 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausalVAD: De-confounding End-to-End Autonomous Driving via Causal Intervention
Mar 19, 2026Planning-oriented end-to-end driving models show great promise, yet they fundamentally learn statistical correlations instead of true causal relationships. This vulnerability leads to causal confusion, where models exploit dataset biases as shortcuts, critically harming their reliability and safety in complex scenarios. To address this, we introduce CausalVAD, a de-confounding training framework that leverages causal intervention. At its core, we design the sparse causal intervention scheme (SCIS), a lightweight, plug-and-play module to instantiate the backdoor adjustment theory in neural networks. SCIS constructs a dictionary of prototypes representing latent driving contexts. It then uses this dictionary to intervene on the model's sparse vectorized queries. This step actively eliminates spurious associations induced by confounders, thereby eliminating spurious factors from the representations for downstream tasks. Extensive experiments on benchmarks like nuScenes show CausalVAD achieves state-of-the-art planning accuracy and safety. Furthermore, our method demonstrates superior robustness against both data bias and noisy scenarios configured to induce causal confusion.
DynamicVGGT: Learning Dynamic Point Maps for 4D Scene Reconstruction in Autonomous Driving
Mar 09, 2026Dynamic scene reconstruction in autonomous driving remains a fundamental challenge due to significant temporal variations, moving objects, and complex scene dynamics. Existing feed-forward 3D models have demonstrated strong performance in static reconstruction but still struggle to capture dynamic motion. To address these limitations, we propose DynamicVGGT, a unified feed-forward framework that extends VGGT from static 3D perception to dynamic 4D reconstruction. Our goal is to model point motion within feed-forward 3D models in a dynamic and temporally coherent manner. To this end, we jointly predict the current and future point maps within a shared reference coordinate system, allowing the model to implicitly learn dynamic point representations through temporal correspondence. To efficiently capture temporal dependencies, we introduce a Motion-aware Temporal Attention (MTA) module that learns motion continuity. Furthermore, we design a Dynamic 3D Gaussian Splatting Head that explicitly models point motion by predicting Gaussian velocities using learnable motion tokens under scene flow supervision. It refines dynamic geometry through continuous 3D Gaussian optimization. Extensive experiments on autonomous driving datasets demonstrate that DynamicVGGT significantly outperforms existing methods in reconstruction accuracy, achieving robust feed-forward 4D dynamic scene reconstruction under complex driving scenarios.
Vision-Language Feature Alignment for Road Anomaly Segmentation
Mar 01, 2026Safe autonomous systems in complex environments require robust road anomaly segmentation to identify unknown obstacles. However, existing approaches often rely on pixel-level statistics to determine whether a region appears anomalous. This reliance leads to high false-positive rates on semantically normal background regions such as sky or vegetation, and poor recall of true Out-of-distribution (OOD) instances, thereby posing safety risks for robotic perception and decision-making. To address these challenges, we propose VL-Anomaly, a vision-language anomaly segmentation framework that incorporates semantic priors from pre-trained Vision-Language Models (VLMs). Specifically, we design a prompt learning-driven alignment module that adapts Mask2Forme's visual features to CLIP text embeddings of known categories, effectively suppressing spurious anomaly responses in background regions. At inference time, we further introduce a multi-source inference strategy that integrates text-guided similarity, CLIP-based image-text similarity and detector confidence, enabling more reliable anomaly prediction by leveraging complementary information sources. Extensive experiments demonstrate that VL-Anomaly achieves state-of-the-art performance on benchmark datasets including RoadAnomaly, SMIYC and Fishyscapes.Code is released on https://github.com/NickHezhuolin/VL-aligner-Road-anomaly-segment.
Decoupling Scene Perception and Ego Status: A Multi-Context Fusion Approach for Enhanced Generalization in End-to-End Autonomous Driving
Nov 18, 2025



Modular design of planning-oriented autonomous driving has markedly advanced end-to-end systems. However, existing architectures remain constrained by an over-reliance on ego status, hindering generalization and robust scene understanding. We identify the root cause as an inherent design within these architectures that allows ego status to be easily leveraged as a shortcut. Specifically, the premature fusion of ego status in the upstream BEV encoder allows an information flow from this strong prior to dominate the downstream planning module. To address this challenge, we propose AdaptiveAD, an architectural-level solution based on a multi-context fusion strategy. Its core is a dual-branch structure that explicitly decouples scene perception and ego status. One branch performs scene-driven reasoning based on multi-task learning, but with ego status deliberately omitted from the BEV encoder, while the other conducts ego-driven reasoning based solely on the planning task. A scene-aware fusion module then adaptively integrates the complementary decisions from the two branches to form the final planning trajectory. To ensure this decoupling does not compromise multi-task learning, we introduce a path attention mechanism for ego-BEV interaction and add two targeted auxiliary tasks: BEV unidirectional distillation and autoregressive online mapping. Extensive evaluations on the nuScenes dataset demonstrate that AdaptiveAD achieves state-of-the-art open-loop planning performance. Crucially, it significantly mitigates the over-reliance on ego status and exhibits impressive generalization capabilities across diverse scenarios.
ReAgent: Reversible Multi-Agent Reasoning for Knowledge-Enhanced Multi-Hop QA
Mar 10, 2025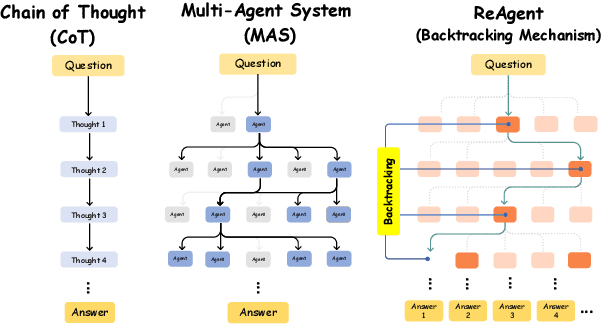
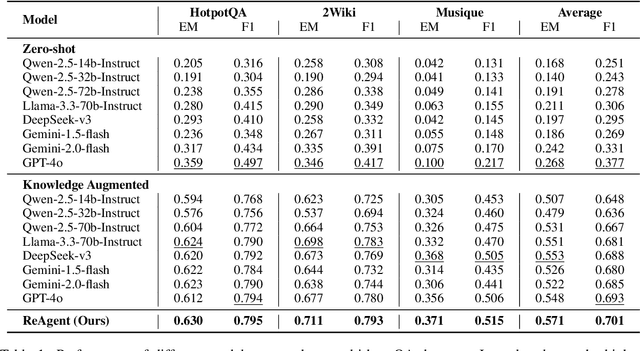
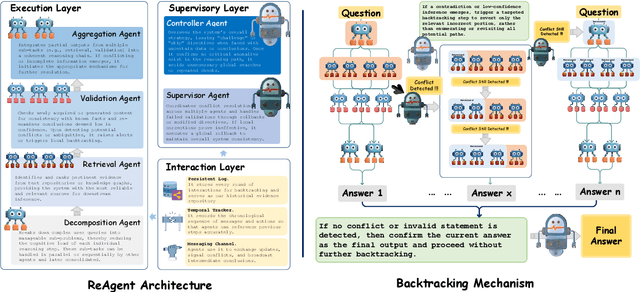
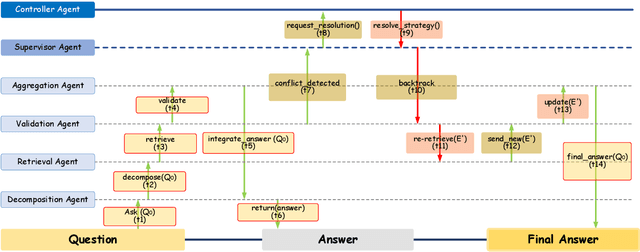
Recent advances in large language models (LLMs) have significantly improved multi-hop question answering (QA) through direct Chain-of-Thought (CoT) reasoning. However, the irreversible nature of CoT leads to error accumulation, making it challenging to correct mistakes in multi-hop reasoning. This paper introduces ReAgent: a Reversible multi-Agent collaborative framework augmented with explicit backtracking mechanisms, enabling reversible multi-hop reasoning. By incorporating text-based retrieval, information aggregation and validation, our system can detect and correct errors mid-reasoning, leading to more robust and interpretable QA outcomes. The framework and experiments serve as a foundation for future work on error-tolerant QA systems. Empirical evaluations across three benchmarks indicate ReAgent's efficacy, yielding average about 6\% improvements against baseline models.
From Metaphor to Mechanism: How LLMs Decode Traditional Chinese Medicine Symbolic Language for Modern Clinical Relevance
Mar 04, 2025Metaphorical expressions are abundant in Traditional Chinese Medicine (TCM), conveying complex disease mechanisms and holistic health concepts through culturally rich and often abstract terminology. Bridging these metaphors to anatomically driven Western medical (WM) concepts poses significant challenges for both automated language processing and real-world clinical practice. To address this gap, we propose a novel multi-agent and chain-of-thought (CoT) framework designed to interpret TCM metaphors accurately and map them to WM pathophysiology. Specifically, our approach combines domain-specialized agents (TCM Expert, WM Expert) with a Coordinator Agent, leveraging stepwise chain-of-thought prompts to ensure transparent reasoning and conflict resolution. We detail a methodology for building a metaphor-rich TCM dataset, discuss strategies for effectively integrating multi-agent collaboration and CoT reasoning, and articulate the theoretical underpinnings that guide metaphor interpretation across distinct medical paradigms. We present a comprehensive system design and highlight both the potential benefits and limitations of our approach, while leaving placeholders for future experimental validation. Our work aims to support clinical decision-making, cross-system educational initiatives, and integrated healthcare research, ultimately offering a robust scaffold for reconciling TCM's symbolic language with the mechanistic focus of Western medicine.
Change Detection of Markov Kernels with Unknown Post Change Kernel using Maximum Mean Discrepancy
Jan 27, 2022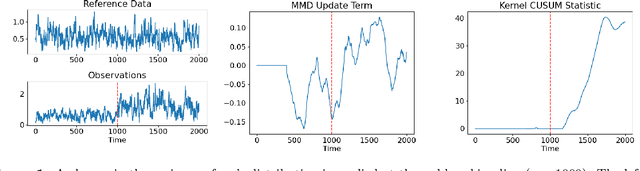
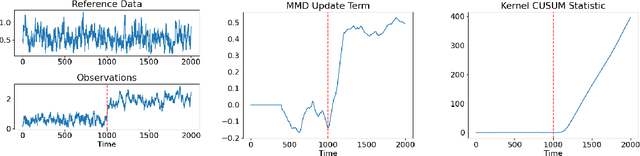
In this paper, we develop a new change detection algorithm for detecting a change in the Markov kernel over a metric space in which the post-change kernel is unknown. Under the assumption that the pre- and post-change Markov kernel is geometrically ergodic, we derive an upper bound on the mean delay and a lower bound on the mean time between false alarms.