with MFCC features consistently outperforms established VAD models such as boosted deep neural network and convolutional long short-term memory deep neural network across seen, unseen, and out-of-distribution (OOD) conditions, including evaluation on the real-world VOiCES dataset. We further analyze the impact of dataset size and SSR on model generalization, experimentally showing that scaling up dataset size and balancing SSR noticeably and consistently enhance VAD performance under OOD conditions. All datasets, trained models, and code are publicly released to foster reproducibility and accelerate progress in VAD research.
MetaCLIP 2: A Worldwide Scaling Recipe
Jul 29, 2025
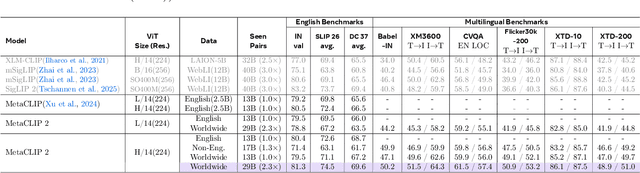


Contrastive Language-Image Pretraining (CLIP) is a popular foundation model, supporting from zero-shot classification, retrieval to encoders for multimodal large language models (MLLMs). Although CLIP is successfully trained on billion-scale image-text pairs from the English world, scaling CLIP's training further to learning from the worldwide web data is still challenging: (1) no curation method is available to handle data points from non-English world; (2) the English performance from existing multilingual CLIP is worse than its English-only counterpart, i.e., "curse of multilinguality" that is common in LLMs. Here, we present MetaCLIP 2, the first recipe training CLIP from scratch on worldwide web-scale image-text pairs. To generalize our findings, we conduct rigorous ablations with minimal changes that are necessary to address the above challenges and present a recipe enabling mutual benefits from English and non-English world data. In zero-shot ImageNet classification, MetaCLIP 2 ViT-H/14 surpasses its English-only counterpart by 0.8% and mSigLIP by 0.7%, and surprisingly sets new state-of-the-art without system-level confounding factors (e.g., translation, bespoke architecture changes) on multilingual benchmarks, such as CVQA with 57.4%, Babel-ImageNet with 50.2% and XM3600 with 64.3% on image-to-text retrieval.
Beyond Context Limits: Subconscious Threads for Long-Horizon Reasoning
Jul 22, 2025To break the context limits of large language models (LLMs) that bottleneck reasoning accuracy and efficiency, we propose the Thread Inference Model (TIM), a family of LLMs trained for recursive and decompositional problem solving, and TIMRUN, an inference runtime enabling long-horizon structured reasoning beyond context limits. Together, TIM hosted on TIMRUN supports virtually unlimited working memory and multi-hop tool calls within a single language model inference, overcoming output limits, positional-embedding constraints, and GPU-memory bottlenecks. Performance is achieved by modeling natural language as reasoning trees measured by both length and depth instead of linear sequences. The reasoning trees consist of tasks with thoughts, recursive subtasks, and conclusions based on the concept we proposed in Schroeder et al, 2025. During generation, we maintain a working memory that retains only the key-value states of the most relevant context tokens, selected by a rule-based subtask-pruning mechanism, enabling reuse of positional embeddings and GPU memory pages throughout reasoning. Experimental results show that our system sustains high inference throughput, even when manipulating up to 90% of the KV cache in GPU memory. It also delivers accurate reasoning on mathematical tasks and handles information retrieval challenges that require long-horizon reasoning and multi-hop tool use.