 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeV-GRPO: Online Reinforcement Learning for Denoising Generative Models Is Easier than You Think
Apr 25, 2026Aligning denoising generative models with human preferences or verifiable rewards remains a key challenge. While policy-gradient online reinforcement learning (RL) offers a principled post-training framework, its direct application is hindered by the intractable likelihoods of these models. Prior work therefore either optimizes an induced Markov decision process (MDP) over sampling trajectories, which is stable but inefficient, or uses likelihood surrogates based on the diffusion evidence lower bound (ELBO), which have so far underperformed on visual generation. Our key insight is that the ELBO-based approach can, in fact, be made both stable and efficient. By reducing surrogate variance and controlling gradient steps, we show that this approach can beat MDP-based methods. To this end, we introduce Variational GRPO (V-GRPO), a method that integrates ELBO-based surrogates with the Group Relative Policy Optimization (GRPO) algorithm, alongside a set of simple yet essential techniques. Our method is easy to implement, aligns with pretraining objectives, and avoids the limitations of MDP-based methods. V-GRPO achieves state-of-the-art performance in text-to-image synthesis, while delivering a $2\times$ speedup over MixGRPO and a $3\times$ speedup over DiffusionNFT.
Scaling Text-to-Image Diffusion Transformers with Representation Autoencoders
Jan 22, 2026Representation Autoencoders (RAEs) have shown distinct advantages in diffusion modeling on ImageNet by training in high-dimensional semantic latent spaces. In this work, we investigate whether this framework can scale to large-scale, freeform text-to-image (T2I) generation. We first scale RAE decoders on the frozen representation encoder (SigLIP-2) beyond ImageNet by training on web, synthetic, and text-rendering data, finding that while scale improves general fidelity, targeted data composition is essential for specific domains like text. We then rigorously stress-test the RAE design choices originally proposed for ImageNet. Our analysis reveals that scaling simplifies the framework: while dimension-dependent noise scheduling remains critical, architectural complexities such as wide diffusion heads and noise-augmented decoding offer negligible benefits at scale Building on this simplified framework, we conduct a controlled comparison of RAE against the state-of-the-art FLUX VAE across diffusion transformer scales from 0.5B to 9.8B parameters. RAEs consistently outperform VAEs during pretraining across all model scales. Further, during finetuning on high-quality datasets, VAE-based models catastrophically overfit after 64 epochs, while RAE models remain stable through 256 epochs and achieve consistently better performance. Across all experiments, RAE-based diffusion models demonstrate faster convergence and better generation quality, establishing RAEs as a simpler and stronger foundation than VAEs for large-scale T2I generation. Additionally, because both visual understanding and generation can operate in a shared representation space, the multimodal model can directly reason over generated latents, opening new possibilities for unified models.
Exploring the Deep Fusion of Large Language Models and Diffusion Transformers for Text-to-Image Synthesis
May 15, 2025



This paper does not describe a new method; instead, it provides a thorough exploration of an important yet understudied design space related to recent advances in text-to-image synthesis -- specifically, the deep fusion of large language models (LLMs) and diffusion transformers (DiTs) for multi-modal generation. Previous studies mainly focused on overall system performance rather than detailed comparisons with alternative methods, and key design details and training recipes were often left undisclosed. These gaps create uncertainty about the real potential of this approach. To fill these gaps, we conduct an empirical study on text-to-image generation, performing controlled comparisons with established baselines, analyzing important design choices, and providing a clear, reproducible recipe for training at scale. We hope this work offers meaningful data points and practical guidelines for future research in multi-modal generation.
VividMed: Vision Language Model with Versatile Visual Grounding for Medicine
Oct 16, 2024



Recent advancements in Vision Language Models (VLMs) have demonstrated remarkable promise in generating visually grounded responses. However, their application in the medical domain is hindered by unique challenges. For instance, most VLMs rely on a single method of visual grounding, whereas complex medical tasks demand more versatile approaches. Additionally, while most VLMs process only 2D images, a large portion of medical images are 3D. The lack of medical data further compounds these obstacles. To address these challenges, we present VividMed, a vision language model with versatile visual grounding for medicine. Our model supports generating both semantic segmentation masks and instance-level bounding boxes, and accommodates various imaging modalities, including both 2D and 3D data. We design a three-stage training procedure and an automatic data synthesis pipeline based on open datasets and models. Besides visual grounding tasks, VividMed also excels in other common downstream tasks, including Visual Question Answering (VQA) and report generation. Ablation studies empirically show that the integration of visual grounding ability leads to improved performance on these tasks. Our code is publicly available at https://github.com/function2-llx/MMMM.
CORE4D: A 4D Human-Object-Human Interaction Dataset for Collaborative Object REarrangement
Jun 27, 2024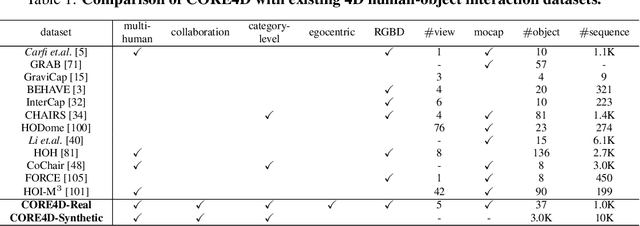



Understanding how humans cooperatively rearrange household objects is critical for VR/AR and human-robot interaction. However, in-depth studies on modeling these behaviors are under-researched due to the lack of relevant datasets. We fill this gap by presenting CORE4D, a novel large-scale 4D human-object-human interaction dataset focusing on collaborative object rearrangement, which encompasses diverse compositions of various object geometries, collaboration modes, and 3D scenes. With 1K human-object-human motion sequences captured in the real world, we enrich CORE4D by contributing an iterative collaboration retargeting strategy to augment motions to a variety of novel objects. Leveraging this approach, CORE4D comprises a total of 11K collaboration sequences spanning 3K real and virtual object shapes. Benefiting from extensive motion patterns provided by CORE4D, we benchmark two tasks aiming at generating human-object interaction: human-object motion forecasting and interaction synthesis. Extensive experiments demonstrate the effectiveness of our collaboration retargeting strategy and indicate that CORE4D has posed new challenges to existing human-object interaction generation methodologies. Our dataset and code are available at https://github.com/leolyliu/CORE4D-Instructions.
ObscurePrompt: Jailbreaking Large Language Models via Obscure Input
Jun 19, 2024



Recently, Large Language Models (LLMs) have garnered significant attention for their exceptional natural language processing capabilities. However, concerns about their trustworthiness remain unresolved, particularly in addressing "jailbreaking" attacks on aligned LLMs. Previous research predominantly relies on scenarios with white-box LLMs or specific and fixed prompt templates, which are often impractical and lack broad applicability. In this paper, we introduce a straightforward and novel method, named ObscurePrompt, for jailbreaking LLMs, inspired by the observed fragile alignments in Out-of-Distribution (OOD) data. Specifically, we first formulate the decision boundary in the jailbreaking process and then explore how obscure text affects LLM's ethical decision boundary. ObscurePrompt starts with constructing a base prompt that integrates well-known jailbreaking techniques. Powerful LLMs are then utilized to obscure the original prompt through iterative transformations, aiming to bolster the attack's robustness. Comprehensive experiments show that our approach substantially improves upon previous methods in terms of attack effectiveness, maintaining efficacy against two prevalent defense mechanisms. We believe that our work can offer fresh insights for future research on enhancing LLM alignment.
Pre-trained Universal Medical Image Transformer
Dec 12, 2023Self-supervised learning has emerged as a viable method to leverage the abundance of unlabeled medical imaging data, addressing the challenge of labeled data scarcity in medical image analysis. In particular, masked image modeling (MIM) with visual token reconstruction has shown promising results in the general computer vision (CV) domain and serves as a candidate for medical image analysis. However, the presence of heterogeneous 2D and 3D medical images often limits the volume and diversity of training data that can be effectively used for a single model structure. In this work, we propose a spatially adaptive convolution (SAC) module, which adaptively adjusts convolution parameters based on the voxel spacing of the input images. Employing this SAC module, we build a universal visual tokenizer and a universal Vision Transformer (ViT) capable of effectively processing a wide range of medical images with various imaging modalities and spatial properties. Moreover, in order to enhance the robustness of the visual tokenizer's reconstruction objective for MIM, we suggest to generalize the discrete token output of the visual tokenizer to a probabilistic soft token. We show that the generalized soft token representation can be effectively integrated with the prior distribution regularization through a constructive interpretation. As a result, we pre-train a universal visual tokenizer followed by a universal ViT via visual token reconstruction on 55 public medical image datasets, comprising over 9 million 2D slices (including over 48,000 3D images). This represents the largest, most comprehensive, and diverse dataset for pre-training 3D medical image models to our knowledge. Experimental results on downstream medical image classification and segmentation tasks demonstrate the superior performance of our model and improved label efficiency.