 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMull-Tokens: Modality-Agnostic Latent Thinking
Dec 11, 2025



Reasoning goes beyond language; the real world requires reasoning about space, time, affordances, and much more that words alone cannot convey. Existing multimodal models exploring the potential of reasoning with images are brittle and do not scale. They rely on calling specialist tools, costly generation of images, or handcrafted reasoning data to switch between text and image thoughts. Instead, we offer a simpler alternative -- Mull-Tokens -- modality-agnostic latent tokens pre-trained to hold intermediate information in either image or text modalities to let the model think free-form towards the correct answer. We investigate best practices to train Mull-Tokens inspired by latent reasoning frameworks. We first train Mull-Tokens using supervision from interleaved text-image traces, and then fine-tune without any supervision by only using the final answers. Across four challenging spatial reasoning benchmarks involving tasks such as solving puzzles and taking different perspectives, we demonstrate that Mull-Tokens improve upon several baselines utilizing text-only reasoning or interleaved image-text reasoning, achieving a +3% average improvement and up to +16% on a puzzle solving reasoning-heavy split compared to our strongest baseline. Adding to conversations around challenges in grounding textual and visual reasoning, Mull-Tokens offers a simple solution to abstractly think in multiple modalities.
SIMS-V: Simulated Instruction-Tuning for Spatial Video Understanding
Nov 06, 2025Despite impressive high-level video comprehension, multimodal language models struggle with spatial reasoning across time and space. While current spatial training approaches rely on real-world video data, obtaining diverse footage with precise spatial annotations remains a bottleneck. To alleviate this bottleneck, we present SIMS-V -- a systematic data-generation framework that leverages the privileged information of 3D simulators to create spatially-rich video training data for multimodal language models. Using this framework, we investigate which properties of simulated data drive effective real-world transfer through systematic ablations of question types, mixes, and scales. We identify a minimal set of three question categories (metric measurement, perspective-dependent reasoning, and temporal tracking) that prove most effective for developing transferable spatial intelligence, outperforming comprehensive coverage despite using fewer question types. These insights enable highly efficient training: our 7B-parameter video LLM fine-tuned on just 25K simulated examples outperforms the larger 72B baseline and achieves competitive performance with proprietary models on rigorous real-world spatial reasoning benchmarks. Our approach demonstrates robust generalization, maintaining performance on general video understanding while showing substantial improvements on embodied and real-world spatial tasks.
GraspMolmo: Generalizable Task-Oriented Grasping via Large-Scale Synthetic Data Generation
May 19, 2025We present GrasMolmo, a generalizable open-vocabulary task-oriented grasping (TOG) model. GraspMolmo predicts semantically appropriate, stable grasps conditioned on a natural language instruction and a single RGB-D frame. For instance, given "pour me some tea", GraspMolmo selects a grasp on a teapot handle rather than its body. Unlike prior TOG methods, which are limited by small datasets, simplistic language, and uncluttered scenes, GraspMolmo learns from PRISM, a novel large-scale synthetic dataset of 379k samples featuring cluttered environments and diverse, realistic task descriptions. We fine-tune the Molmo visual-language model on this data, enabling GraspMolmo to generalize to novel open-vocabulary instructions and objects. In challenging real-world evaluations, GraspMolmo achieves state-of-the-art results, with a 70% prediction success on complex tasks, compared to the 35% achieved by the next best alternative. GraspMolmo also successfully demonstrates the ability to predict semantically correct bimanual grasps zero-shot. We release our synthetic dataset, code, model, and benchmarks to accelerate research in task-semantic robotic manipulation, which, along with videos, are available at https://abhaybd.github.io/GraspMolmo/.
SAT: Spatial Aptitude Training for Multimodal Language Models
Dec 10, 2024



Spatial perception is a fundamental component of intelligence. While many studies highlight that large multimodal language models (MLMs) struggle to reason about space, they only test for static spatial reasoning, such as categorizing the relative positions of objects. Meanwhile, real-world deployment requires dynamic capabilities like perspective-taking and egocentric action recognition. As a roadmap to improving spatial intelligence, we introduce SAT, Spatial Aptitude Training, which goes beyond static relative object position questions to the more dynamic tasks. SAT contains 218K question-answer pairs for 22K synthetic scenes across a training and testing set. Generated using a photo-realistic physics engine, our dataset can be arbitrarily scaled and easily extended to new actions, scenes, and 3D assets. We find that even MLMs that perform relatively well on static questions struggle to accurately answer dynamic spatial questions. Further, we show that SAT instruction-tuning data improves not only dynamic spatial reasoning on SAT, but also zero-shot performance on existing real-image spatial benchmarks: $23\%$ on CVBench, $8\%$ on the harder BLINK benchmark, and $18\%$ on VSR. When instruction-tuned on SAT, our 13B model matches larger proprietary MLMs like GPT4-V and Gemini-3-1.0 in spatial reasoning. Our data/code is available at http://arijitray1993.github.io/SAT/ .
BloomVQA: Assessing Hierarchical Multi-modal Comprehension
Dec 20, 2023



We propose a novel VQA dataset, based on picture stories designed for educating young children, that aims to facilitate comprehensive evaluation and characterization of vision-language models on comprehension tasks. Unlike current VQA datasets that often focus on fact-based memorization and simple reasoning tasks without principled scientific grounding, we collect data containing tasks reflecting different levels of comprehension and underlying cognitive processes, as laid out in Bloom's Taxonomy, a classic framework widely adopted in education research. The proposed BloomVQA dataset can be mapped to a hierarchical graph-based representation of visual stories, enabling automatic data augmentation and novel measures characterizing model consistency across the underlying taxonomy. We demonstrate graded evaluation and reliability analysis based on our proposed consistency metrics on state-of-the-art vision-language models. Our results suggest that, while current models achieve the most gain on low-level comprehension tasks, they generally fall short on high-level tasks requiring more advanced comprehension and cognitive skills, as 38.0% drop in VQA accuracy is observed comparing lowest and highest level tasks. Furthermore, current models show consistency patterns misaligned with human comprehension in various scenarios, suggesting emergent structures of model behaviors.
Lasagna: Layered Score Distillation for Disentangled Object Relighting
Nov 30, 2023



Professional artists, photographers, and other visual content creators use object relighting to establish their photo's desired effect. Unfortunately, manual tools that allow relighting have a steep learning curve and are difficult to master. Although generative editing methods now enable some forms of image editing, relighting is still beyond today's capabilities; existing methods struggle to keep other aspects of the image -- colors, shapes, and textures -- consistent after the edit. We propose Lasagna, a method that enables intuitive text-guided relighting control. Lasagna learns a lighting prior by using score distillation sampling to distill the prior of a diffusion model, which has been finetuned on synthetic relighting data. To train Lasagna, we curate a new synthetic dataset ReLiT, which contains 3D object assets re-lit from multiple light source locations. Despite training on synthetic images, quantitative results show that Lasagna relights real-world images while preserving other aspects of the input image, outperforming state-of-the-art text-guided image editing methods. Lasagna enables realistic and controlled results on natural images and digital art pieces and is preferred by humans over other methods in over 91% of cases. Finally, we demonstrate the versatility of our learning objective by extending it to allow colorization, another form of image editing.
Socratis: Are large multimodal models emotionally aware?
Sep 05, 2023



Existing emotion prediction benchmarks contain coarse emotion labels which do not consider the diversity of emotions that an image and text can elicit in humans due to various reasons. Learning diverse reactions to multimodal content is important as intelligent machines take a central role in generating and delivering content to society. To address this gap, we propose Socratis, a societal reactions benchmark, where each image-caption (IC) pair is annotated with multiple emotions and the reasons for feeling them. Socratis contains 18K free-form reactions for 980 emotions on 2075 image-caption pairs from 5 widely-read news and image-caption (IC) datasets. We benchmark the capability of state-of-the-art multimodal large language models to generate the reasons for feeling an emotion given an IC pair. Based on a preliminary human study, we observe that humans prefer human-written reasons over 2 times more often than machine-generated ones. This shows our task is harder than standard generation tasks because it starkly contrasts recent findings where humans cannot tell apart machine vs human-written news articles, for instance. We further see that current captioning metrics based on large vision-language models also fail to correlate with human preferences. We hope that these findings and our benchmark will inspire further research on training emotionally aware models.
COLA: How to adapt vision-language models to Compose Objects Localized with Attributes?
May 05, 2023Compositional reasoning is a hallmark of human visual intelligence; yet despite the size of large vision-language models, they struggle to represent simple compositions by combining objects with their attributes. To measure this lack of compositional capability, we design Cola, a text-to-image retrieval benchmark to Compose Objects Localized with Attributes. Using Cola as a testbed, we explore modeling designs to adapt pre-trained vision-language models to reason compositionally about multiple attributes attached to multiple objects. We explore 6 finetuning strategies on 2 seminal vision-language models, using 3 finetuning datasets and 2 test benchmarks (Cola and CREPE). Surprisingly, our optimal finetuning strategy improves a 151M parameter CLIP, which disjointly encodes image and language during pretraining, to perform as well as a 241M parameter FLAVA, which uses a multi-modal transformer encoder during pretraining to attend over both vision and language modalities. This optimal finetuning strategy is a lightweight multi-modal adapter that jointly attends over both image and language features generated by the pretrained model. We show this works better than common strategies such as prompt/fine-tuning, or tuning a comparable number of unimodal layers.
Language-Guided Audio-Visual Source Separation via Trimodal Consistency
Mar 28, 2023



We propose a self-supervised approach for learning to perform audio source separation in videos based on natural language queries, using only unlabeled video and audio pairs as training data. A key challenge in this task is learning to associate the linguistic description of a sound-emitting object to its visual features and the corresponding components of the audio waveform, all without access to annotations during training. To overcome this challenge, we adapt off-the-shelf vision-language foundation models to provide pseudo-target supervision via two novel loss functions and encourage a stronger alignment between the audio, visual and natural language modalities. During inference, our approach can separate sounds given text, video and audio input, or given text and audio input alone. We demonstrate the effectiveness of our self-supervised approach on three audio-visual separation datasets, including MUSIC, SOLOS and AudioSet, where we outperform state-of-the-art strongly supervised approaches despite not using object detectors or text labels during training.
Improving Users' Mental Model with Attention-directed Counterfactual Edits
Oct 15, 2021


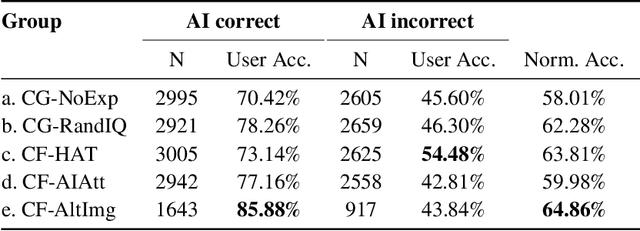
In the domain of Visual Question Answering (VQA), studies have shown improvement in users' mental model of the VQA system when they are exposed to examples of how these systems answer certain Image-Question (IQ) pairs. In this work, we show that showing controlled counterfactual image-question examples are more effective at improving the mental model of users as compared to simply showing random examples. We compare a generative approach and a retrieval-based approach to show counterfactual examples. We use recent advances in generative adversarial networks (GANs) to generate counterfactual images by deleting and inpainting certain regions of interest in the image. We then expose users to changes in the VQA system's answer on those altered images. To select the region of interest for inpainting, we experiment with using both human-annotated attention maps and a fully automatic method that uses the VQA system's attention values. Finally, we test the user's mental model by asking them to predict the model's performance on a test counterfactual image. We note an overall improvement in users' accuracy to predict answer change when shown counterfactual explanations. While realistic retrieved counterfactuals obviously are the most effective at improving the mental model, we show that a generative approach can also be equally effective.