 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Evolving Landscape of Generative Large Language Models and Traditional Natural Language Processing in Medicine
May 15, 2025Natural language processing (NLP) has been traditionally applied to medicine, and generative large language models (LLMs) have become prominent recently. However, the differences between them across different medical tasks remain underexplored. We analyzed 19,123 studies, finding that generative LLMs demonstrate advantages in open-ended tasks, while traditional NLP dominates in information extraction and analysis tasks. As these technologies advance, ethical use of them is essential to ensure their potential in medical applications.
Seed1.5-VL Technical Report
May 11, 2025



We present Seed1.5-VL, a vision-language foundation model designed to advance general-purpose multimodal understanding and reasoning. Seed1.5-VL is composed with a 532M-parameter vision encoder and a Mixture-of-Experts (MoE) LLM of 20B active parameters. Despite its relatively compact architecture, it delivers strong performance across a wide spectrum of public VLM benchmarks and internal evaluation suites, achieving the state-of-the-art performance on 38 out of 60 public benchmarks. Moreover, in agent-centric tasks such as GUI control and gameplay, Seed1.5-VL outperforms leading multimodal systems, including OpenAI CUA and Claude 3.7. Beyond visual and video understanding, it also demonstrates strong reasoning abilities, making it particularly effective for multimodal reasoning challenges such as visual puzzles. We believe these capabilities will empower broader applications across diverse tasks. In this report, we mainly provide a comprehensive review of our experiences in building Seed1.5-VL across model design, data construction, and training at various stages, hoping that this report can inspire further research. Seed1.5-VL is now accessible at https://www.volcengine.com/ (Volcano Engine Model ID: doubao-1-5-thinking-vision-pro-250428)
Towards Large-scale Generative Ranking
May 08, 2025



Generative recommendation has recently emerged as a promising paradigm in information retrieval. However, generative ranking systems are still understudied, particularly with respect to their effectiveness and feasibility in large-scale industrial settings. This paper investigates this topic at the ranking stage of Xiaohongshu's Explore Feed, a recommender system that serves hundreds of millions of users. Specifically, we first examine how generative ranking outperforms current industrial recommenders. Through theoretical and empirical analyses, we find that the primary improvement in effectiveness stems from the generative architecture, rather than the training paradigm. To facilitate efficient deployment of generative ranking, we introduce GenRank, a novel generative architecture for ranking. We validate the effectiveness and efficiency of our solution through online A/B experiments. The results show that GenRank achieves significant improvements in user satisfaction with nearly equivalent computational resources compared to the existing production system.
Weakly-supervised Audio Temporal Forgery Localization via Progressive Audio-language Co-learning Network
May 03, 2025Audio temporal forgery localization (ATFL) aims to find the precise forgery regions of the partial spoof audio that is purposefully modified. Existing ATFL methods rely on training efficient networks using fine-grained annotations, which are obtained costly and challenging in real-world scenarios. To meet this challenge, in this paper, we propose a progressive audio-language co-learning network (LOCO) that adopts co-learning and self-supervision manners to prompt localization performance under weak supervision scenarios. Specifically, an audio-language co-learning module is first designed to capture forgery consensus features by aligning semantics from temporal and global perspectives. In this module, forgery-aware prompts are constructed by using utterance-level annotations together with learnable prompts, which can incorporate semantic priors into temporal content features dynamically. In addition, a forgery localization module is applied to produce forgery proposals based on fused forgery-class activation sequences. Finally, a progressive refinement strategy is introduced to generate pseudo frame-level labels and leverage supervised semantic contrastive learning to amplify the semantic distinction between real and fake content, thereby continuously optimizing forgery-aware features. Extensive experiments show that the proposed LOCO achieves SOTA performance on three public benchmarks.
HealthGenie: Empowering Users with Healthy Dietary Guidance through Knowledge Graph and Large Language Models
Apr 20, 2025Seeking dietary guidance often requires navigating complex professional knowledge while accommodating individual health conditions. Knowledge Graphs (KGs) offer structured and interpretable nutritional information, whereas Large Language Models (LLMs) naturally facilitate conversational recommendation delivery. In this paper, we present HealthGenie, an interactive system that combines the strengths of LLMs and KGs to provide personalized dietary recommendations along with hierarchical information visualization for a quick and intuitive overview. Upon receiving a user query, HealthGenie performs query refinement and retrieves relevant information from a pre-built KG. The system then visualizes and highlights pertinent information, organized by defined categories, while offering detailed, explainable recommendation rationales. Users can further tailor these recommendations by adjusting preferences interactively. Our evaluation, comprising a within-subject comparative experiment and an open-ended discussion, demonstrates that HealthGenie effectively supports users in obtaining personalized dietary guidance based on their health conditions while reducing interaction effort and cognitive load. These findings highlight the potential of LLM-KG integration in supporting decision-making through explainable and visualized information. We examine the system's usefulness and effectiveness with an N=12 within-subject study and provide design considerations for future systems that integrate conversational LLM and KG.
Recover from Horcrux: A Spectrogram Augmentation Method for Cardiac Feature Monitoring from Radar Signal Components
Mar 25, 2025Radar-based wellness monitoring is becoming an effective measurement to provide accurate vital signs in a contactless manner, but data scarcity retards the related research on deep-learning-based methods. Data augmentation is commonly used to enrich the dataset by modifying the existing data, but most augmentation techniques can only couple with classification tasks. To enable the augmentation for regression tasks, this research proposes a spectrogram augmentation method, Horcrux, for radar-based cardiac feature monitoring (e.g., heartbeat detection, electrocardiogram reconstruction) with both classification and regression tasks involved. The proposed method is designed to increase the diversity of input samples while the augmented spectrogram is still faithful to the original ground truth vital sign. In addition, Horcrux proposes to inject zero values in specific areas to enhance the awareness of the deep learning model on subtle cardiac features, improving the performance for the limited dataset. Experimental result shows that Horcrux achieves an overall improvement of 16.20% in cardiac monitoring and has the potential to be extended to other spectrogram-based tasks. The code will be released upon publication.
MKG-Rank: Enhancing Large Language Models with Knowledge Graph for Multilingual Medical Question Answering
Mar 21, 2025Large Language Models (LLMs) have shown remarkable progress in medical question answering (QA), yet their effectiveness remains predominantly limited to English due to imbalanced multilingual training data and scarce medical resources for low-resource languages. To address this critical language gap in medical QA, we propose Multilingual Knowledge Graph-based Retrieval Ranking (MKG-Rank), a knowledge graph-enhanced framework that enables English-centric LLMs to perform multilingual medical QA. Through a word-level translation mechanism, our framework efficiently integrates comprehensive English-centric medical knowledge graphs into LLM reasoning at a low cost, mitigating cross-lingual semantic distortion and achieving precise medical QA across language barriers. To enhance efficiency, we introduce caching and multi-angle ranking strategies to optimize the retrieval process, significantly reducing response times and prioritizing relevant medical knowledge. Extensive evaluations on multilingual medical QA benchmarks across Chinese, Japanese, Korean, and Swahili demonstrate that MKG-Rank consistently outperforms zero-shot LLMs, achieving maximum 35.03% increase in accuracy, while maintaining an average retrieval time of only 0.0009 seconds.
Enabling Inclusive Systematic Reviews: Incorporating Preprint Articles with Large Language Model-Driven Evaluations
Mar 19, 2025Background. Systematic reviews in comparative effectiveness research require timely evidence synthesis. Preprints accelerate knowledge dissemination but vary in quality, posing challenges for systematic reviews. Methods. We propose AutoConfidence (automated confidence assessment), an advanced framework for predicting preprint publication, which reduces reliance on manual curation and expands the range of predictors, including three key advancements: (1) automated data extraction using natural language processing techniques, (2) semantic embeddings of titles and abstracts, and (3) large language model (LLM)-driven evaluation scores. Additionally, we employed two prediction models: a random forest classifier for binary outcome and a survival cure model that predicts both binary outcome and publication risk over time. Results. The random forest classifier achieved AUROC 0.692 with LLM-driven scores, improving to 0.733 with semantic embeddings and 0.747 with article usage metrics. The survival cure model reached AUROC 0.716 with LLM-driven scores, improving to 0.731 with semantic embeddings. For publication risk prediction, it achieved a concordance index of 0.658, increasing to 0.667 with semantic embeddings. Conclusion. Our study advances the framework for preprint publication prediction through automated data extraction and multiple feature integration. By combining semantic embeddings with LLM-driven evaluations, AutoConfidence enhances predictive performance while reducing manual annotation burden. The framework has the potential to facilitate systematic incorporation of preprint articles in evidence-based medicine, supporting researchers in more effective evaluation and utilization of preprint resources.
MMLU-ProX: A Multilingual Benchmark for Advanced Large Language Model Evaluation
Mar 13, 2025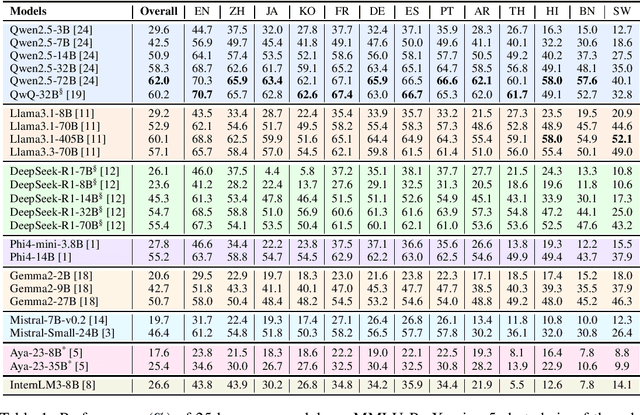
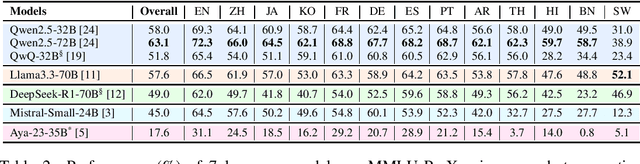
Traditional benchmarks struggle to evaluate increasingly sophisticated language models in multilingual and culturally diverse contexts. To address this gap, we introduce MMLU-ProX, a comprehensive multilingual benchmark covering 13 typologically diverse languages with approximately 11,829 questions per language. Building on the challenging reasoning-focused design of MMLU-Pro, our framework employs a semi-automatic translation process: translations generated by state-of-the-art large language models (LLMs) are rigorously evaluated by expert annotators to ensure conceptual accuracy, terminological consistency, and cultural relevance. We comprehensively evaluate 25 state-of-the-art LLMs using 5-shot chain-of-thought (CoT) and zero-shot prompting strategies, analyzing their performance across linguistic and cultural boundaries. Our experiments reveal consistent performance degradation from high-resource languages to lower-resource ones, with the best models achieving over 70% accuracy on English but dropping to around 40% for languages like Swahili, highlighting persistent gaps in multilingual capabilities despite recent advances. MMLU-ProX is an ongoing project; we are expanding our benchmark by incorporating additional languages and evaluating more language models to provide a more comprehensive assessment of multilingual capabilities.
ReAgent: Reversible Multi-Agent Reasoning for Knowledge-Enhanced Multi-Hop QA
Mar 10, 2025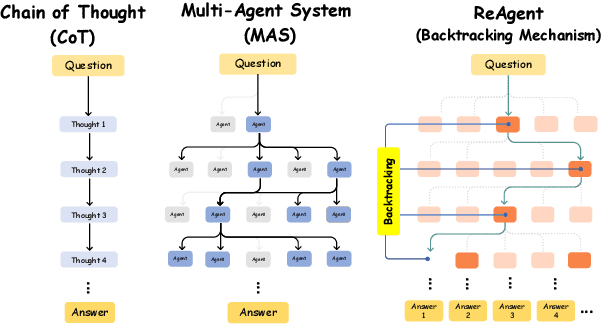
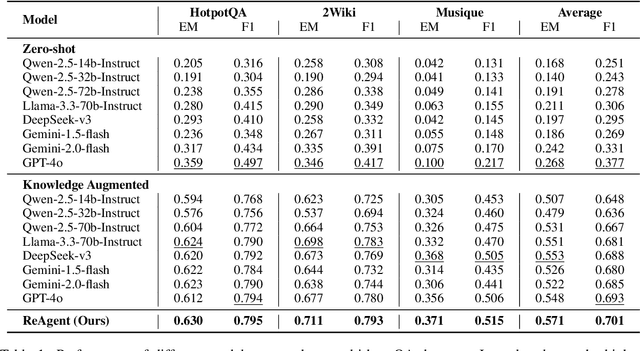
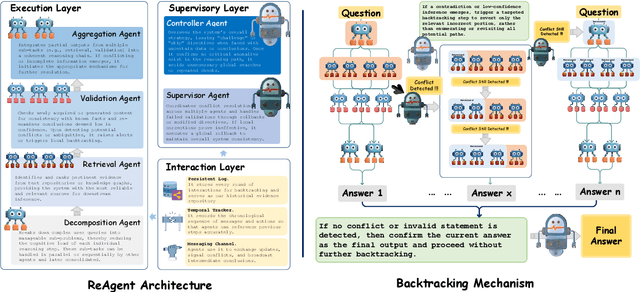
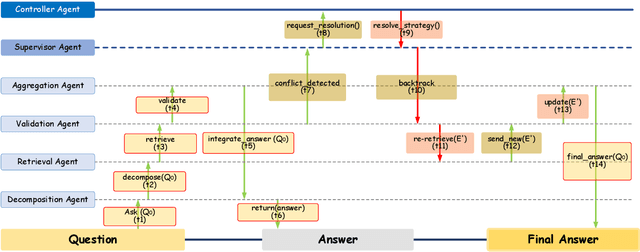
Recent advances in large language models (LLMs) have significantly improved multi-hop question answering (QA) through direct Chain-of-Thought (CoT) reasoning. However, the irreversible nature of CoT leads to error accumulation, making it challenging to correct mistakes in multi-hop reasoning. This paper introduces ReAgent: a Reversible multi-Agent collaborative framework augmented with explicit backtracking mechanisms, enabling reversible multi-hop reasoning. By incorporating text-based retrieval, information aggregation and validation, our system can detect and correct errors mid-reasoning, leading to more robust and interpretable QA outcomes. The framework and experiments serve as a foundation for future work on error-tolerant QA systems. Empirical evaluations across three benchmarks indicate ReAgent's efficacy, yielding average about 6\% improvements against baseline models.