 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan LLM Agents Respond to Disasters? Benchmarking Heterogeneous Geospatial Reasoning in Emergency Operations
May 12, 2026Operational disaster response goes beyond damage assessment, requiring responders to integrate multi-sensor signals, reason over road networks, populations and key facilities, plan evacuations, and produce actionable reports. However, prior work largely isolates remote-sensing perception or evaluates generic tool use, leaving the end-to-end workflows of emergency operations underexplored. In this paper, we introduce Disaster Operational Response Agent benchmark (DORA), the first agentic benchmark for end-to-end disaster response: 515 expert-authored tasks across 45 real-world disaster events spanning 10 types, paired with expert-verified, replayable gold trajectories totaling 3,500 tool-call steps. Tasks span five dimensions that cover the operational disaster-response pipeline: disaster perception, spatial relational analysis, rescue and evacuation planning, temporal evolution reasoning, and multi-modal report synthesis. Agents compose calls from a 108-tool MCP library over heterogeneous geospatial data: optical, SAR, and multi-spectral imagery across single-, bi-, and multi-temporal sequences (0.015-10m GSD), complemented by elevation and social vector layers. We comprehensively evaluate 13 frontier LLMs on our benchmark, revealing three persistent challenges: 1) disaster-domain grounding exposes unique failure modes (damage-semantic grounding, sensor-modality mismatch, and disaster-pipeline composition); 2) agents are doubly bottlenecked by tool selection and argument grounding, where gold tool-order hints improve accuracy by only 1.08-4.40%, and alternative scaffolds yield at most a 3.24% gain; 3) compositional fragility scales with trajectory length, the agent-to-gold gap widening from 7% to 56% on long pipelines. DORA establishes a rigorous testbed for operationally reliable disaster-response agents.
Code-Switching Information Retrieval: Benchmarks, Analysis, and the Limits of Current Retrievers
Apr 19, 2026Code-switching is a pervasive linguistic phenomenon in global communication, yet modern information retrieval systems remain predominantly designed for, and evaluated within, monolingual contexts. To bridge this critical disconnect, we present a holistic study dedicated to code-switching IR. We introduce CSR-L (Code-Switching Retrieval benchmark-Lite), constructing a dataset via human annotation to capture the authentic naturalness of mixed-language queries. Our evaluation across statistical, dense, and late-interaction paradigms reveals that code-switching acts as a fundamental performance bottleneck, degrading the effectiveness of even robust multilingual models. We demonstrate that this failure stems from substantial divergence in the embedding space between pure and code-switched text. Scaling this investigation, we propose CS-MTEB, a comprehensive benchmark covering 11 diverse tasks, where we observe performance declines of up to 27%. Finally, we show that standard multilingual techniques like vocabulary expansion are insufficient to resolve these deficits completely. These findings underscore the fragility of current systems and establish code-switching as a crucial frontier for future IR optimization.
The Confidence Dichotomy: Analyzing and Mitigating Miscalibration in Tool-Use Agents
Jan 12, 2026Autonomous agents based on large language models (LLMs) are rapidly evolving to handle multi-turn tasks, but ensuring their trustworthiness remains a critical challenge. A fundamental pillar of this trustworthiness is calibration, which refers to an agent's ability to express confidence that reliably reflects its actual performance. While calibration is well-established for static models, its dynamics in tool-integrated agentic workflows remain underexplored. In this work, we systematically investigate verbalized calibration in tool-use agents, revealing a fundamental confidence dichotomy driven by tool type. Specifically, our pilot study identifies that evidence tools (e.g., web search) systematically induce severe overconfidence due to inherent noise in retrieved information, while verification tools (e.g., code interpreters) can ground reasoning through deterministic feedback and mitigate miscalibration. To robustly improve calibration across tool types, we propose a reinforcement learning (RL) fine-tuning framework that jointly optimizes task accuracy and calibration, supported by a holistic benchmark of reward designs. We demonstrate that our trained agents not only achieve superior calibration but also exhibit robust generalization from local training environments to noisy web settings and to distinct domains such as mathematical reasoning. Our results highlight the necessity of domain-specific calibration strategies for tool-use agents. More broadly, this work establishes a foundation for building self-aware agents that can reliably communicate uncertainty in high-stakes, real-world deployments.
Toward Global Large Language Models in Medicine
Jan 05, 2026Despite continuous advances in medical technology, the global distribution of health care resources remains uneven. The development of large language models (LLMs) has transformed the landscape of medicine and holds promise for improving health care quality and expanding access to medical information globally. However, existing LLMs are primarily trained on high-resource languages, limiting their applicability in global medical scenarios. To address this gap, we constructed GlobMed, a large multilingual medical dataset, containing over 500,000 entries spanning 12 languages, including four low-resource languages. Building on this, we established GlobMed-Bench, which systematically assesses 56 state-of-the-art proprietary and open-weight LLMs across multiple multilingual medical tasks, revealing significant performance disparities across languages, particularly for low-resource languages. Additionally, we introduced GlobMed-LLMs, a suite of multilingual medical LLMs trained on GlobMed, with parameters ranging from 1.7B to 8B. GlobMed-LLMs achieved an average performance improvement of over 40% relative to baseline models, with a more than threefold increase in performance on low-resource languages. Together, these resources provide an important foundation for advancing the equitable development and application of LLMs globally, enabling broader language communities to benefit from technological advances.
DisasterM3: A Remote Sensing Vision-Language Dataset for Disaster Damage Assessment and Response
May 27, 2025Large vision-language models (VLMs) have made great achievements in Earth vision. However, complex disaster scenes with diverse disaster types, geographic regions, and satellite sensors have posed new challenges for VLM applications. To fill this gap, we curate a remote sensing vision-language dataset (DisasterM3) for global-scale disaster assessment and response. DisasterM3 includes 26,988 bi-temporal satellite images and 123k instruction pairs across 5 continents, with three characteristics: 1) Multi-hazard: DisasterM3 involves 36 historical disaster events with significant impacts, which are categorized into 10 common natural and man-made disasters. 2)Multi-sensor: Extreme weather during disasters often hinders optical sensor imaging, making it necessary to combine Synthetic Aperture Radar (SAR) imagery for post-disaster scenes. 3) Multi-task: Based on real-world scenarios, DisasterM3 includes 9 disaster-related visual perception and reasoning tasks, harnessing the full potential of VLM's reasoning ability with progressing from disaster-bearing body recognition to structural damage assessment and object relational reasoning, culminating in the generation of long-form disaster reports. We extensively evaluated 14 generic and remote sensing VLMs on our benchmark, revealing that state-of-the-art models struggle with the disaster tasks, largely due to the lack of a disaster-specific corpus, cross-sensor gap, and damage object counting insensitivity. Focusing on these issues, we fine-tune four VLMs using our dataset and achieve stable improvements across all tasks, with robust cross-sensor and cross-disaster generalization capabilities.
DynamicVL: Benchmarking Multimodal Large Language Models for Dynamic City Understanding
May 27, 2025Multimodal large language models have demonstrated remarkable capabilities in visual understanding, but their application to long-term Earth observation analysis remains limited, primarily focusing on single-temporal or bi-temporal imagery. To address this gap, we introduce DVL-Suite, a comprehensive framework for analyzing long-term urban dynamics through remote sensing imagery. Our suite comprises 15,063 high-resolution (1.0m) multi-temporal images spanning 42 megacities in the U.S. from 2005 to 2023, organized into two components: DVL-Bench and DVL-Instruct. The DVL-Bench includes seven urban understanding tasks, from fundamental change detection (pixel-level) to quantitative analyses (regional-level) and comprehensive urban narratives (scene-level), capturing diverse urban dynamics including expansion/transformation patterns, disaster assessment, and environmental challenges. We evaluate 17 state-of-the-art multimodal large language models and reveal their limitations in long-term temporal understanding and quantitative analysis. These challenges motivate the creation of DVL-Instruct, a specialized instruction-tuning dataset designed to enhance models' capabilities in multi-temporal Earth observation. Building upon this dataset, we develop DVLChat, a baseline model capable of both image-level question-answering and pixel-level segmentation, facilitating a comprehensive understanding of city dynamics through language interactions.
Seeing is Believing, but How Much? A Comprehensive Analysis of Verbalized Calibration in Vision-Language Models
May 26, 2025Uncertainty quantification is essential for assessing the reliability and trustworthiness of modern AI systems. Among existing approaches, verbalized uncertainty, where models express their confidence through natural language, has emerged as a lightweight and interpretable solution in large language models (LLMs). However, its effectiveness in vision-language models (VLMs) remains insufficiently studied. In this work, we conduct a comprehensive evaluation of verbalized confidence in VLMs, spanning three model categories, four task domains, and three evaluation scenarios. Our results show that current VLMs often display notable miscalibration across diverse tasks and settings. Notably, visual reasoning models (i.e., thinking with images) consistently exhibit better calibration, suggesting that modality-specific reasoning is critical for reliable uncertainty estimation. To further address calibration challenges, we introduce Visual Confidence-Aware Prompting, a two-stage prompting strategy that improves confidence alignment in multimodal settings. Overall, our study highlights the inherent miscalibration in VLMs across modalities. More broadly, our findings underscore the fundamental importance of modality alignment and model faithfulness in advancing reliable multimodal systems.
MMLU-ProX: A Multilingual Benchmark for Advanced Large Language Model Evaluation
Mar 13, 2025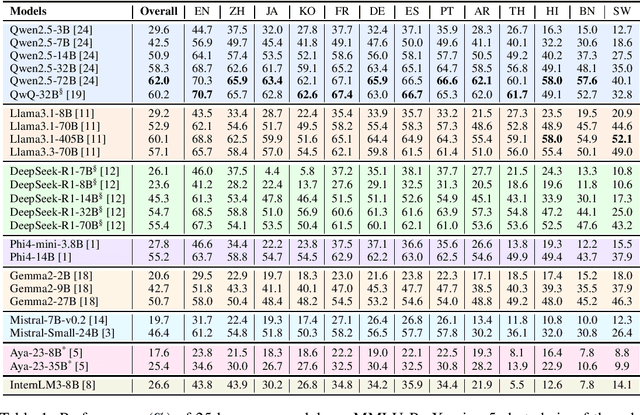
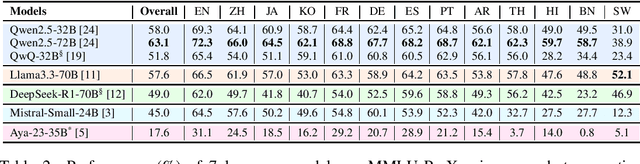
Traditional benchmarks struggle to evaluate increasingly sophisticated language models in multilingual and culturally diverse contexts. To address this gap, we introduce MMLU-ProX, a comprehensive multilingual benchmark covering 13 typologically diverse languages with approximately 11,829 questions per language. Building on the challenging reasoning-focused design of MMLU-Pro, our framework employs a semi-automatic translation process: translations generated by state-of-the-art large language models (LLMs) are rigorously evaluated by expert annotators to ensure conceptual accuracy, terminological consistency, and cultural relevance. We comprehensively evaluate 25 state-of-the-art LLMs using 5-shot chain-of-thought (CoT) and zero-shot prompting strategies, analyzing their performance across linguistic and cultural boundaries. Our experiments reveal consistent performance degradation from high-resource languages to lower-resource ones, with the best models achieving over 70% accuracy on English but dropping to around 40% for languages like Swahili, highlighting persistent gaps in multilingual capabilities despite recent advances. MMLU-ProX is an ongoing project; we are expanding our benchmark by incorporating additional languages and evaluating more language models to provide a more comprehensive assessment of multilingual capabilities.
Segment Anything with Multiple Modalities
Aug 17, 2024



Robust and accurate segmentation of scenes has become one core functionality in various visual recognition and navigation tasks. This has inspired the recent development of Segment Anything Model (SAM), a foundation model for general mask segmentation. However, SAM is largely tailored for single-modal RGB images, limiting its applicability to multi-modal data captured with widely-adopted sensor suites, such as LiDAR plus RGB, depth plus RGB, thermal plus RGB, etc. We develop MM-SAM, an extension and expansion of SAM that supports cross-modal and multi-modal processing for robust and enhanced segmentation with different sensor suites. MM-SAM features two key designs, namely, unsupervised cross-modal transfer and weakly-supervised multi-modal fusion, enabling label-efficient and parameter-efficient adaptation toward various sensor modalities. It addresses three main challenges: 1) adaptation toward diverse non-RGB sensors for single-modal processing, 2) synergistic processing of multi-modal data via sensor fusion, and 3) mask-free training for different downstream tasks. Extensive experiments show that MM-SAM consistently outperforms SAM by large margins, demonstrating its effectiveness and robustness across various sensors and data modalities.
CAT-SAM: Conditional Tuning Network for Few-Shot Adaptation of Segmentation Anything Model
Feb 06, 2024



The recent Segment Anything Model (SAM) has demonstrated remarkable zero-shot capability and flexible geometric prompting in general image segmentation. However, SAM often struggles when handling various unconventional images, such as aerial, medical, and non-RGB images. This paper presents CAT-SAM, a ConditionAl Tuning network that adapts SAM toward various unconventional target tasks with just few-shot target samples. CAT-SAM freezes the entire SAM and adapts its mask decoder and image encoder simultaneously with a small number of learnable parameters. The core design is a prompt bridge structure that enables decoder-conditioned joint tuning of the heavyweight image encoder and the lightweight mask decoder. The bridging maps the prompt token of the mask decoder to the image encoder, fostering synergic adaptation of the encoder and the decoder with mutual benefits. We develop two representative tuning strategies for the image encoder which leads to two CAT-SAM variants: one injecting learnable prompt tokens in the input space and the other inserting lightweight adapter networks. Extensive experiments over 11 unconventional tasks show that both CAT-SAM variants achieve superior target segmentation performance consistently even under the very challenging one-shot adaptation setup. Project page: \url{https://xiaoaoran.github.io/projects/CAT-SAM}